 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDominant Patterns: Critical Features Hidden in Deep Neural Networks
May 31, 2021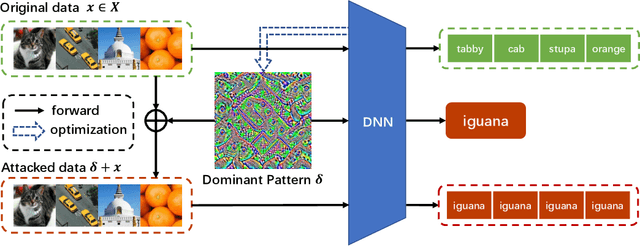
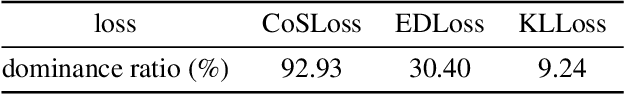

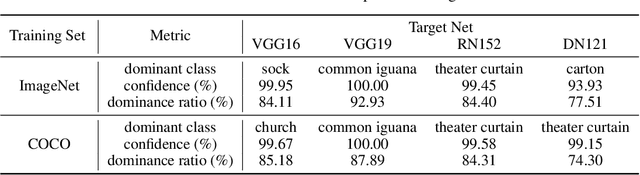
In this paper, we find the existence of critical features hidden in Deep NeuralNetworks (DNNs), which are imperceptible but can actually dominate the outputof DNNs. We call these features dominant patterns. As the name suggests, for a natural image, if we add the dominant pattern of a DNN to it, the output of this DNN is determined by the dominant pattern instead of the original image, i.e., DNN's prediction is the same with the dominant pattern's. We design an algorithm to find such patterns by pursuing the insensitivity in the feature space. A direct application of the dominant patterns is the Universal Adversarial Perturbations(UAPs). Numerical experiments show that the found dominant patterns defeat state-of-the-art UAP methods, especially in label-free settings. In addition, dominant patterns are proved to have the potential to attack downstream tasks in which DNNs share the same backbone. We claim that DNN-specific dominant patterns reveal some essential properties of a DNN and are of great importance for its feature analysis and robustness enhancement.
QueryNet: An Efficient Attack Framework with Surrogates Carrying Multiple Identities
May 31, 2021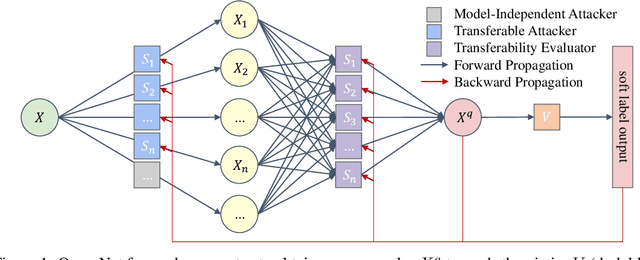
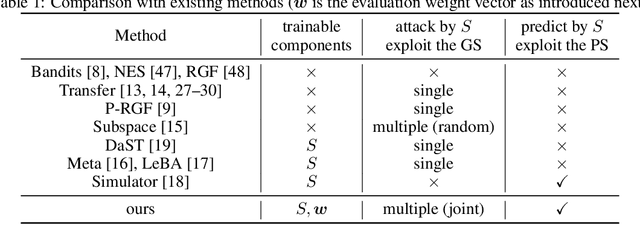

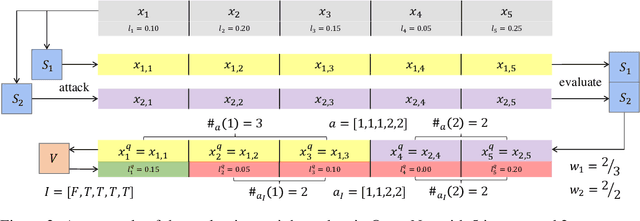
Deep Neural Networks (DNNs) are acknowledged as vulnerable to adversarial attacks, while the existing black-box attacks require extensive queries on the victim DNN to achieve high success rates. For query-efficiency, surrogate models of the victim are adopted as transferable attackers in consideration of their Gradient Similarity (GS), i.e., surrogates' attack gradients are similar to the victim's ones to some extent. However, it is generally neglected to exploit their similarity on outputs, namely the Prediction Similarity (PS), to filter out inefficient queries. To jointly utilize and also optimize surrogates' GS and PS, we develop QueryNet, an efficient attack network that can significantly reduce queries. QueryNet crafts several transferable Adversarial Examples (AEs) by surrogates, and then decides also by surrogates on the most promising AE, which is then sent to query the victim. That is to say, in QueryNet, surrogates are not only exploited as transferable attackers, but also as transferability evaluators for AEs. The AEs are generated using surrogates' GS and evaluated based on their FS, and therefore, the query results could be back-propagated to optimize surrogates' parameters and also their architectures, enhancing both the GS and the FS. QueryNet has significant query-efficiency, i.e., reduces queries by averagely about an order of magnitude compared to recent SOTA methods according to our comprehensive and real-world experiments: 11 victims (including 2 commercial models) on MNIST/CIFAR10/ImageNet, allowing only 8-bit image queries, and no access to the victim's training data.
Residual Enhanced Multi-Hypergraph Neural Network
May 02, 2021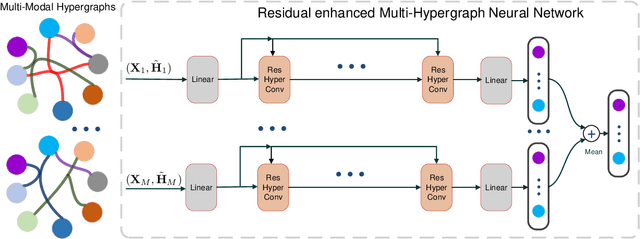

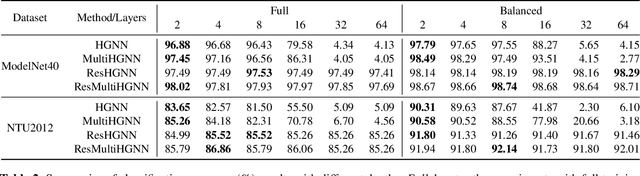
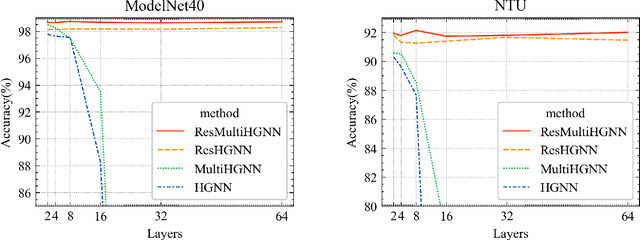
Hypergraphs are a generalized data structure of graphs to model higher-order correlations among entities, which have been successfully adopted into various research domains. Meanwhile, HyperGraph Neural Network (HGNN) is currently the de-facto method for hypergraph representation learning. However, HGNN aims at single hypergraph learning and uses a pre-concatenation approach when confronting multi-modal datasets, which leads to sub-optimal exploitation of the inter-correlations of multi-modal hypergraphs. HGNN also suffers the over-smoothing issue, that is, its performance drops significantly when layers are stacked up. To resolve these issues, we propose the Residual enhanced Multi-Hypergraph Neural Network, which can not only fuse multi-modal information from each hypergraph effectively, but also circumvent the over-smoothing issue associated with HGNN. We conduct experiments on two 3D benchmarks, the NTU and the ModelNet40 datasets, and compare against multiple state-of-the-art methods. Experimental results demonstrate that both the residual hypergraph convolutions and the multi-fusion architecture can improve the performance of the base model and the combined model achieves a new state-of-the-art. Code is available at \url{https://github.com/OneForward/ResMHGNN}.
Towards Unbiased Random Features with Lower Variance For Stationary Indefinite Kernels
Apr 14, 2021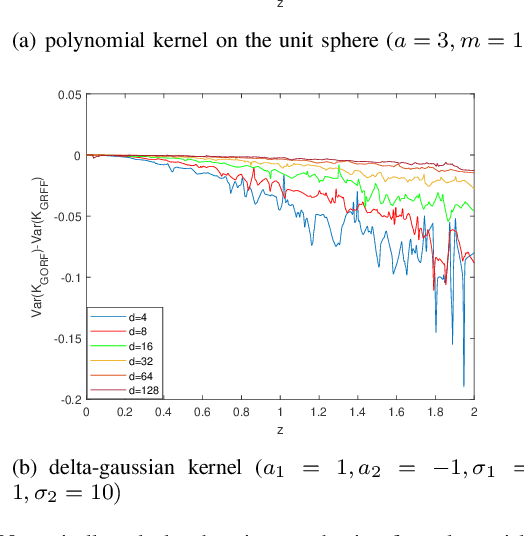
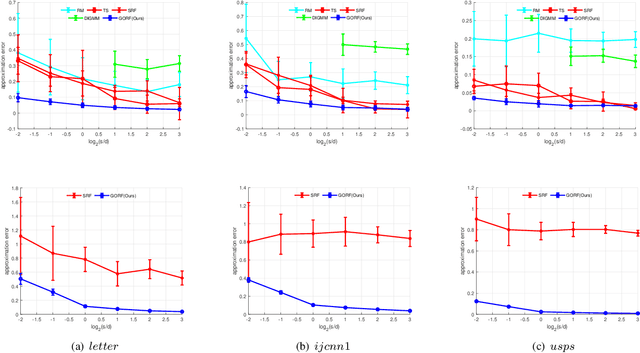
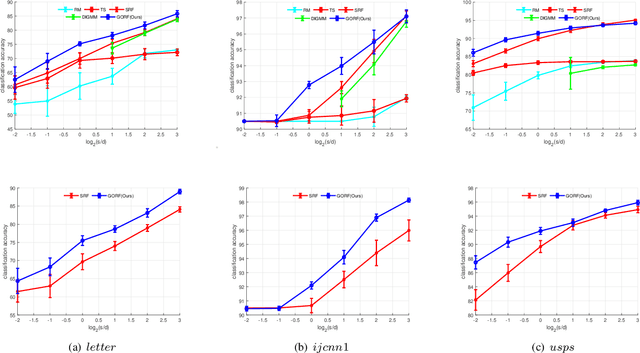
Random Fourier Features (RFF) demonstrate wellappreciated performance in kernel approximation for largescale situations but restrict kernels to be stationary and positive definite. And for non-stationary kernels, the corresponding RFF could be converted to that for stationary indefinite kernels when the inputs are restricted to the unit sphere. Numerous methods provide accessible ways to approximate stationary but indefinite kernels. However, they are either biased or possess large variance. In this article, we propose the generalized orthogonal random features, an unbiased estimation with lower variance.Experimental results on various datasets and kernels verify that our algorithm achieves lower variance and approximation error compared with the existing kernel approximation methods. With better approximation to the originally selected kernels, improved classification accuracy and regression ability is obtained with our approximation algorithm in the framework of support vector machine and regression.
Weighted Neural Tangent Kernel: A Generalized and Improved Network-Induced Kernel
Mar 22, 2021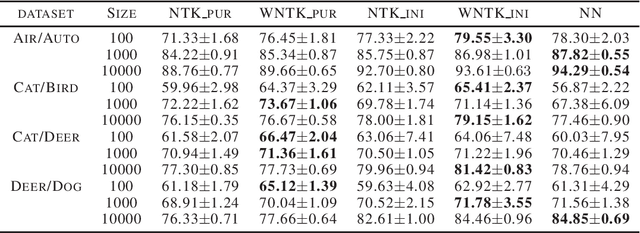
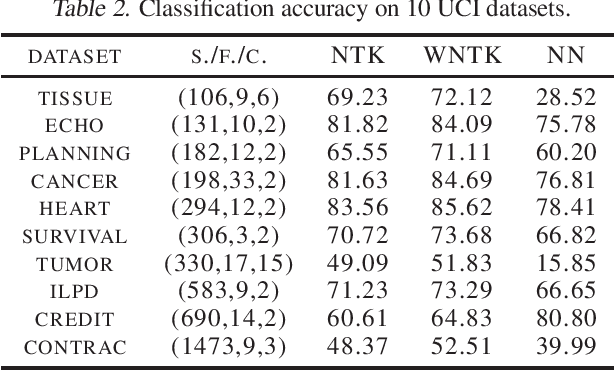
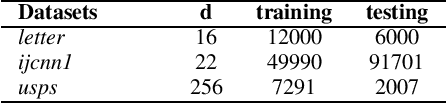
The Neural Tangent Kernel (NTK) has recently attracted intense study, as it describes the evolution of an over-parameterized Neural Network (NN) trained by gradient descent. However, it is now well-known that gradient descent is not always a good optimizer for NNs, which can partially explain the unsatisfactory practical performance of the NTK regression estimator. In this paper, we introduce the Weighted Neural Tangent Kernel (WNTK), a generalized and improved tool, which can capture an over-parameterized NN's training dynamics under different optimizers. Theoretically, in the infinite-width limit, we prove: i) the stability of the WNTK at initialization and during training, and ii) the equivalence between the WNTK regression estimator and the corresponding NN estimator with different learning rates on different parameters. With the proposed weight update algorithm, both empirical and analytical WNTKs outperform the corresponding NTKs in numerical experiments.
Train Deep Neural Networks in 40-D Subspaces
Mar 20, 2021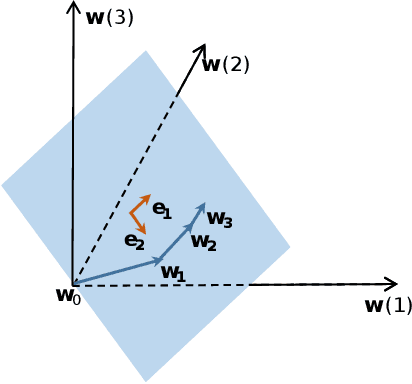
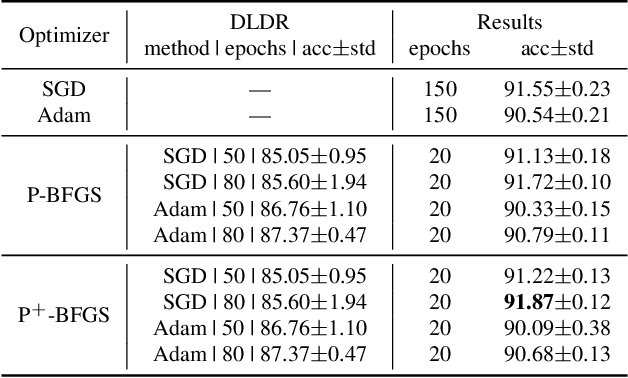
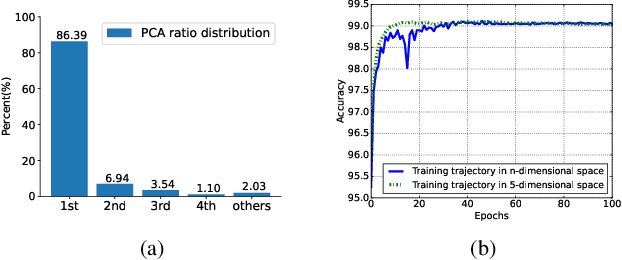
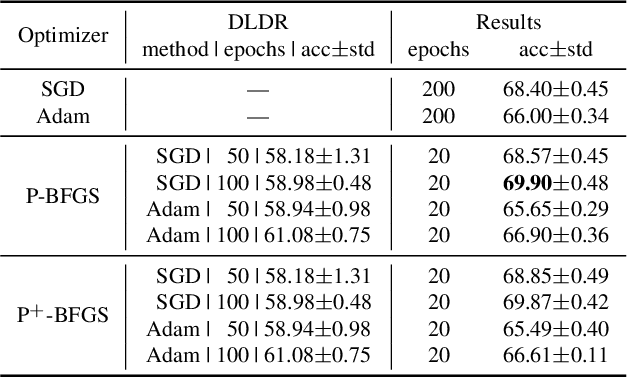
Although there are massive parameters in deep neural networks, the training can actually proceed in a rather low-dimensional space. By investigating such low-dimensional properties of the training trajectory, we propose a Dynamic Linear Dimensionality Reduction (DLDR), which dramatically reduces the parameter space to a variable subspace of significantly lower dimension. Since there are only a few variables to optimize, second-order methods become applicable. Following this idea, we develop a quasi-Newton-based algorithm to train these variables obtained by DLDR, rather than the original parameters of neural networks. The experimental results strongly support the dimensionality reduction performance: for many standard neural networks, optimizing over only 40 variables, one can achieve comparable performance against the regular training over thousands or even millions of parameters.
Going Far Boosts Attack Transferability, but Do Not Do It
Feb 20, 2021
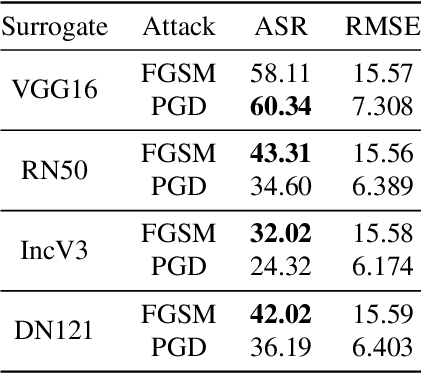
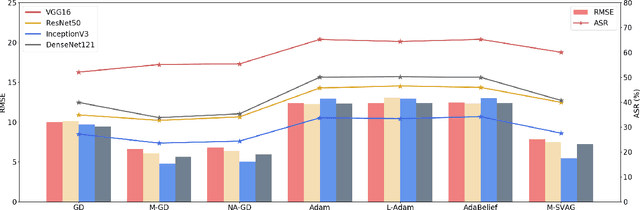
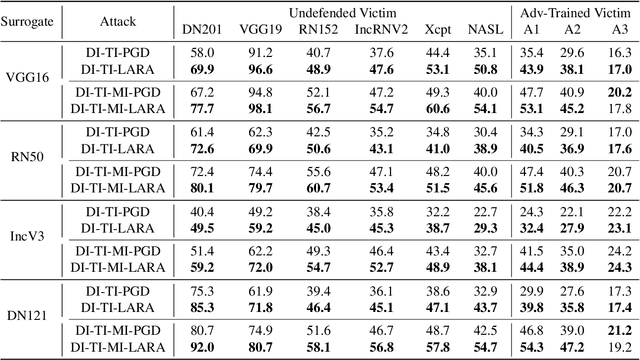
Deep Neural Networks (DNNs) could be easily fooled by Adversarial Examples (AEs) with an imperceptible difference to original ones in human eyes. Also, the AEs from attacking one surrogate DNN tend to cheat other black-box DNNs as well, i.e., the attack transferability. Existing works reveal that adopting certain optimization algorithms in attack improves transferability, but the underlying reasons have not been thoroughly studied. In this paper, we investigate the impacts of optimization on attack transferability by comprehensive experiments concerning 7 optimization algorithms, 4 surrogates, and 9 black-box models. Through the thorough empirical analysis from three perspectives, we surprisingly find that the varied transferability of AEs from optimization algorithms is strongly related to the corresponding Root Mean Square Error (RMSE) from their original samples. On such a basis, one could simply approach high transferability by attacking until RMSE decreases, which motives us to propose a LArge RMSE Attack (LARA). Although LARA significantly improves transferability by 20%, it is insufficient to exploit the vulnerability of DNNs, leading to a natural urge that the strength of all attacks should be measured by both the widely used $\ell_\infty$ bound and the RMSE addressed in this paper, so that tricky enhancement of transferability would be avoided.
Learning Tubule-Sensitive CNNs for Pulmonary Airway and Artery-Vein Segmentation in CT
Dec 10, 2020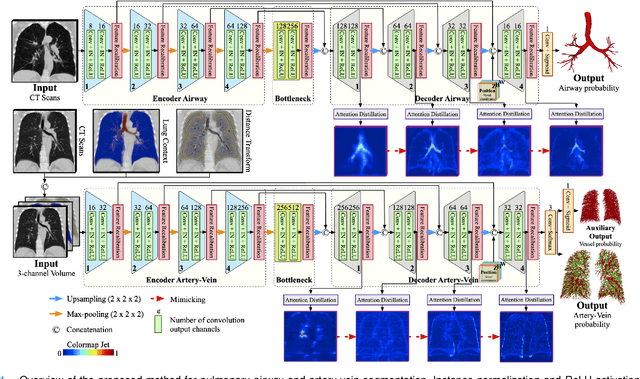
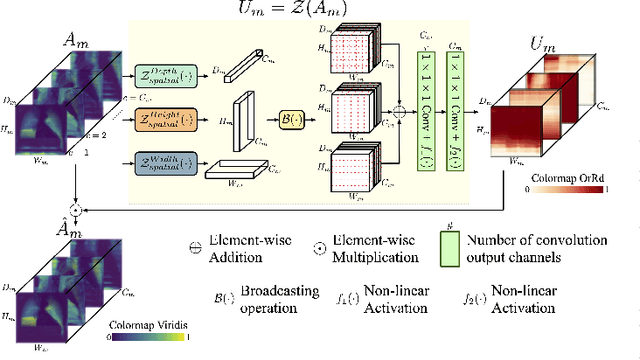

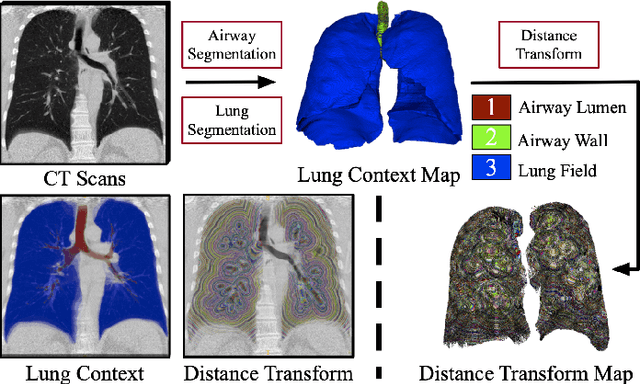
Training convolutional neural networks (CNNs) for segmentation of pulmonary airway, artery, and vein is challenging due to sparse supervisory signals caused by the severe class imbalance between tubular targets and background. We present a CNNs-based method for accurate airway and artery-vein segmentation in non-contrast computed tomography. It enjoys superior sensitivity to tenuous peripheral bronchioles, arterioles, and venules. The method first uses a feature recalibration module to make the best use of features learned from the neural networks. Spatial information of features is properly integrated to retain relative priority of activated regions, which benefits the subsequent channel-wise recalibration. Then, attention distillation module is introduced to reinforce representation learning of tubular objects. Fine-grained details in high-resolution attention maps are passing down from one layer to its previous layer recursively to enrich context. Anatomy prior of lung context map and distance transform map is designed and incorporated for better artery-vein differentiation capacity. Extensive experiments demonstrated considerable performance gains brought by these components. Compared with state-of-the-art methods, our method extracted much more branches while maintaining competitive overall segmentation performance. Codes and models will be available later at http://www.pami.sjtu.edu.cn.
Towards a Unified Quadrature Framework for Large-Scale Kernel Machines
Nov 03, 2020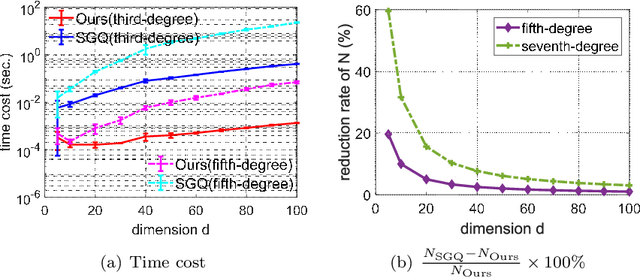

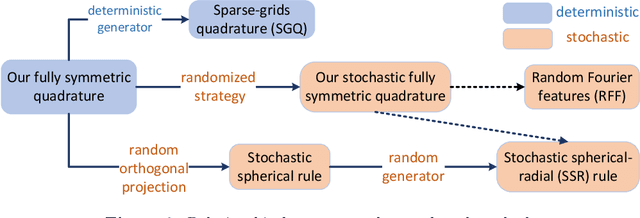
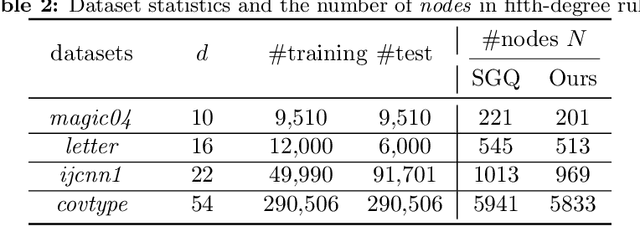
In this paper, we develop a quadrature framework for large-scale kernel machines via a numerical multiple integration representation. Leveraging the fact that the integration domain and measure of typical kernels, e.g., Gaussian kernels, arc-cosine kernels, are fully symmetric, we introduce a deterministic fully symmetric interpolatory rule to efficiently compute its quadrature nodes and associated weights to approximate such typical kernels. This interpolatory rule is able to reduce the number of needed nodes while retaining a high approximation accuracy. Further, we randomize the above deterministic rule such that the proposed stochastic version can generate dimension-adaptive feature mappings for kernel approximation. Our stochastic rule has the nice statistical properties of unbiasedness and variance reduction with fast convergence rate. In addition, we elucidate the relationship between our deterministic/stochastic interpolatory rules and current quadrature rules for kernel approximation, including the sparse grids quadrature and stochastic spherical-radial rule, thereby unifying these methods under our framework. Experimental results on several benchmark datasets show that our fully symmetric interpolatory rule compares favorably with other representative random features based methods.
Learn Robust Features via Orthogonal Multi-Path
Oct 23, 2020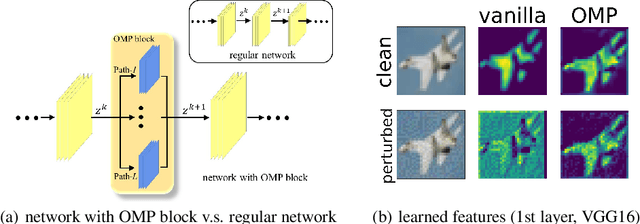
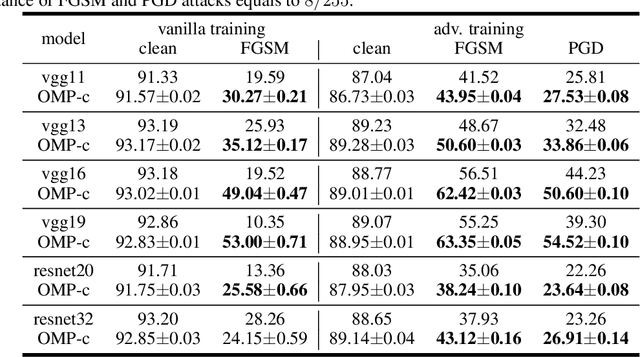
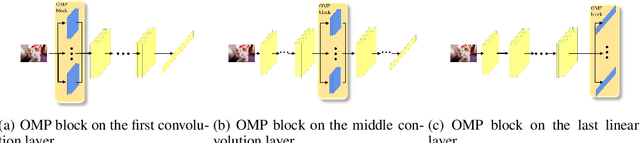
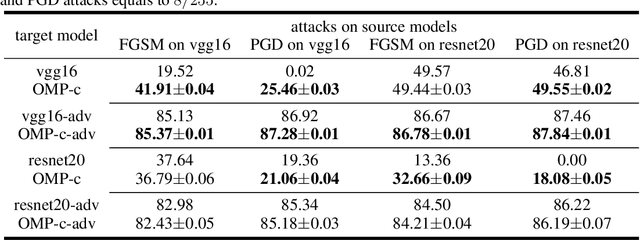
It is now widely known that by adversarial attacks, clean images with invisible perturbations can fool deep neural networks. To defend adversarial attacks, we design a block containing multiple paths to learn robust features and the parameters of these paths are required to be orthogonal with each other. The so-called Orthogonal Multi-Path (OMP) block could be posed in any layer of a neural network. Via forward learning and backward correction, one OMP block makes the neural networks learn features that are appropriate for all the paths and hence are expected to be robust. With careful design and thorough experiments on e.g., the positions of imposing orthogonality constraint, and the trade-off between the variety and accuracy, the robustness of the neural networks is significantly improved. For example, under white-box PGD attack with $l_\infty$ bound ${8}/{255}$ (this is a fierce attack that can make the accuracy of many vanilla neural networks drop to nearly $10\%$ on CIFAR10), VGG16 with the proposed OMP block could keep over $50\%$ accuracy. For black-box attacks, neural networks equipped with an OMP block have accuracy over $80\%$. The performance under both white-box and black-box attacks is much better than the existing state-of-the-art adversarial defenders.