 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Face Mask Presentation Attack Detection Based on Intrinsic Image Analysis
Mar 27, 2019
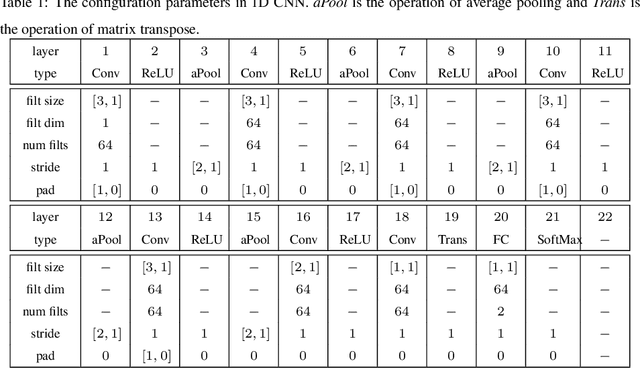
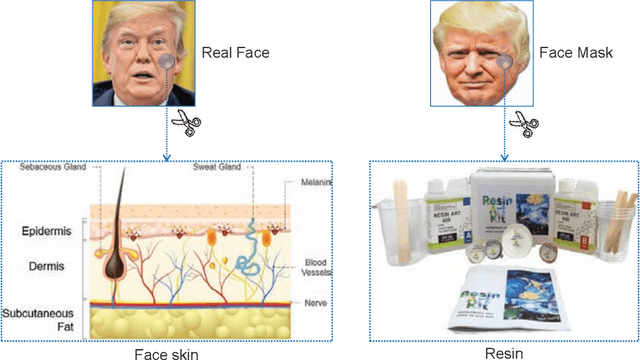
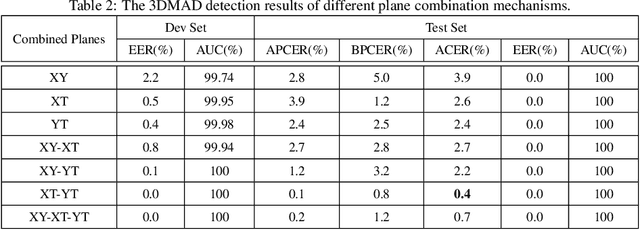
Face presentation attacks have become a major threat to face recognition systems and many countermeasures have been proposed in the past decade. However, most of them are devoted to 2D face presentation attacks, rather than 3D face masks. Unlike the real face, the 3D face mask is usually made of resin materials and has a smooth surface, resulting in reflectance differences. So, we propose a novel detection method for 3D face mask presentation attack by modeling reflectance differences based on intrinsic image analysis. In the proposed method, the face image is first processed with intrinsic image decomposition to compute its reflectance image. Then, the intensity distribution histograms are extracted from three orthogonal planes to represent the intensity differences of reflectance images between the real face and 3D face mask. After that, the 1D convolutional network is further used to capture the information for describing different materials or surfaces react differently to changes in illumination. Extensive experiments on the 3DMAD database demonstrate the effectiveness of our proposed method in distinguishing a face mask from the real one and show that the detection performance outperforms other state-of-the-art methods.
Spatiotemporal Recurrent Convolutional Networks for Recognizing Spontaneous Micro-expressions
Jan 15, 2019
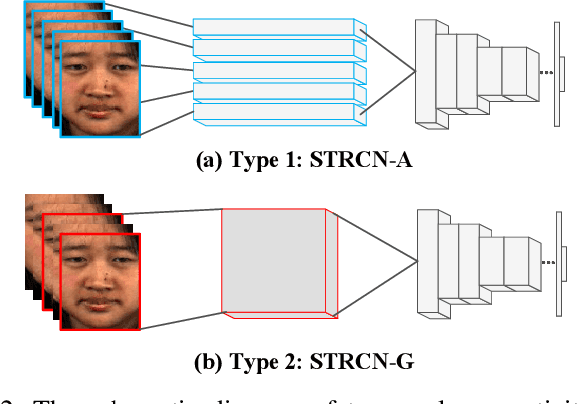
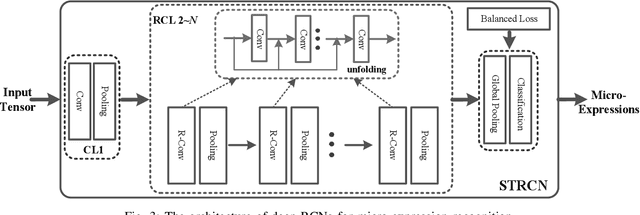

Recently, the recognition task of spontaneous facial micro-expressions has attracted much attention with its various real-world applications. Plenty of handcrafted or learned features have been employed for a variety of classifiers and achieved promising performances for recognizing micro-expressions. However, the micro-expression recognition is still challenging due to the subtle spatiotemporal changes of micro-expressions. To exploit the merits of deep learning, we propose a novel deep recurrent convolutional networks based micro-expression recognition approach, capturing the spatial-temporal deformations of micro-expression sequence. Specifically, the proposed deep model is constituted of several recurrent convolutional layers for extracting visual features and a classificatory layer for recognition. It is optimized by an end-to-end manner and obviates manual feature design. To handle sequential data, we exploit two types of extending the connectivity of convolutional networks across temporal domain, in which the spatiotemporal deformations are modeled in views of facial appearance and geometry separately. Besides, to overcome the shortcomings of limited and imbalanced training samples, temporal data augmentation strategies as well as a balanced loss are jointly used for our deep network. By performing the experiments on three spontaneous micro-expression datasets, we verify the effectiveness of our proposed micro-expression recognition approach compared to the state-of-the-art methods.
Face Presentation Attack Detection in Learned Color-liked Space
Oct 31, 2018
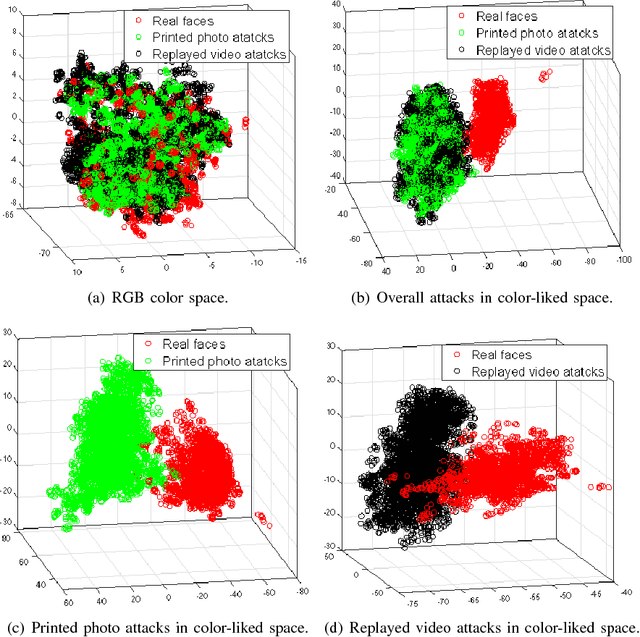
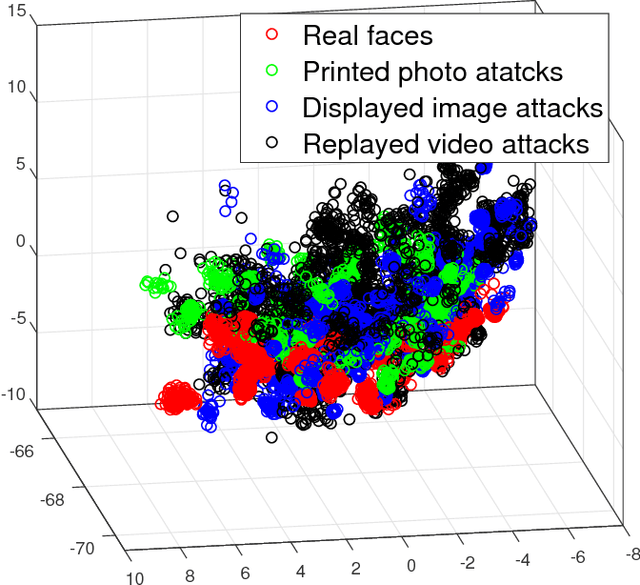
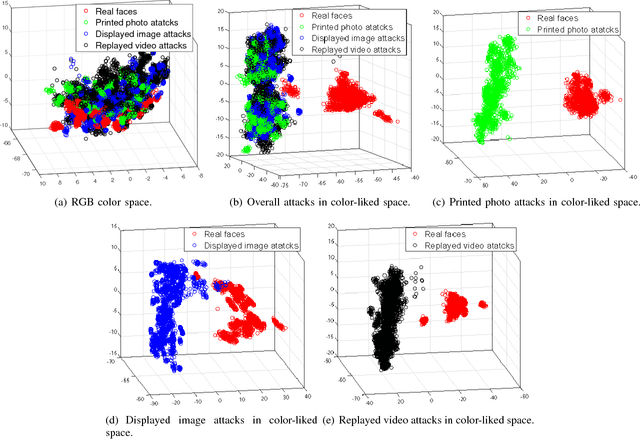
Face presentation attack detection (PAD) has become a thorny problem for biometric systems and numerous countermeasures have been proposed to address it. However, majority of them directly extract feature descriptors and distinguish fake faces from the real ones in existing color spaces (e.g. RGB, HSV and YCbCr). Unfortunately, it is unknown for us which color space is the best or how to combine different spaces together. To make matters worse, the real and fake faces are overlapped in existing color spaces. So, in this paper, a learned distinguishable color-liked space is generated to deal with the problem of face PAD. More specifically, we present an end-to-end deep learning network that can map existing color spaces to a new learned color-liked space. Inspired by the generator of generative adversarial network (GAN), the proposed network consists of a space generator and a feature extractor. When training the color-liked space, a new triplet combination mechanism of points-to-center is explored to maximize interclass distance and minimize intraclass distance, and also keep a safe margin between the real and presented fake faces. Extensive experiments on two standard face PAD databases, i.e., Relay-Attack and OULU-NPU, indicate that our proposed color-liked space analysis based countermeasure significantly outperforms the state-of-the-art methods and show excellent generalization capability.
Kinship Verification from Videos using Spatio-Temporal Texture Features and Deep Learning
Aug 14, 2017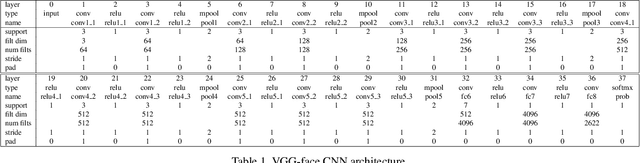
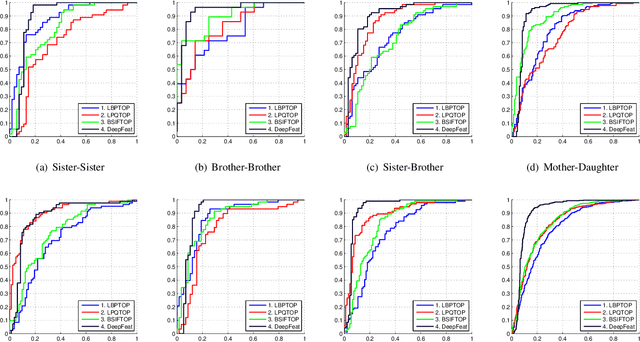
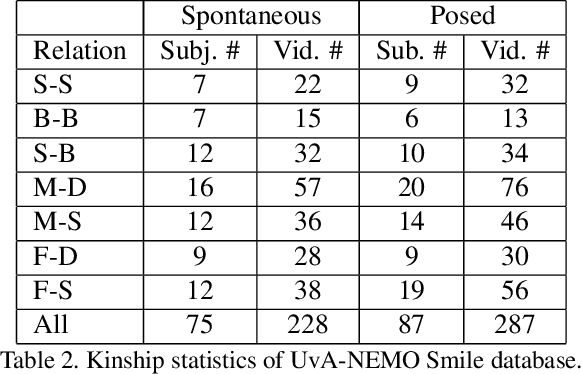
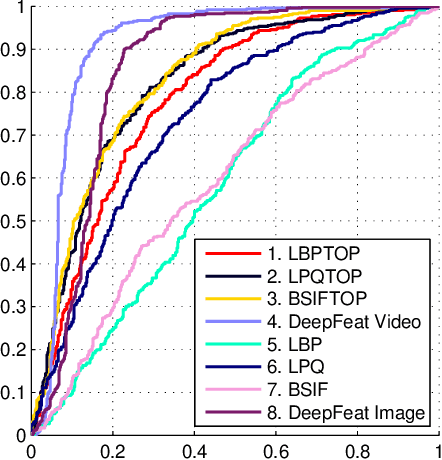
Automatic kinship verification using facial images is a relatively new and challenging research problem in computer vision. It consists in automatically predicting whether two persons have a biological kin relation by examining their facial attributes. While most of the existing works extract shallow handcrafted features from still face images, we approach this problem from spatio-temporal point of view and explore the use of both shallow texture features and deep features for characterizing faces. Promising results, especially those of deep features, are obtained on the benchmark UvA-NEMO Smile database. Our extensive experiments also show the superiority of using videos over still images, hence pointing out the important role of facial dynamics in kinship verification. Furthermore, the fusion of the two types of features (i.e. shallow spatio-temporal texture features and deep features) shows significant performance improvements compared to state-of-the-art methods.
Spontaneous Facial Micro-Expression Recognition using Discriminative Spatiotemporal Local Binary Pattern with an Improved Integral Projection
Aug 07, 2016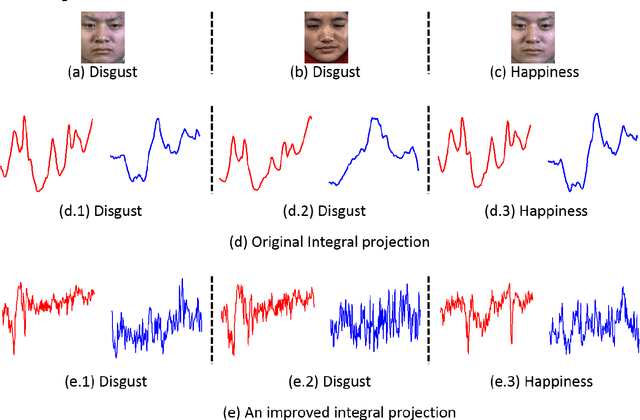
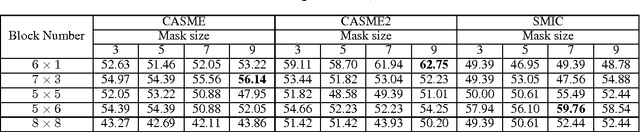
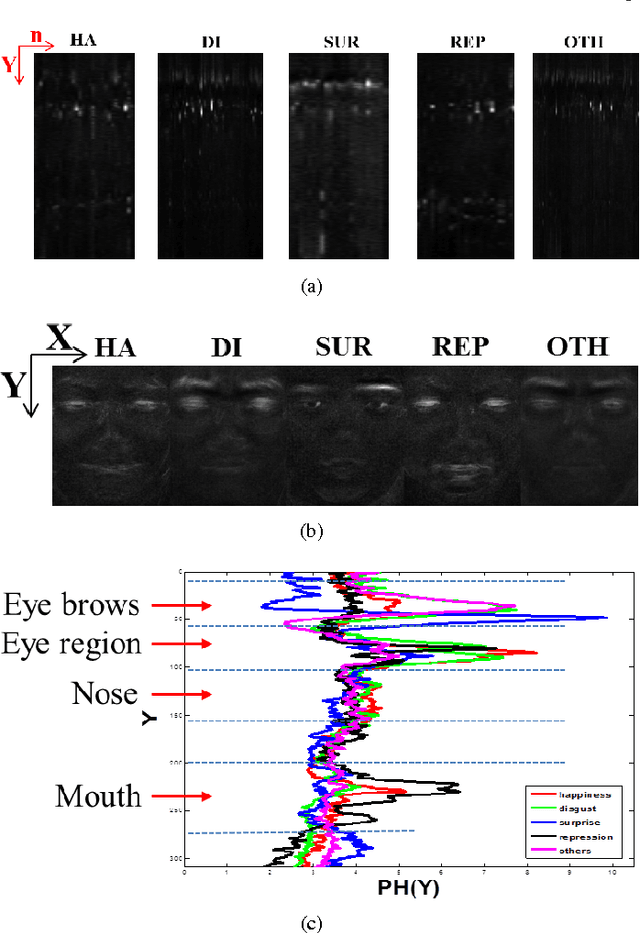
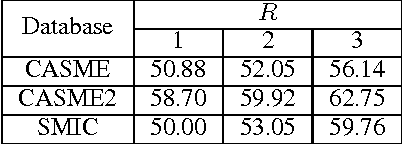
Recently, there are increasing interests in inferring mirco-expression from facial image sequences. Due to subtle facial movement of micro-expressions, feature extraction has become an important and critical issue for spontaneous facial micro-expression recognition. Recent works usually used spatiotemporal local binary pattern for micro-expression analysis. However, the commonly used spatiotemporal local binary pattern considers dynamic texture information to represent face images while misses the shape attribute of face images. On the other hand, their works extracted the spatiotemporal features from the global face regions, which ignore the discriminative information between two micro-expression classes. The above-mentioned problems seriously limit the application of spatiotemporal local binary pattern on micro-expression recognition. In this paper, we propose a discriminative spatiotemporal local binary pattern based on an improved integral projection to resolve the problems of spatiotemporal local binary pattern for micro-expression recognition. Firstly, we develop an improved integral projection for preserving the shape attribute of micro-expressions. Furthermore, an improved integral projection is incorporated with local binary pattern operators across spatial and temporal domains. Specifically, we extract the novel spatiotemporal features incorporating shape attributes into spatiotemporal texture features. For increasing the discrimination of micro-expressions, we propose a new feature selection based on Laplacian method to extract the discriminative information for facial micro-expression recognition. Intensive experiments are conducted on three availably published micro-expression databases. We compare our method with the state-of-the-art algorithms. Experimental results demonstrate that our proposed method achieves promising performance for micro-expression recognition.
Local feature hierarchy for face recognition across pose and illumination
Jul 12, 2016
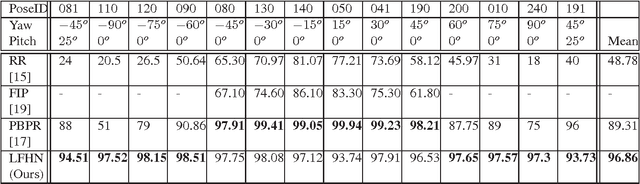
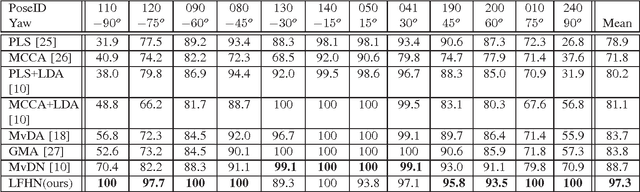
Even though face recognition in frontal view and normal lighting condition works very well, the performance degenerates sharply in extreme conditions. Recently there are many work dealing with pose and illumination problems, respectively. However both the lighting and pose variation will always be encountered at the same time. Accordingly we propose an end-to-end face recognition method to deal with pose and illumination simultaneously based on convolutional networks where the discriminative nonlinear features that are invariant to pose and illumination are extracted. Normally the global structure for images taken in different views is quite diverse. Therefore we propose to use the 1*1 convolutional kernel to extract the local features. Furthermore the parallel multi-stream multi-layer 1*1 convolution network is developed to extract multi-hierarchy features. In the experiments we obtained the average face recognition rate of 96.9% on multiPIE dataset,which improves the state-of-the-art of face recognition across poses and illumination by 7.5%. Especially for profile-wise positions, the average recognition rate of our proposed network is 97.8%, which increases the state-of-the-art recognition rate by 19%.
Unsupervised Deep Hashing for Large-scale Visual Search
Jan 31, 2016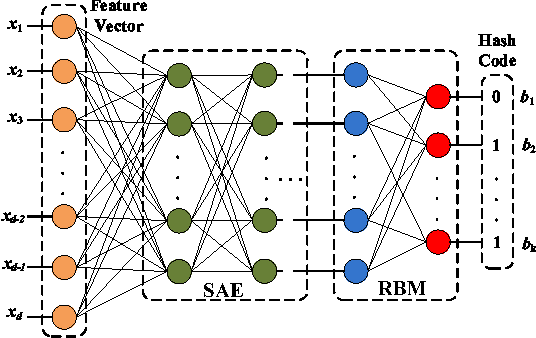
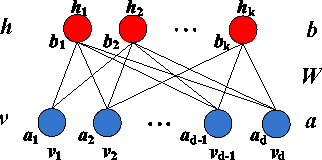
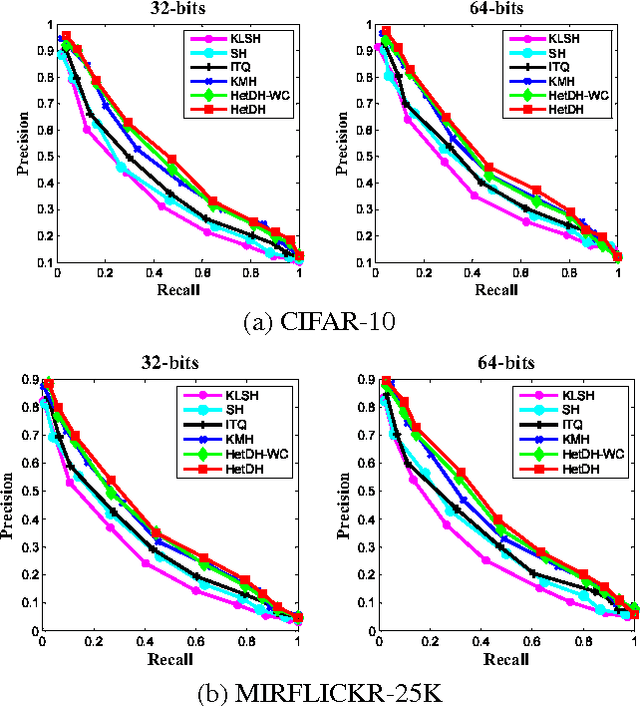
Learning based hashing plays a pivotal role in large-scale visual search. However, most existing hashing algorithms tend to learn shallow models that do not seek representative binary codes. In this paper, we propose a novel hashing approach based on unsupervised deep learning to hierarchically transform features into hash codes. Within the heterogeneous deep hashing framework, the autoencoder layers with specific constraints are considered to model the nonlinear mapping between features and binary codes. Then, a Restricted Boltzmann Machine (RBM) layer with constraints is utilized to reduce the dimension in the hamming space. Extensive experiments on the problem of visual search demonstrate the competitiveness of our proposed approach compared to state-of-the-art.