 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoTIR: Accurate Understanding for Long Videos with Efficient Tool-Integrated Reasoning
Mar 26, 2026Existing Multimodal Large Language Models (MLLMs) often suffer from hallucinations in long video understanding (LVU), primarily due to the imbalance between textual and visual tokens. Observing that MLLMs handle short visual inputs well, recent LVU works alleviate hallucinations by automatically parsing the vast visual data into manageable segments that can be effectively processed by MLLMs. SFT-based tool-calling methods can serve this purpose, but they typically require vast amounts of fine-grained, high-quality data and suffer from constrained tool-calling trajectories. We propose a novel VideoTIR that leverages Reinforcement Learning (RL) to encourage proper usage of comprehensive multi-level toolkits for efficient long video understanding. VideoTIR explores both Zero-RL and SFT cold-starting to enable MLLMs to retrieve and focus on meaningful video segments/images/regions, enhancing long video understanding both accurately and efficiently. To reduce redundant tool-calling, we propose Toolkit Action Grouped Policy Optimization (TAGPO), which enhances the efficiency of the calling process through stepwise reward assignment and reuse of failed rollouts. Additionally, we develop a sandbox-based trajectory synthesis framework to generate high-quality trajectories data. Extensive experiments on three long-video QA benchmarks demonstrate the effectiveness and efficiency of our method.
Agent RL Scaling Law: Agent RL with Spontaneous Code Execution for Mathematical Problem Solving
May 14, 2025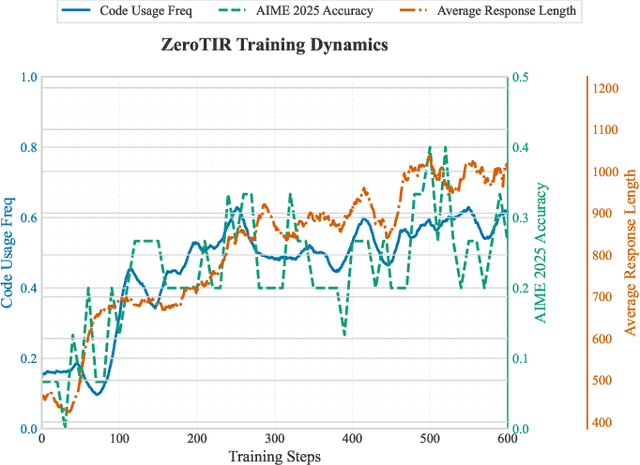
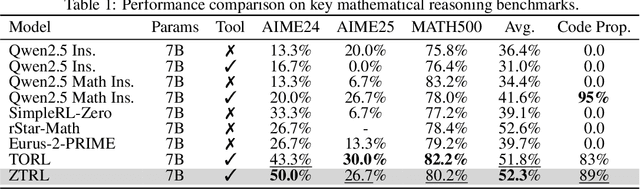

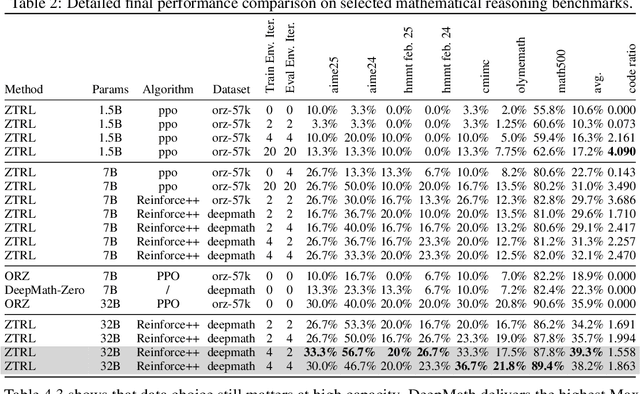
Large Language Models (LLMs) often struggle with mathematical reasoning tasks requiring precise, verifiable computation. While Reinforcement Learning (RL) from outcome-based rewards enhances text-based reasoning, understanding how agents autonomously learn to leverage external tools like code execution remains crucial. We investigate RL from outcome-based rewards for Tool-Integrated Reasoning, ZeroTIR, training base LLMs to spontaneously generate and execute Python code for mathematical problems without supervised tool-use examples. Our central contribution is we demonstrate that as RL training progresses, key metrics scale predictably. Specifically, we observe strong positive correlations where increased training steps lead to increases in the spontaneous code execution frequency, the average response length, and, critically, the final task accuracy. This suggests a quantifiable relationship between computational effort invested in training and the emergence of effective, tool-augmented reasoning strategies. We implement a robust framework featuring a decoupled code execution environment and validate our findings across standard RL algorithms and frameworks. Experiments show ZeroTIR significantly surpasses non-tool ZeroRL baselines on challenging math benchmarks. Our findings provide a foundational understanding of how autonomous tool use is acquired and scales within Agent RL, offering a reproducible benchmark for future studies. Code is released at \href{https://github.com/yyht/openrlhf_async_pipline}{https://github.com/yyht/openrlhf\_async\_pipline}.