 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance the Motion Cues for Face Anti-Spoofing using CNN-LSTM Architecture
Jan 17, 2019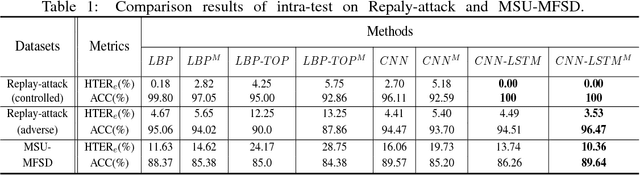
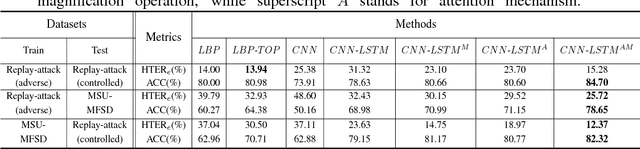
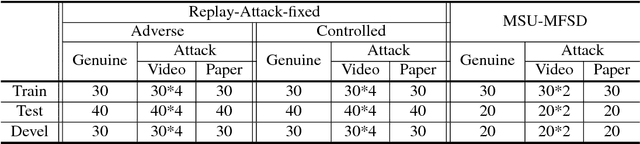
Spatio-temporal information is very important to capture the discriminative cues between genuine and fake faces from video sequences. To explore such a temporal feature, the fine-grained motions (e.g., eye blinking, mouth movements and head swing) across video frames are very critical. In this paper, we propose a joint CNN-LSTM network for face anti-spoofing, focusing on the motion cues across video frames. We first extract the high discriminative features of video frames using the conventional Convolutional Neural Network (CNN). Then we leverage Long Short-Term Memory (LSTM) with the extracted features as inputs to capture the temporal dynamics in videos. To ensure the fine-grained motions more easily to be perceived in the training process, the eulerian motion magnification is used as the preprocessing to enhance the facial expressions exhibited by individuals, and the attention mechanism is embedded in LSTM to ensure the model learn to focus selectively on the dynamic frames across the video clips. Experiments on Replay Attack and MSU-MFSD databases show that the proposed method yields state-of-the-art performance with better generalization ability compared with several other popular algorithms.
Deep Transfer Across Domains for Face Anti-spoofing
Jan 17, 2019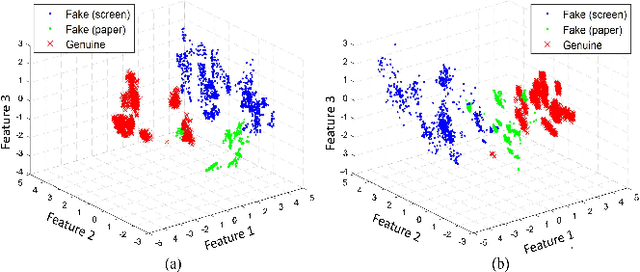
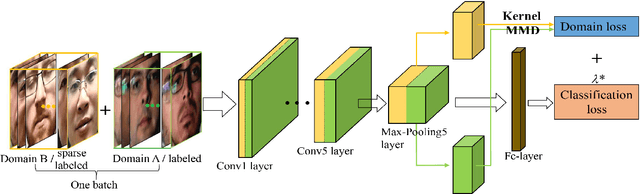
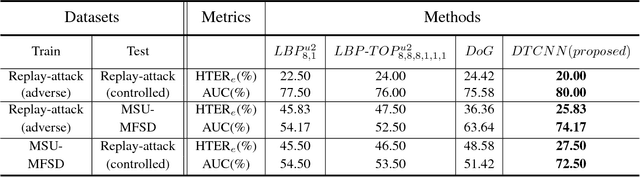
A practical face recognition system demands not only high recognition performance, but also the capability of detecting spoofing attacks. While emerging approaches of face anti-spoofing have been proposed in recent years, most of them do not generalize well to new database. The generalization ability of face anti-spoofing needs to be significantly improved before they can be adopted by practical application systems. The main reason for the poor generalization of current approaches is the variety of materials among the spoofing devices. As the attacks are produced by putting a spoofing display (e.t., paper, electronic screen, forged mask) in front of a camera, the variety of spoofing materials can make the spoofing attacks quite different. Furthermore, the background/lighting condition of a new environment can make both the real accesses and spoofing attacks different. Another reason for the poor generalization is that limited labeled data is available for training in face anti-spoofing. In this paper, we focus on improving the generalization ability across different kinds of datasets. We propose a CNN framework using sparsely labeled data from the target domain to learn features that are invariant across domains for face anti-spoofing. Experiments on public-domain face spoofing databases show that the proposed method significantly improve the cross-dataset testing performance only with a small number of labeled samples from the target domain.
Learning Generalizable and Identity-Discriminative Representations for Face Anti-Spoofing
Jan 17, 2019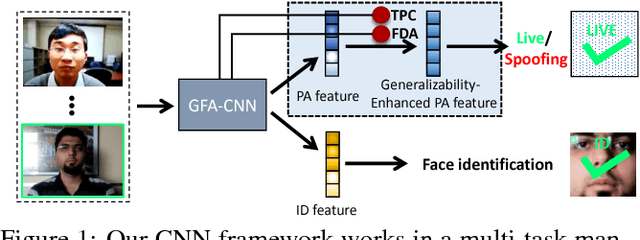
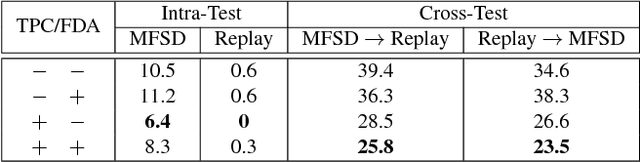
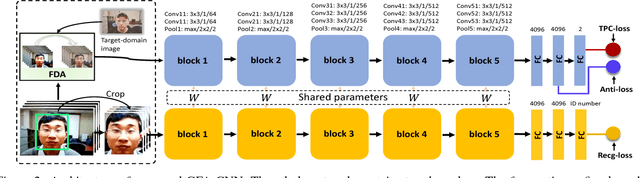

Face anti-spoofing (a.k.a presentation attack detection) has drawn growing attention due to the high-security demand in face authentication systems. Existing CNN-based approaches usually well recognize the spoofing faces when training and testing spoofing samples display similar patterns, but their performance would drop drastically on testing spoofing faces of unseen scenes. In this paper, we try to boost the generalizability and applicability of these methods by designing a CNN model with two major novelties. First, we propose a simple yet effective Total Pairwise Confusion (TPC) loss for CNN training, which enhances the generalizability of the learned Presentation Attack (PA) representations. Secondly, we incorporate a Fast Domain Adaptation (FDA) component into the CNN model to alleviate negative effects brought by domain changes. Besides, our proposed model, which is named Generalizable Face Authentication CNN (GFA-CNN), works in a multi-task manner, performing face anti-spoofing and face recognition simultaneously. Experimental results show that GFA-CNN outperforms previous face anti-spoofing approaches and also well preserves the identity information of input face images.
Detecting Multi-Oriented Text with Corner-based Region Proposals
Apr 08, 2018
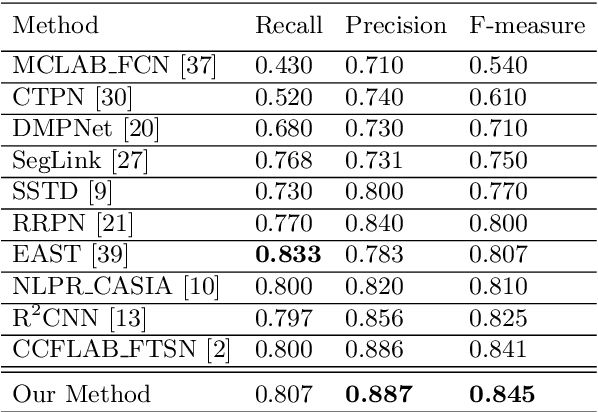

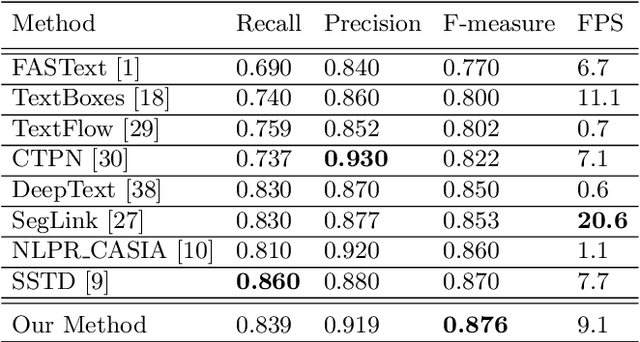
Previous approaches for scene text detection usually rely on manually defined sliding windows. In this paper, an intuitive region-based method is presented to detect multi-oriented text without any prior knowledge regarding the textual shape. We first introduce a Corner-based Region Proposal Network (CRPN) that employs corners to estimate the possible locations of text instances instead of shifting a set of default anchors. The proposals generated by CRPN are geometry adaptive, which makes our method robust to various text aspect ratios and orientations. Moreover, we design a simple embedded data augmentation module inside the region-wise subnetwork, which not only ensures the model utilizes training data more efficiently, but also learns to find the most representative instance of the input images for training. Experimental results on public benchmarks confirm that the proposed method is capable of achieving comparable performance with the state-of-the-art methods. On the ICDAR 2013 and 2015 datasets, it obtains F-measure of 0.876 and 0.845 respectively. The code is publicly available at https://github.com/xhzdeng/crpn