 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal2Skill: Long-Horizon Manipulation with Adaptive Planning and Reflection
Apr 15, 2026Recent vision-language-action (VLA) systems have demonstrated strong capabilities in embodied manipulation. However, most existing VLA policies rely on limited observation windows and end-to-end action prediction, which makes them brittle in long-horizon, memory-dependent tasks with partial observability, occlusions, and multi-stage dependencies. Such tasks require not only precise visuomotor control, but also persistent memory, adaptive task decomposition, and explicit recovery from execution failures. To address these limitations, we propose a dual-system framework for long-horizon embodied manipulation. Our framework explicitly separates high-level semantic reasoning from low-level motor execution. A high-level planner, implemented as a VLM-based agentic module, maintains structured task memory and performs goal decomposition, outcome verification, and error-driven correction. A low-level executor, instantiated as a VLA-based visuomotor controller, carries out each sub-task through diffusion-based action generation conditioned on geometry-preserving filtered observations. Together, the two systems form a closed loop between planning and execution, enabling memory-aware reasoning, adaptive replanning, and robust online recovery. Experiments on representative RMBench tasks show that the proposed framework substantially outperforms representative baselines, achieving a 32.4% average success rate compared with 9.8% for the strongest baseline. Ablation studies further confirm the importance of structured memory and closed-loop recovery for long-horizon manipulation.
Context-Aware Transfer Attacks for Object Detection
Dec 06, 2021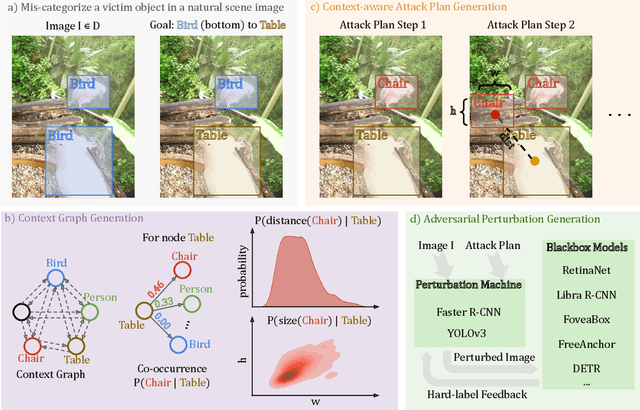
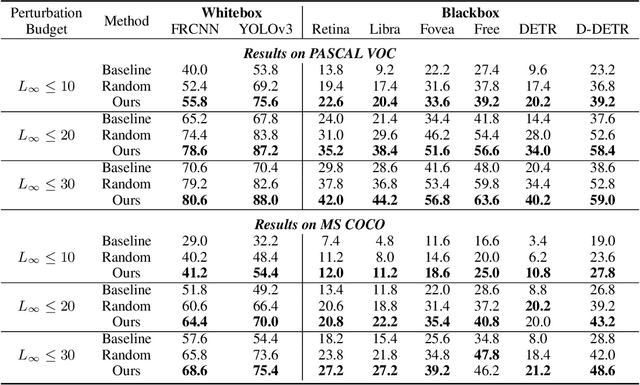

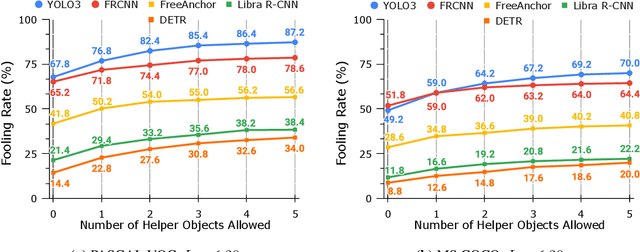
Blackbox transfer attacks for image classifiers have been extensively studied in recent years. In contrast, little progress has been made on transfer attacks for object detectors. Object detectors take a holistic view of the image and the detection of one object (or lack thereof) often depends on other objects in the scene. This makes such detectors inherently context-aware and adversarial attacks in this space are more challenging than those targeting image classifiers. In this paper, we present a new approach to generate context-aware attacks for object detectors. We show that by using co-occurrence of objects and their relative locations and sizes as context information, we can successfully generate targeted mis-categorization attacks that achieve higher transfer success rates on blackbox object detectors than the state-of-the-art. We test our approach on a variety of object detectors with images from PASCAL VOC and MS COCO datasets and demonstrate up to $20$ percentage points improvement in performance compared to the other state-of-the-art methods.