 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelHacker: Image Inpainting with Structural and Semantic Consistency
Apr 30, 2025Image inpainting is a fundamental research area between image editing and image generation. Recent state-of-the-art (SOTA) methods have explored novel attention mechanisms, lightweight architectures, and context-aware modeling, demonstrating impressive performance. However, they often struggle with complex structure (e.g., texture, shape, spatial relations) and semantics (e.g., color consistency, object restoration, and logical correctness), leading to artifacts and inappropriate generation. To address this challenge, we design a simple yet effective inpainting paradigm called latent categories guidance, and further propose a diffusion-based model named PixelHacker. Specifically, we first construct a large dataset containing 14 million image-mask pairs by annotating foreground and background (potential 116 and 21 categories, respectively). Then, we encode potential foreground and background representations separately through two fixed-size embeddings, and intermittently inject these features into the denoising process via linear attention. Finally, by pre-training on our dataset and fine-tuning on open-source benchmarks, we obtain PixelHacker. Extensive experiments show that PixelHacker comprehensively outperforms the SOTA on a wide range of datasets (Places2, CelebA-HQ, and FFHQ) and exhibits remarkable consistency in both structure and semantics. Project page at https://hustvl.github.io/PixelHacker.
Brain Tumor Segmentation Based on Refined Fully Convolutional Neural Networks with A Hierarchical Dice Loss
Feb 13, 2018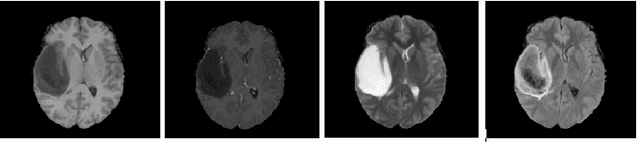
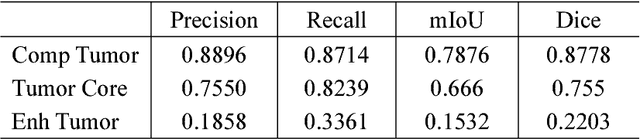
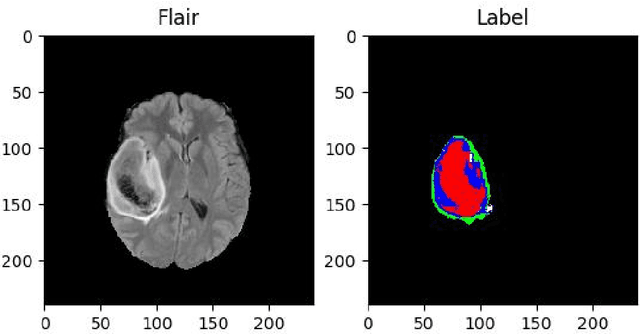
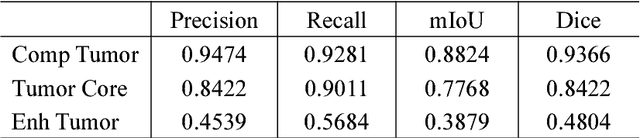
As a basic task in computer vision, semantic segmentation can provide fundamental information for object detection and instance segmentation to help the artificial intelligence better understand real world. Since the proposal of fully convolutional neural network (FCNN), it has been widely used in semantic segmentation because of its high accuracy of pixel-wise classification as well as high precision of localization. In this paper, we apply several famous FCNN to brain tumor segmentation, making comparisons and adjusting network architectures to achieve better performance measured by metrics such as precision, recall, mean of intersection of union (mIoU) and dice score coefficient (DSC). The adjustments to the classic FCNN include adding more connections between convolutional layers, enlarging decoders after up sample layers and changing the way shallower layers' information is reused. Besides the structure modification, we also propose a new classifier with a hierarchical dice loss. Inspired by the containing relationship between classes, the loss function converts multiple classification to multiple binary classification in order to counteract the negative effect caused by imbalance data set. Massive experiments have been done on the training set and testing set in order to assess our refined fully convolutional neural networks and new types of loss function. Competitive figures prove they are more effective than their predecessors.
An Automatic Diagnosis Method of Facial Acne Vulgaris Based on Convolutional Neural Network
Nov 13, 2017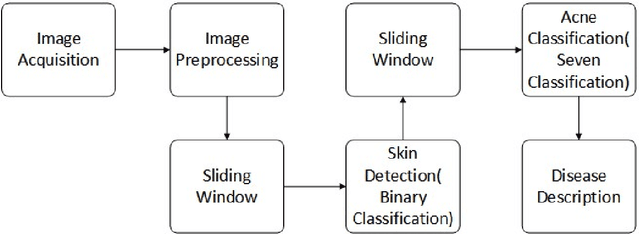



In this paper, we present a new automatic diagnosis method of facial acne vulgaris based on convolutional neural network. This method is proposed to overcome the shortcoming of classification types in previous methods. The core of our method is to extract features of images based on convolutional neural network and achieve classification by classifier. We design a binary classifier of skin-and-non-skin to detect skin area and a seven-classifier to achieve the classification of facial acne vulgaris and healthy skin. In the experiment, we compared the effectiveness of our convolutional neural network and the pre-trained VGG16 neural network on the ImageNet dataset. And we use the ROC curve and normal confusion matrix to evaluate the performance of the binary classifier and the seven-classifier. The results of our experiment show that the pre-trained VGG16 neural network is more effective in extracting image features. The classifiers based on the pre-trained VGG16 neural network achieve the skin detection and acne classification and have good robustness.