 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Paradoxical Interference between Instruction-Following and Task Solving
Jan 29, 2026Instruction following aims to align Large Language Models (LLMs) with human intent by specifying explicit constraints on how tasks should be performed. However, we reveal a counterintuitive phenomenon: instruction following can paradoxically interfere with LLMs' task-solving capability. We propose a metric, SUSTAINSCORE, to quantify the interference of instruction following with task solving. It measures task performance drop after inserting into the instruction a self-evident constraint, which is naturally met by the original successful model output and extracted from it. Experiments on current LLMs in mathematics, multi-hop QA, and code generation show that adding the self-evident constraints leads to substantial performance drops, even for advanced models such as Claude-Sonnet-4.5. We validate the generality of the interference across constraint types and scales. Furthermore, we identify common failure patterns, and by investigating the mechanisms of interference, we observe that failed cases allocate significantly more attention to constraints compared to successful ones. Finally, we use SUSTAINSCORE to conduct an initial investigation into how distinct post-training paradigms affect the interference, presenting empirical observations on current alignment strategies. We will release our code and data to facilitate further research
Deep Neural Networks for Rank-Consistent Ordinal Regression Based On Conditional Probabilities
Nov 17, 2021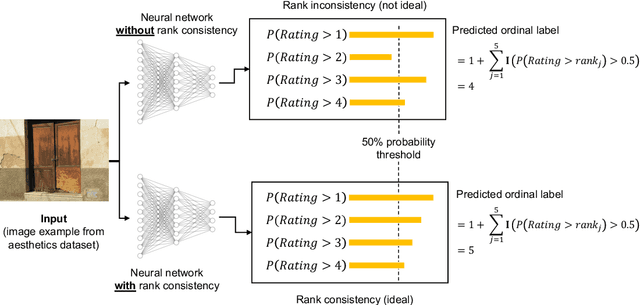
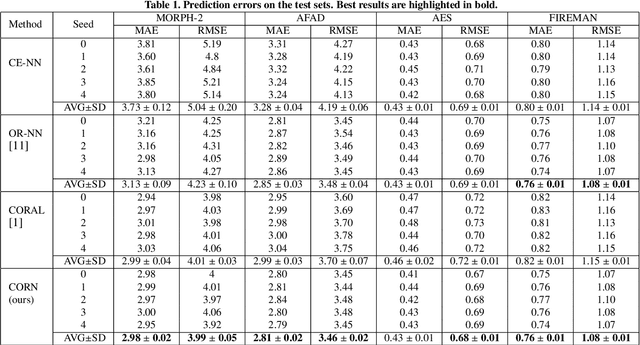
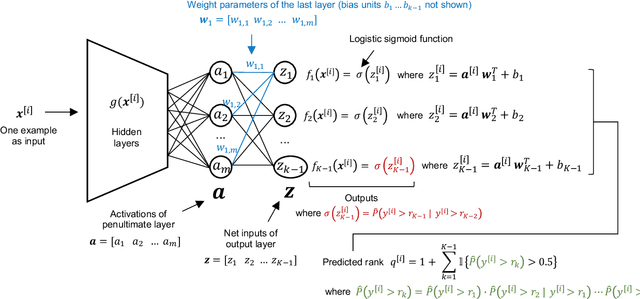
In recent times, deep neural networks achieved outstanding predictive performance on various classification and pattern recognition tasks. However, many real-world prediction problems have ordinal response variables, and this ordering information is ignored by conventional classification losses such as the multi-category cross-entropy. Ordinal regression methods for deep neural networks address this. One such method is the CORAL method, which is based on an earlier binary label extension framework and achieves rank consistency among its output layer tasks by imposing a weight-sharing constraint. However, while earlier experiments showed that CORAL's rank consistency is beneficial for performance, the weight-sharing constraint could severely restrict the expressiveness of a deep neural network. In this paper, we propose an alternative method for rank-consistent ordinal regression that does not require a weight-sharing constraint in a neural network's fully connected output layer. We achieve this rank consistency by a novel training scheme using conditional training sets to obtain the unconditional rank probabilities through applying the chain rule for conditional probability distributions. Experiments on various datasets demonstrate the efficacy of the proposed method to utilize the ordinal target information, and the absence of the weight-sharing restriction improves the performance substantially compared to the CORAL reference approach.