 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Evolutionary Multi-Objective Optimization via Learning-to-Rank
Apr 06, 2022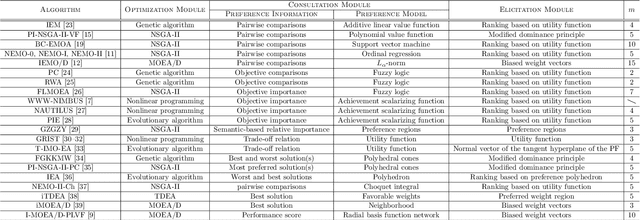
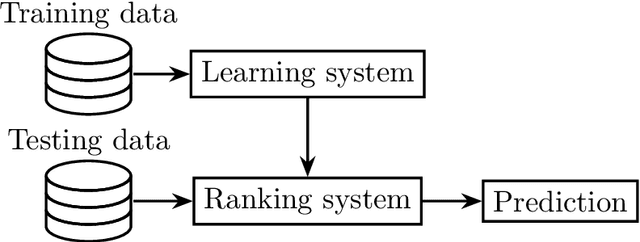
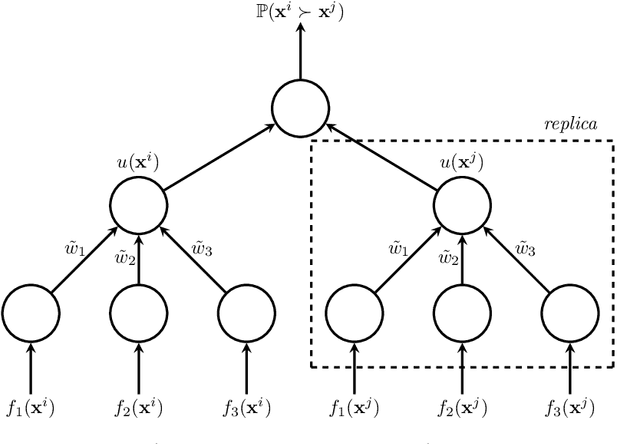
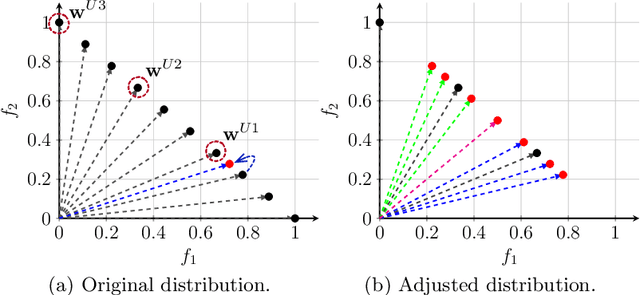
In practical multi-criterion decision-making, it is cumbersome if a decision maker (DM) is asked to choose among a set of trade-off alternatives covering the whole Pareto-optimal front. This is a paradox in conventional evolutionary multi-objective optimization (EMO) that always aim to achieve a well balance between convergence and diversity. In essence, the ultimate goal of multi-objective optimization is to help a decision maker (DM) identify solution(s) of interest (SOI) achieving satisfactory trade-offs among multiple conflicting criteria. Bearing this in mind, this paper develops a framework for designing preference-based EMO algorithms to find SOI in an interactive manner. Its core idea is to involve human in the loop of EMO. After every several iterations, the DM is invited to elicit her feedback with regard to a couple of incumbent candidates. By collecting such information, her preference is progressively learned by a learning-to-rank neural network and then applied to guide the baseline EMO algorithm. Note that this framework is so general that any existing EMO algorithm can be applied in a plug-in manner. Experiments on $48$ benchmark test problems with up to 10 objectives fully demonstrate the effectiveness of our proposed algorithms for finding SOI.
An Efficient Multi-Indicator and Many-Objective Optimization Algorithm based on Two-Archive
Jan 14, 2022
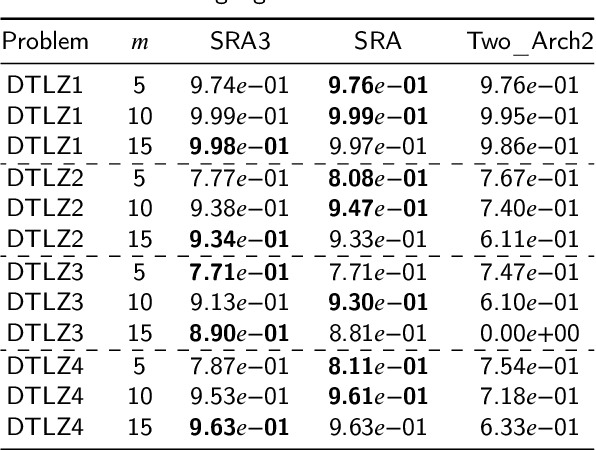
Indicator-based algorithms are gaining prominence as traditional multi-objective optimization algorithms based on domination and decomposition struggle to solve many-objective optimization problems. However, previous indicator-based multi-objective optimization algorithms suffer from the following flaws: 1) The environment selection process takes a long time; 2) Additional parameters are usually necessary. As a result, this paper proposed an multi-indicator and multi-objective optimization algorithm based on two-archive (SRA3) that can efficiently select good individuals in environment selection based on indicators performance and uses an adaptive parameter strategy for parental selection without setting additional parameters. Then we normalized the algorithm and compared its performance before and after normalization, finding that normalization improved the algorithm's performance significantly. We also analyzed how normalizing affected the indicator-based algorithm and observed that the normalized $I_{\epsilon+}$ indicator is better at finding extreme solutions and can reduce the influence of each objective's different extent of contribution to the indicator due to its different scope. However, it also has a preference for extreme solutions, which causes the solution set to converge to the extremes. As a result, we give some suggestions for normalization. Then, on the DTLZ and WFG problems, we conducted experiments on 39 problems with 5, 10, and 15 objectives, and the results show that SRA3 has good convergence and diversity while maintaining high efficiency. Finally, we conducted experiments on the DTLZ and WFG problems with 20 and 25 objectives and found that the algorithm proposed in this paper is more competitive than other algorithms as the number of objectives increases.
Evolutionary Optimization for Proactive and Dynamic Computing Resource Allocation in Open Radio Access Network
Jan 12, 2022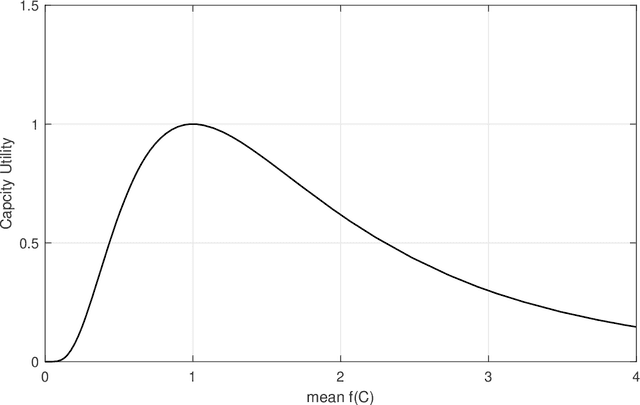
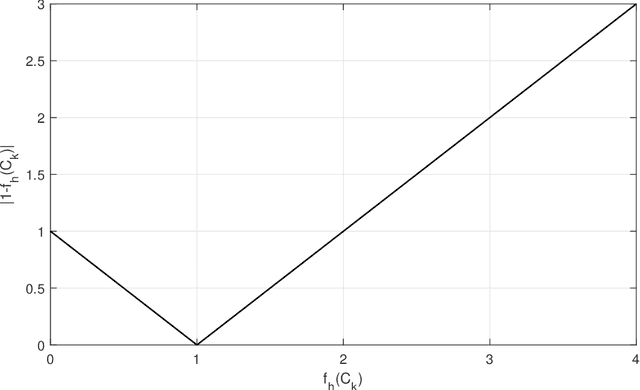
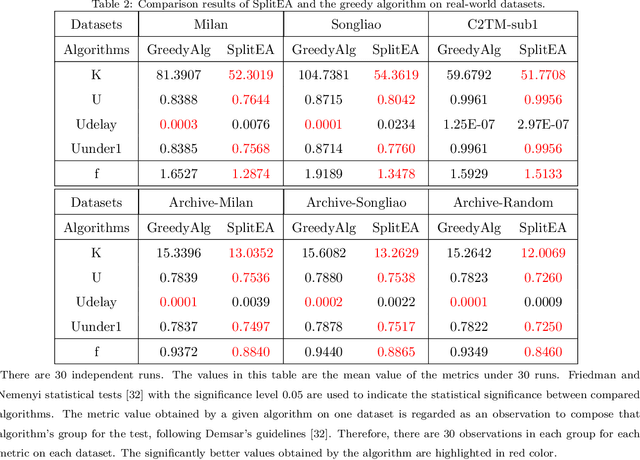
Intelligent techniques are urged to achieve automatic allocation of the computing resource in Open Radio Access Network (O-RAN), to save computing resource, increase utilization rate of them and decrease the delay. However, the existing problem formulation to solve this resource allocation problem is unsuitable as it defines the capacity utility of resource in an inappropriate way and tends to cause much delay. Moreover, the existing problem has only been attempted to be solved based on greedy search, which is not ideal as it could get stuck into local optima. Considering those, a new formulation that better describes the problem is proposed. In addition, as a well-known global search meta heuristic approach, an evolutionary algorithm (EA) is designed tailored for solving the new problem formulation, to find a resource allocation scheme to proactively and dynamically deploy the computing resource for processing upcoming traffic data. Experimental studies carried out on several real-world datasets and newly generated artificial datasets with more properties beyond the real-world datasets have demonstrated the significant superiority over a baseline greedy algorithm under different parameter settings. Moreover, experimental studies are taken to compare the proposed EA and two variants, to indicate the impact of different algorithm choices.
TRIP: Refining Image-to-Image Translation via Rival Preferences
Nov 26, 2021

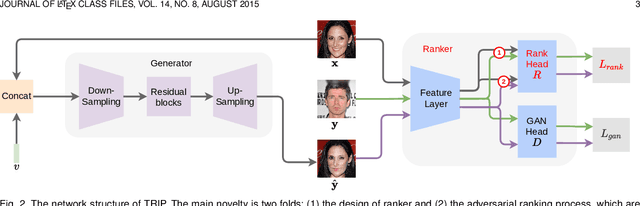
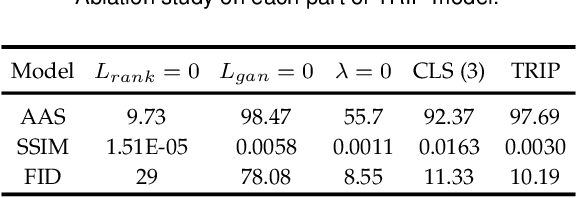
Relative attribute (RA), referring to the preference over two images on the strength of a specific attribute, can enable fine-grained image-to-image translation due to its rich semantic information. Existing work based on RAs however failed to reconcile the goal for fine-grained translation and the goal for high-quality generation. We propose a new model TRIP to coordinate these two goals for high-quality fine-grained translation. In particular, we simultaneously train two modules: a generator that translates an input image to the desired image with smooth subtle changes with respect to the interested attributes; and a ranker that ranks rival preferences consisting of the input image and the desired image. Rival preferences refer to the adversarial ranking process: (1) the ranker thinks no difference between the desired image and the input image in terms of the desired attributes; (2) the generator fools the ranker to believe that the desired image changes the attributes over the input image as desired. RAs over pairs of real images are introduced to guide the ranker to rank image pairs regarding the interested attributes only. With an effective ranker, the generator would "win" the adversarial game by producing high-quality images that present desired changes over the attributes compared to the input image. The experiments on two face image datasets and one shoe image dataset demonstrate that our TRIP achieves state-of-art results in generating high-fidelity images which exhibit smooth changes over the interested attributes.
Hybrid Beamforming for RIS-Aided Communications: Fitness Landscape Analysis and Niching Genetic Algorithm
Sep 19, 2021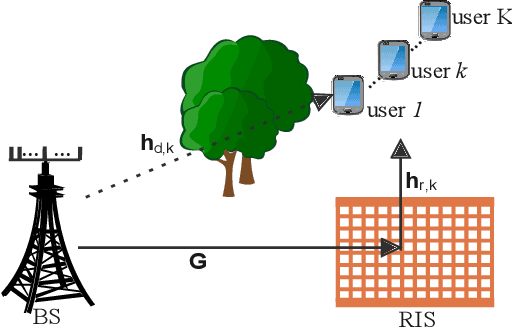
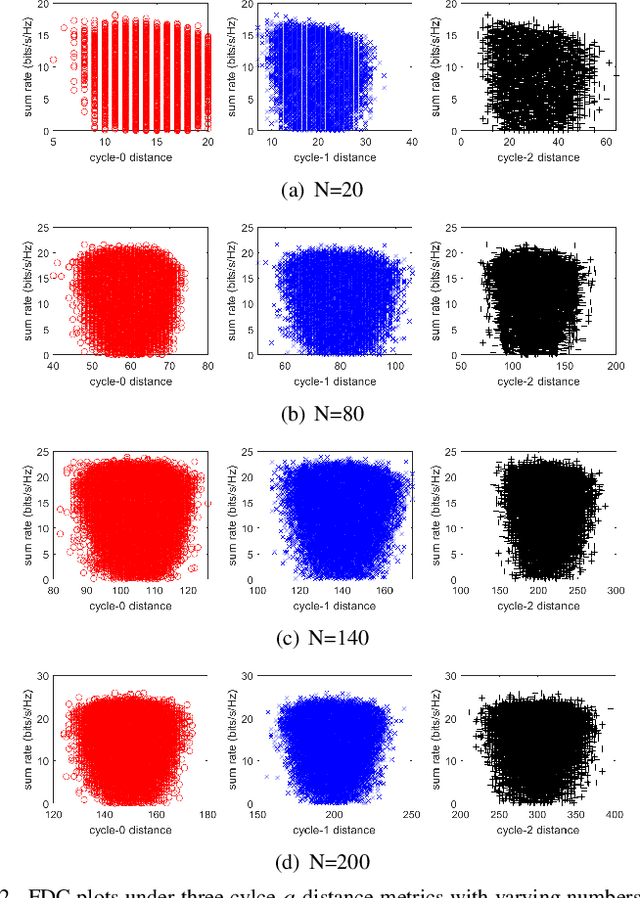

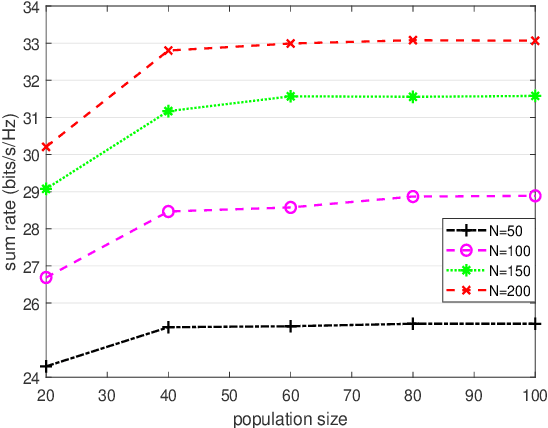
Reconfigurable Intelligent Surface (RIS) is a revolutionizing approach to provide cost-effective yet energy-efficient communications. The transmit beamforming of the base station (BS) and discrete phase shifts of the RIS are jointly optimized to provide high quality of service. However, existing works ignore the high dependence between the large number of phase shifts and estimate them separately, consequently, easily getting trapped into local optima. To investigate the number and distribution of local optima, we conduct a fitness landscape analysis on the sum rate maximization problems. Two landscape features, the fitness distribution correlation and autocorrelation, are employed to investigate the ruggedness of landscape. The investigation results indicate that the landscape exhibits a rugged, multi-modal structure, i.e., has many local peaks, particularly in the cases with large-scale RISs. To handle the multi-modal landscape structure, we propose a novel niching genetic algorithm to solve the sum rate maximization problem. Particularly, a niching technique, nearest-better clustering, is incorporated to partition the population into several neighborhood species, thereby locating multiple local optima and enhance the global search ability. We also present a minimum species size to further improve the convergence speed. Simulation results demonstrate that our method achieves significant capacity gains compared to existing algorithms, particularly in the cases with large-scale RISs.
Lifelong Computing
Aug 19, 2021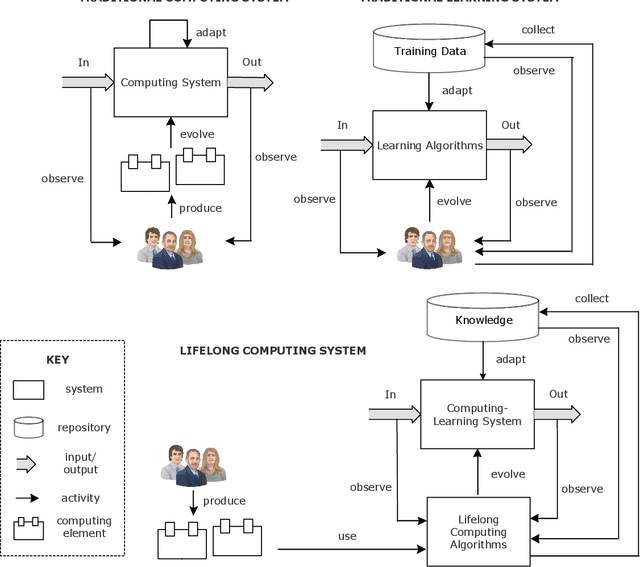
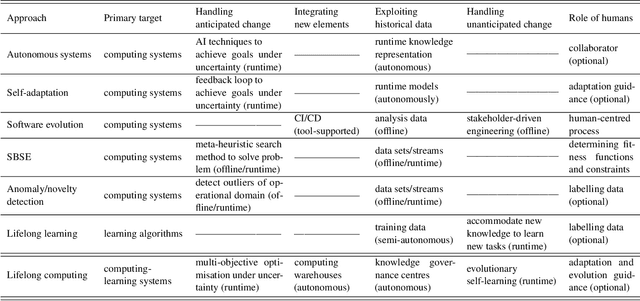
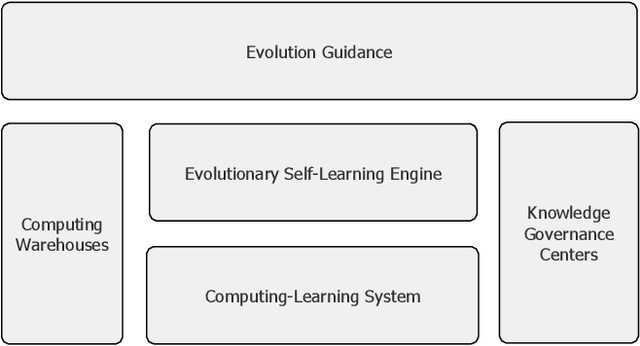
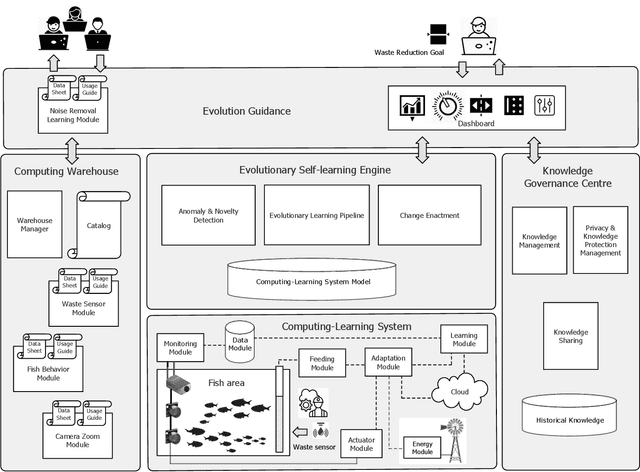
Computing systems form the backbone of many aspects of our life, hence they are becoming as vital as water, electricity, and road infrastructures for our society. Yet, engineering long running computing systems that achieve their goals in ever-changing environments pose significant challenges. Currently, we can build computing systems that adjust or learn over time to match changes that were anticipated. However, dealing with unanticipated changes, such as anomalies, novelties, new goals or constraints, requires system evolution, which remains in essence a human-driven activity. Given the growing complexity of computing systems and the vast amount of highly complex data to process, this approach will eventually become unmanageable. To break through the status quo, we put forward a new paradigm for the design and operation of computing systems that we coin "lifelong computing." The paradigm starts from computing-learning systems that integrate computing/service modules and learning modules. Computing warehouses offer such computing elements together with data sheets and usage guides. When detecting anomalies, novelties, new goals or constraints, a lifelong computing system activates an evolutionary self-learning engine that runs online experiments to determine how the computing-learning system needs to evolve to deal with the changes, thereby changing its architecture and integrating new computing elements from computing warehouses as needed. Depending on the domain at hand, some activities of lifelong computing systems can be supported by humans. We motivate the need for lifelong computing with a future fish farming scenario, outline a blueprint architecture for lifelong computing systems, and highlight key research challenges to realise the vision of lifelong computing.
Generating Large-scale Dynamic Optimization Problem Instances Using the Generalized Moving Peaks Benchmark
Jul 23, 2021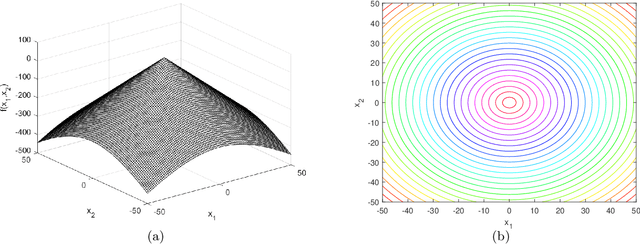

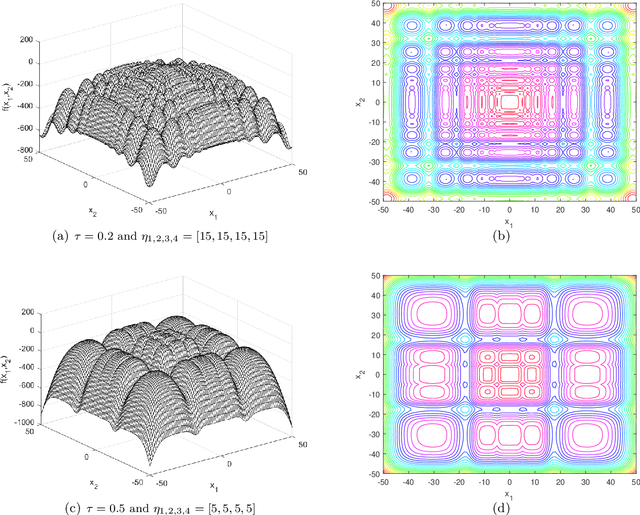

This document describes the generalized moving peaks benchmark (GMPB) and how it can be used to generate problem instances for continuous large-scale dynamic optimization problems. It presents a set of 15 benchmark problems, the relevant source code, and a performance indicator, designed for comparative studies and competitions in large-scale dynamic optimization. Although its primary purpose is to provide a coherent basis for running competitions, its generality allows the interested reader to use this document as a guide to design customized problem instances to investigate issues beyond the scope of the presented benchmark suite. To this end, we explain the modular structure of the GMPB and how its constituents can be assembled to form problem instances with a variety of controllable characteristics ranging from unimodal to highly multimodal, symmetric to highly asymmetric, smooth to highly irregular, and various degrees of variable interaction and ill-conditioning.
Differential-Critic GAN: Generating What You Want by a Cue of Preferences
Jul 14, 2021


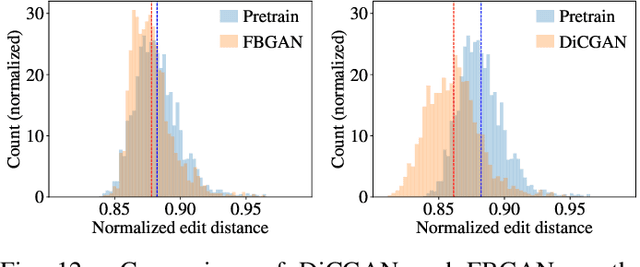
This paper proposes Differential-Critic Generative Adversarial Network (DiCGAN) to learn the distribution of user-desired data when only partial instead of the entire dataset possesses the desired property, which generates desired data that meets user's expectations and can assist in designing biological products with desired properties. Existing approaches select the desired samples first and train regular GANs on the selected samples to derive the user-desired data distribution. However, the selection of the desired data relies on an expert criterion and supervision over the entire dataset. DiCGAN introduces a differential critic that can learn the preference direction from the pairwise preferences, which is amateur knowledge and can be defined on part of the training data. The resultant critic guides the generation of the desired data instead of the whole data. Specifically, apart from the Wasserstein GAN loss, a ranking loss of the pairwise preferences is defined over the critic. It endows the difference of critic values between each pair of samples with the pairwise preference relation. The higher critic value indicates that the sample is preferred by the user. Thus training the generative model for higher critic values encourages the generation of user-preferred samples. Extensive experiments show that our DiCGAN achieves state-of-the-art performance in learning the user-desired data distributions, especially in the cases of insufficient desired data and limited supervision.
Gridless Evolutionary Approach for Line Spectral Estimation with Unknown Model Order
Jun 14, 2021
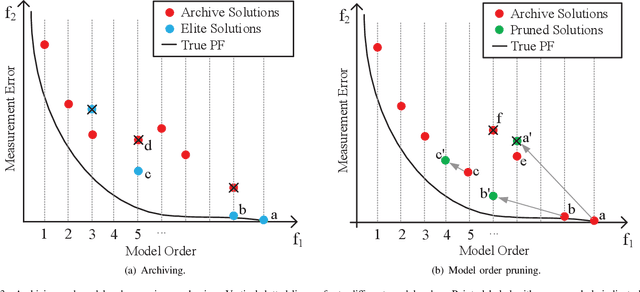
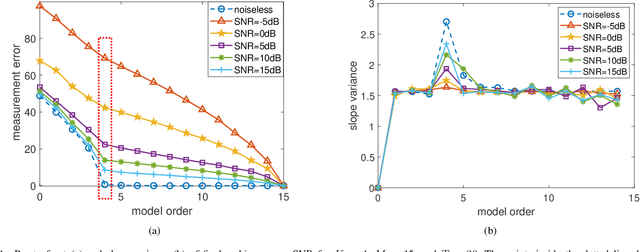
Gridless methods show great superiority in line spectral estimation. These methods need to solve an atomic $l_0$ norm (i.e., the continuous analog of $l_0$ norm) minimization problem to estimate frequencies and model order. Since this problem is NP-hard to compute, relaxations of atomic $l_0$ norm, such as nuclear norm and reweighted atomic norm, have been employed for promoting sparsity. However, the relaxations give rise to a resolution limit, subsequently leading to biased model order and convergence error. To overcome the above shortcomings of relaxation, we propose a novel idea of simultaneously estimating the frequencies and model order by means of the atomic $l_0$ norm. To accomplish this idea, we build a multiobjective optimization model. The measurment error and the atomic $l_0$ norm are taken as the two optimization objectives. The proposed model directly exploits the model order via the atomic $l_0$ norm, thus breaking the resolution limit. We further design a variable-length evolutionary algorithm to solve the proposed model, which includes two innovations. One is a variable-length coding and search strategy. It flexibly codes and interactively searches diverse solutions with different model orders. These solutions act as steppingstones that help fully exploring the variable and open-ended frequency search space and provide extensive potentials towards the optima. Another innovation is a model order pruning mechanism, which heuristically prunes less contributive frequencies within the solutions, thus significantly enhancing convergence and diversity. Simulation results confirm the superiority of our approach in both frequency estimation and model order selection.
Multiobjective Bilevel Evolutionary Approach for Off-Grid Direction-of-Arrival Estimation
Jun 14, 2021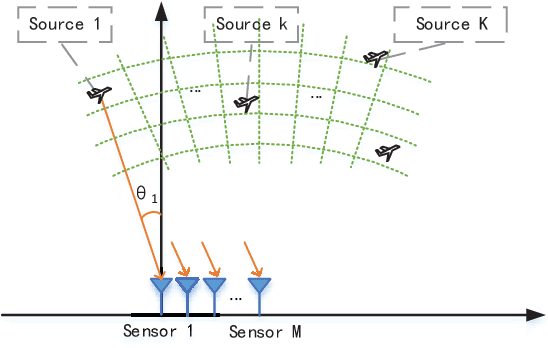

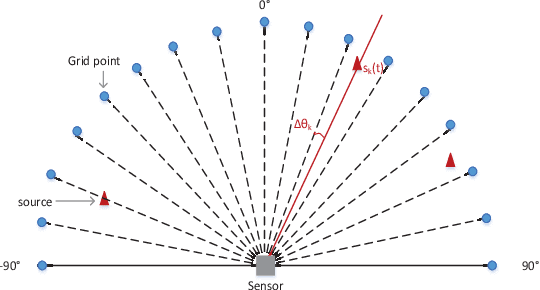
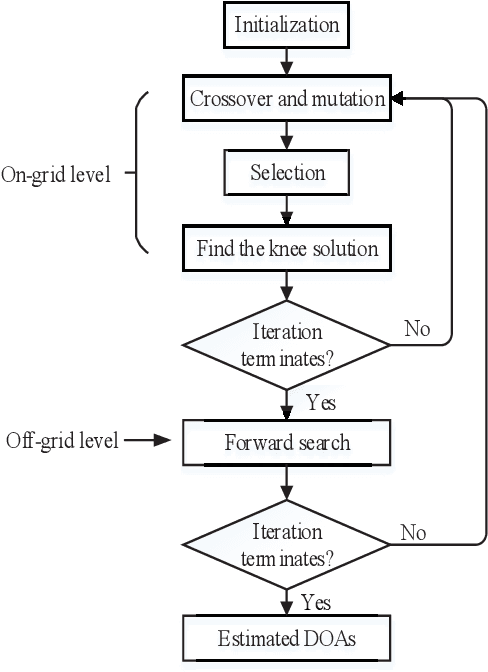
The source number identification is an essential step in direction-of-arrival (DOA) estimation. Existing methods may provide a wrong source number due to inferior statistical properties (in low SNR or limited snapshots) or modeling errors (caused by relaxing sparse penalties), especially in impulsive noise. To address this issue, we propose a novel idea of simultaneous source number identification and DOA estimation. We formulate a multiobjective off-grid DOA estimation model to realize this idea, by which the source number can be automatically identified together with DOA estimation. In particular, the source number is properly exploited by the $l_0$ norm of impinging signals without relaxations, guaranteeing accuracy. Furthermore, we design a multiobjective bilevel evolutionary algorithm to solve the proposed model. The source number identification and sparse recovery are simultaneously optimized at the on-grid (lower) level. A forward search strategy is developed to further refine the grid at the off-grid (upper) level. This strategy does not need linear approximations and can eliminate the off-grid gap with low computational complexity. Simulation results demonstrate the outperformance of our method in terms of source number and root mean square error.