 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshTok: Efficient Multi-Scale Tokenization for Scalable PDE Transformers
Jun 03, 2026Conventional patchified Transformers operate on uniform spatial partitions, distributing computational effort evenly across the domain irrespective of local features. This inflexible tokenization scheme is inherently limited in its ability to efficiently represent and process solutions to complex PDEs. To address this, we propose MeshTok, an adaptive mesh refinement (AMR)-inspired tokenization and sequence modeling framework. This method selectively refines spatial regions exhibiting sharp gradients, transient features, or multiscale structures, generating a heterogeneous set of multiscale tokens defined on a fixed simulation grid. These tokens are processed within a unified Transformer sequence, enabling the model to simultaneously capture coarse-grained global context and fine-grained local details without requiring specialized architectural components. Although adaptive refinement moderately increases token count, it promotes a more targeted allocation of computational resources to physically informative regions, which we view as a practical inductive bias rather than a formal optimality guarantee. Experimental evaluations across multiple PDE families and benchmark datasets demonstrate that MeshTok consistently improves the efficiency-accuracy trade-off compared to uniform-grid baselines. This suggests adaptive multiscale tokenization as a scalable and generalizable design principle for neural PDE modeling. Code is available at https://github.com/SCAILab-USTC/MeshTok.
Personalized Inter-Task Contrastive Learning for CTR&CVR Joint Estimation
Aug 29, 2022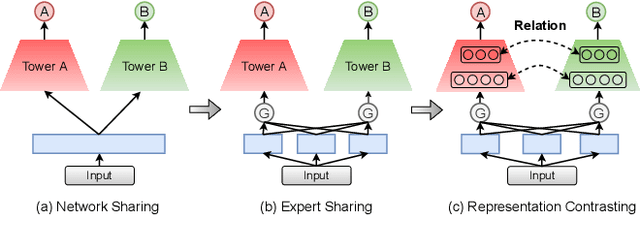

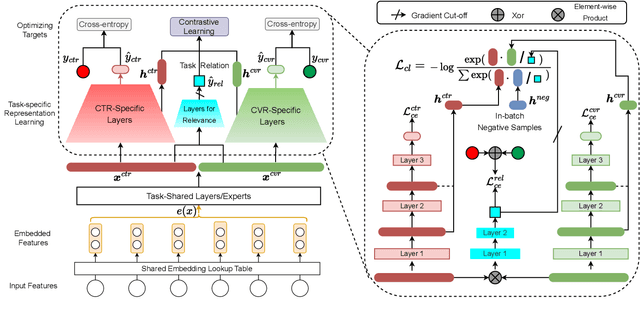
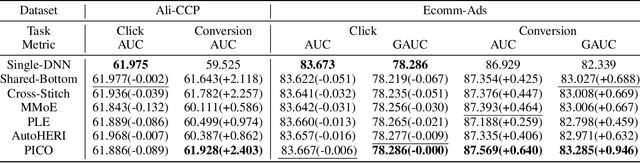
In most of advertising and recommendation systems, multi-task learning (MTL) paradigm is widely employed to model diverse user behaviors (e.g., click, view, and purchase). Existing MTL models typically use task-shared networks with shared parameters or a routing mechanism to learn the commonalities between tasks while applying task-specific networks to learn the unique characteristics of each task. However, the potential relevance within task-specific networks is ignored, which is intuitively crucial for overall performance. In light of the fact that relevance is both task-complex and instance-specific, we present a novel learning paradigm to address these issues. In this paper, we propose Personalized Inter-task COntrastive Learning (PICO) framework, which can effectively model the inter-task relationship and is utilized to jointly estimate the click-through rate (CTR) and post-click conversion rate (CVR) in advertising systems. PICO utilizes contrastive learning to integrate inter-task knowledge implicitly from the task representations in task-specific networks. In addition, we introduce an auxiliary network to capture the inter-task relevance at instance-level and transform it into personalized temperature parameters for contrastive learning. With this method, fine-grained knowledge can be transferred to improve MTL performance without incurring additional inference costs. Both offline and online experiments show that PICO outperforms previous multi-task models significantly.
AdaSparse: Learning Adaptively Sparse Structures for Multi-Domain Click-Through Rate Prediction
Jul 01, 2022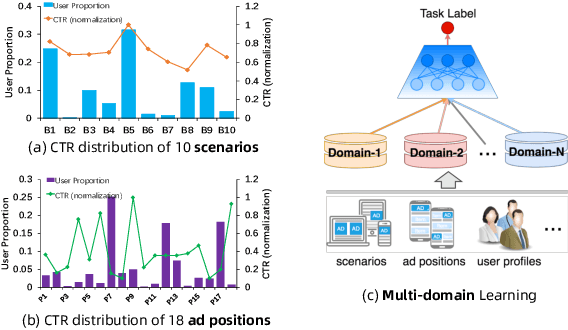
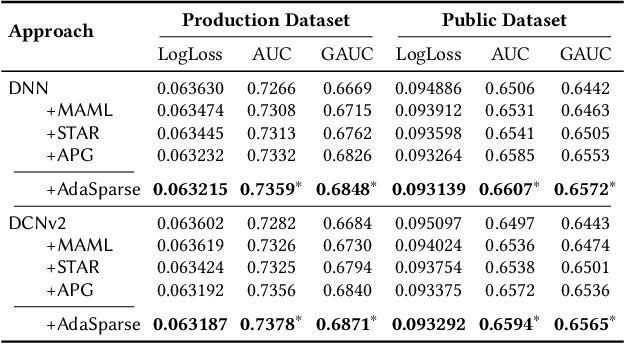
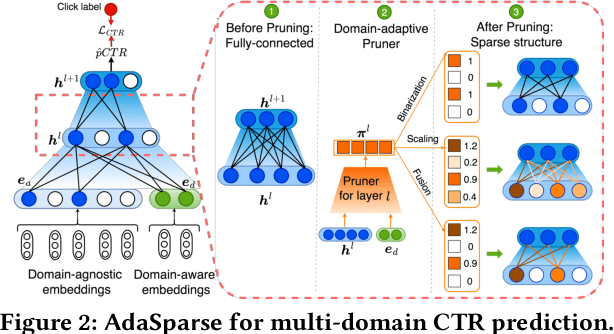

Click-through rate (CTR) prediction is a fundamental technique in recommendation and advertising systems. Recent studies have proved that learning a unified model to serve multiple domains is effective to improve the overall performance. However, it is still challenging to improve generalization across domains under limited training data, and hard to deploy current solutions due to their computational complexity. In this paper, we propose a simple yet effective framework AdaSparse for multi-domain CTR prediction, which learns adaptively sparse structure for each domain, achieving better generalization across domains with lower computational cost. In AdaSparse, we introduce domain-aware neuron-level weighting factors to measure the importance of neurons, with that for each domain our model can prune redundant neurons to improve generalization. We further add flexible sparsity regularizations to control the sparsity ratio of learned structures. Offline and online experiments show that AdaSparse outperforms previous multi-domain CTR models significantly.