 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-latency Monaural Speech Enhancement with Deep Filter-bank Equalizer
Feb 14, 2022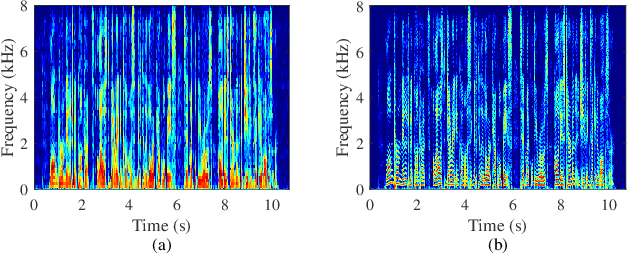

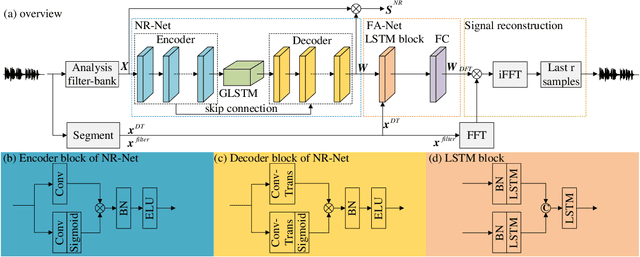
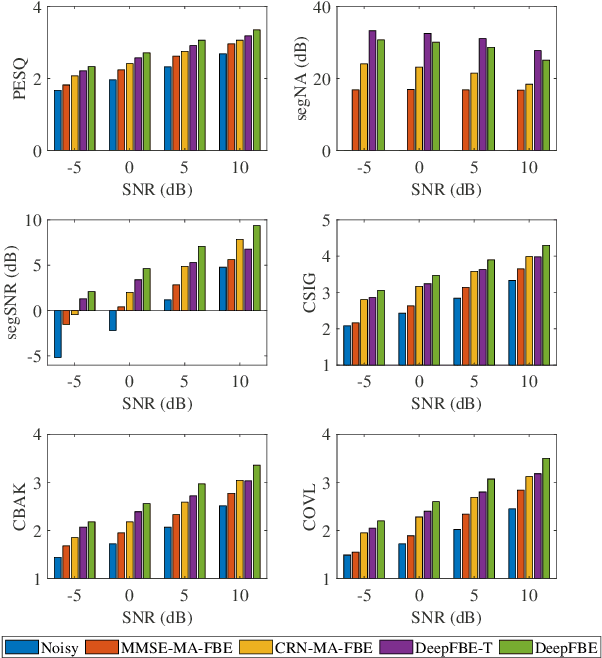
It is highly desirable that speech enhancement algorithms can achieve good performance while keeping low latency for many applications, such as digital hearing aids, acoustically transparent hearing devices, and public address systems. To improve the performance of traditional low-latency speech enhancement algorithms, a deep filter-bank equalizer (FBE) framework was proposed, which integrated a deep learning-based subband noise reduction network with a deep learning-based shortened digital filter mapping network. In the first network, a deep learning model was trained with a controllable small frame shift to satisfy the low-latency demand, i.e., $\le$ 4 ms, so as to obtain (complex) subband gains, which could be regarded as an adaptive digital filter in each frame. In the second network, to reduce the latency, this adaptive digital filter was implicitly shortened by a deep learning-based framework, and was then applied to noisy speech to reconstruct the enhanced speech without the overlap-add method. Experimental results on the WSJ0-SI84 corpus indicated that the proposed deep FBE with only 4-ms latency achieved much better performance than traditional low-latency speech enhancement algorithms in terms of the indices such as PESQ, STOI, and the amount of noise reduction.
A Neural Beam Filter for Real-time Multi-channel Speech Enhancement
Feb 05, 2022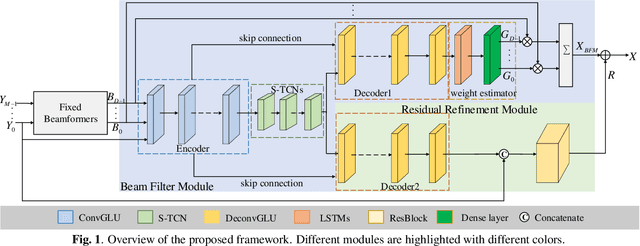
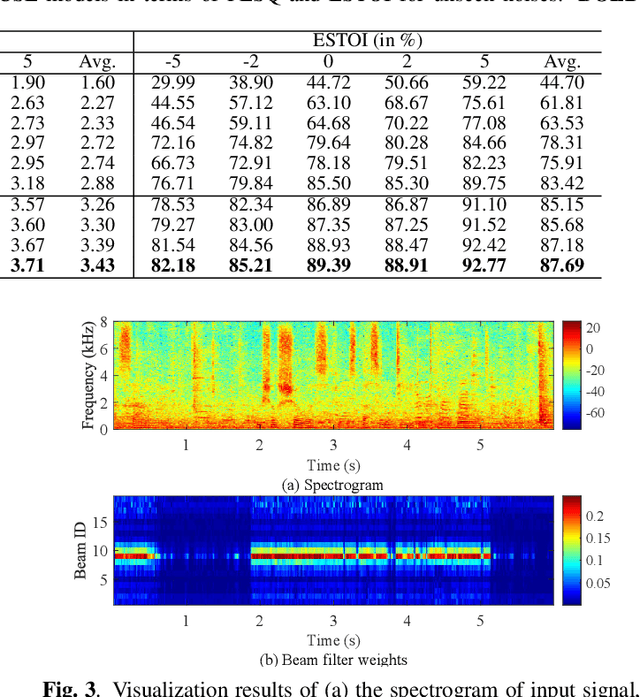
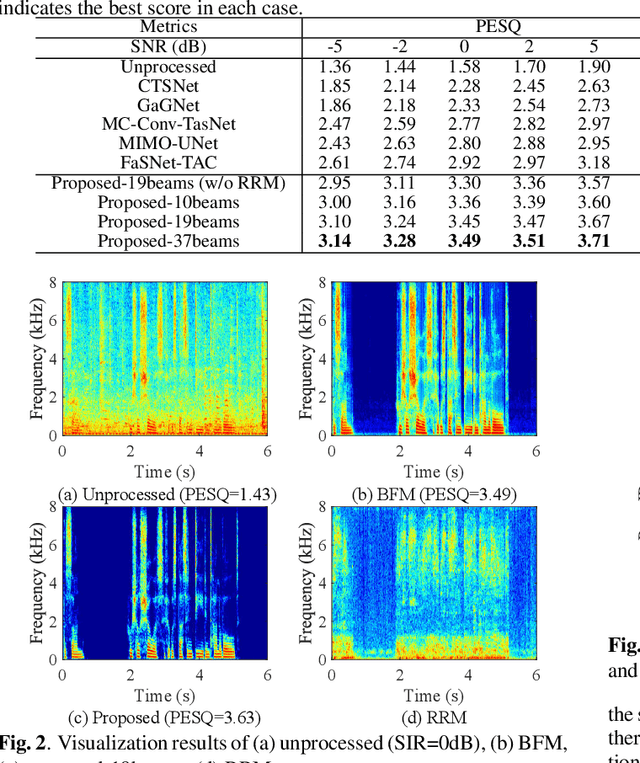
Most deep learning-based multi-channel speech enhancement methods focus on designing a set of beamforming coefficients to directly filter the low signal-to-noise ratio signals received by microphones, which hinders the performance of these approaches. To handle these problems, this paper designs a causal neural beam filter that fully exploits the spatial-spectral information in the beam domain. Specifically, multiple beams are designed to steer towards all directions using a parameterized super-directive beamformer in the first stage. After that, the neural spatial filter is learned by simultaneously modeling the spatial and spectral discriminability of the speech and the interference, so as to extract the desired speech coarsely in the second stage. Finally, to further suppress the interference components especially at low frequencies, a residual estimation module is adopted to refine the output of the second stage. Experimental results demonstrate that the proposed approach outperforms many state-of-the-art multi-channel methods on the generated multi-channel speech dataset based on the DNS-Challenge dataset.
A deep complex network with multi-frame filtering for stereophonic acoustic echo cancellation
Feb 03, 2022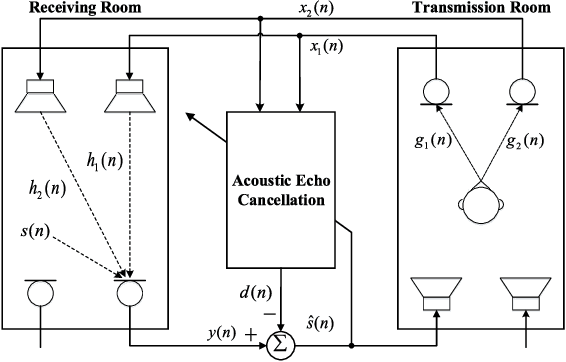
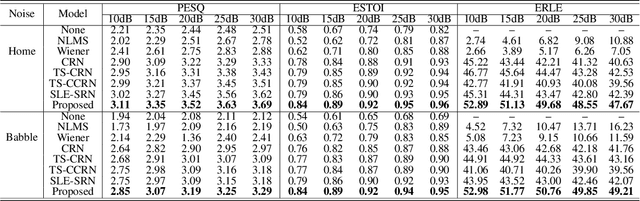
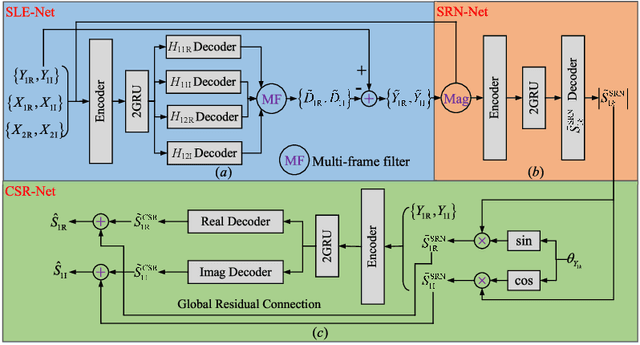
In hands-free communication system, the coupling between the loudspeaker and the microphone will generate echo signal, which can severely impair the quality of communication. Meanwhile, various types of noise in the communication environment further destroy the speech quality and intelligibility. It is hard to extract the near-end signal from the microphone input signal within one step, especially in low signal-to-noise ratios. In this paper, we propose a multi-stage approach to address this issue. On the one hand, we decompose the echo cancellation into two stages, including linear echo cancellation module and residual echo suppression module. A multi-frame filtering strategy is introduced to benefit estimating linear echo by utilizing more inter-frame information. On the other hand, we decouple the complex spectral mapping into magnitude estimation and complex spectra refine. Experimental results demonstrate that our proposed approach achieves stage-of-the-art performance over previous advanced algorithms under various conditions.
Pseudo-labelling and Meta Reweighting Learning for Image Aesthetic Quality Assessment
Jan 08, 2022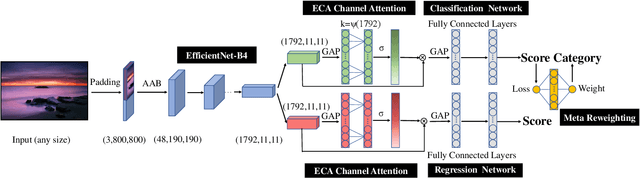

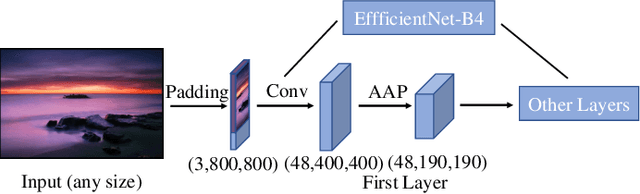
In the tasks of image aesthetic quality evaluation, it is difficult to reach both the high score area and low score area due to the normal distribution of aesthetic datasets. To reduce the error in labeling and solve the problem of normal data distribution, we propose a new aesthetic mixed dataset with classification and regression called AMD-CR, and we train a meta reweighting network to reweight the loss of training data differently. In addition, we provide a training strategy acccording to different stages, based on pseudo labels of the binary classification task, and then we use it for aesthetic training acccording to different stages in classification and regression tasks. In the construction of the network structure, we construct an aesthetic adaptive block (AAB) structure that can adapt to any size of the input images. Besides, we also use the efficient channel attention (ECA) to strengthen the feature extracting ability of each task. The experimental result shows that our method improves 0.1112 compared with the conventional methods in SROCC. The method can also help to find best aesthetic path planning for unmanned aerial vehicles (UAV) and vehicles.
EmotionBox: a music-element-driven emotional music generation system using Recurrent Neural Network
Dec 16, 2021
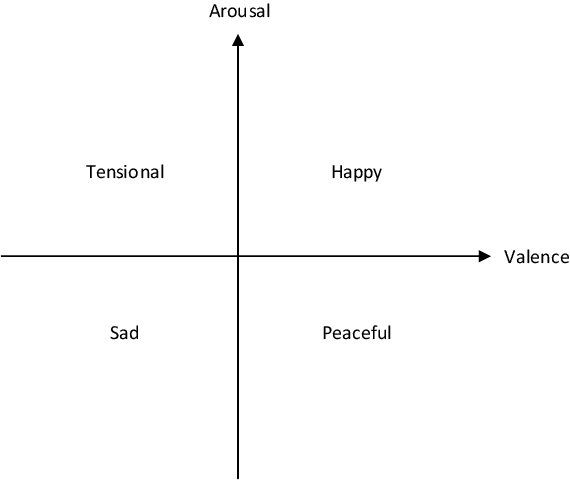
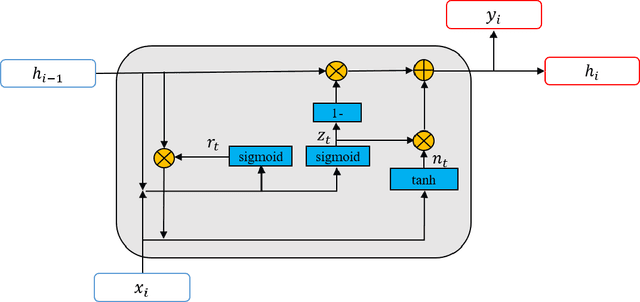
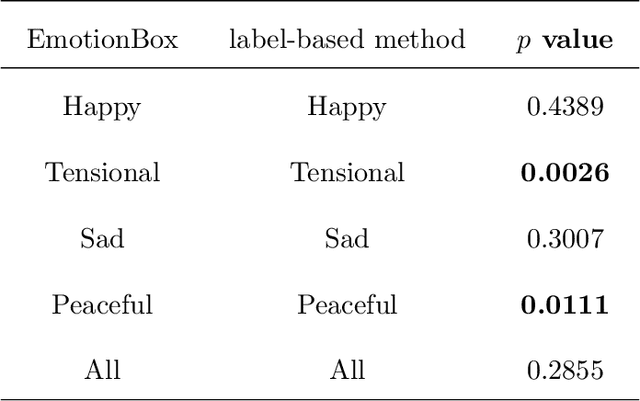
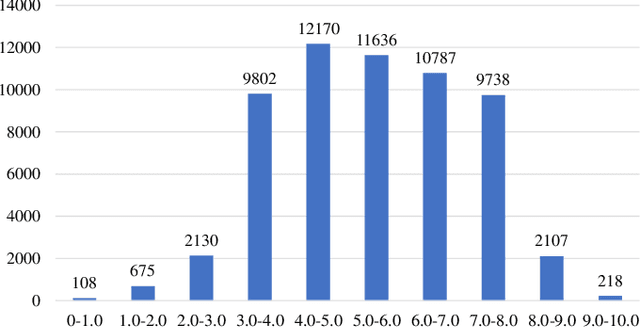
With the development of deep neural networks, automatic music composition has made great progress. Although emotional music can evoke listeners' different emotions and it is important for artistic expression, only few researches have focused on generating emotional music. This paper presents EmotionBox -an music-element-driven emotional music generator that is capable of composing music given a specific emotion, where this model does not require a music dataset labeled with emotions. Instead, pitch histogram and note density are extracted as features that represent mode and tempo respectively to control music emotions. The subjective listening tests show that the Emotionbox has a more competitive and balanced performance in arousing a specified emotion than the emotion-label-based method.
Novelty-Driven Binary Particle Swarm Optimisation for Truss Optimisation Problems
Dec 15, 2021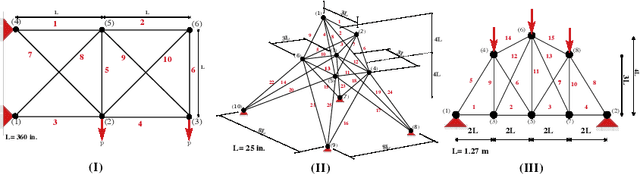
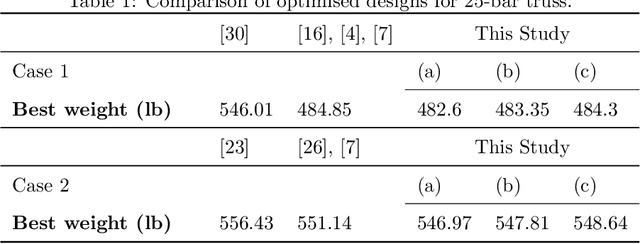
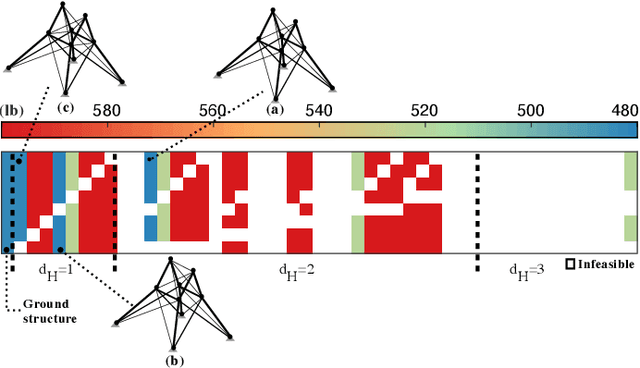

Topology optimisation of trusses can be formulated as a combinatorial and multi-modal problem in which locating distinct optimal designs allows practitioners to choose the best design based on their preferences. Bilevel optimisation has been successfully applied to truss optimisation to consider topology and sizing in upper and lower levels, respectively. We introduce exact enumeration to rigorously analyse the topology search space and remove randomness for small problems. We also propose novelty-driven binary particle swarm optimisation for bigger problems to discover new designs at the upper level by maximising novelty. For the lower level, we employ a reliable evolutionary optimiser to tackle the layout configuration aspect of the problem. We consider truss optimisation problem instances where designers need to select the size of bars from a discrete set with respect to practice code constraints. Our experimental investigations show that our approach outperforms the current state-of-the-art methods and it obtains multiple high-quality solutions.
Noise-robust blind reverberation time estimation using noise-aware time-frequency masking
Dec 09, 2021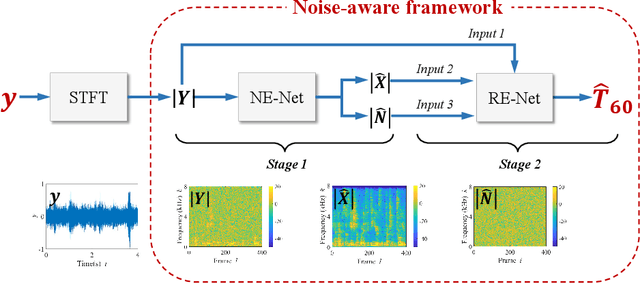

The reverberation time is one of the most important parameters used to characterize the acoustic property of an enclosure. In real-world scenarios, it is much more convenient to estimate the reverberation time blindly from recorded speech compared to the traditional acoustic measurement techniques using professional measurement instruments. However, the recorded speech is often corrupted by noise, which has a detrimental effect on the estimation accuracy of the reverberation time. To address this issue, this paper proposes a two-stage blind reverberation time estimation method based on noise-aware time-frequency masking. This proposed method has a good ability to distinguish the reverberation tails from the noise, thus improving the estimation accuracy of reverberation time in noisy scenarios. The simulated and real-world acoustic experimental results show that the proposed method significantly outperforms other methods in challenging scenarios.
Enhancing Column Generation by a Machine-Learning-Based Pricing Heuristic for Graph Coloring
Dec 08, 2021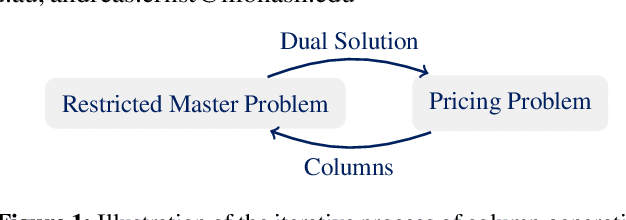


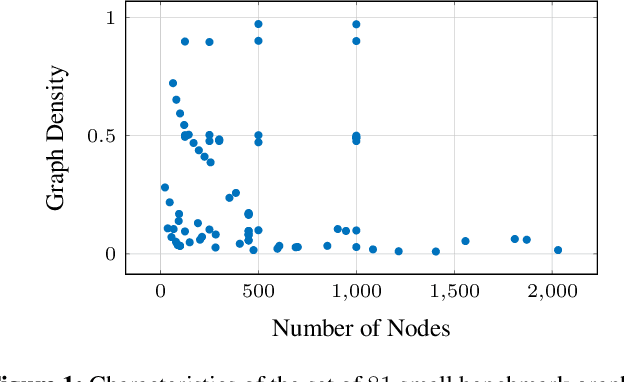
Column Generation (CG) is an effective method for solving large-scale optimization problems. CG starts by solving a sub-problem with a subset of columns (i.e., variables) and gradually includes new columns that can improve the solution of the current subproblem. The new columns are generated as needed by repeatedly solving a pricing problem, which is often NP-hard and is a bottleneck of the CG approach. To tackle this, we propose a Machine-Learning-based Pricing Heuristic (MLPH)that can generate many high-quality columns efficiently. In each iteration of CG, our MLPH leverages an ML model to predict the optimal solution of the pricing problem, which is then used to guide a sampling method to efficiently generate multiple high-quality columns. Using the graph coloring problem, we empirically show that MLPH significantly enhancesCG as compared to six state-of-the-art methods, and the improvement in CG can lead to substantially better performance of the branch-and-price exact method.
Embedding and Beamforming: All-neural Causal Beamformer for Multichannel Speech Enhancement
Sep 02, 2021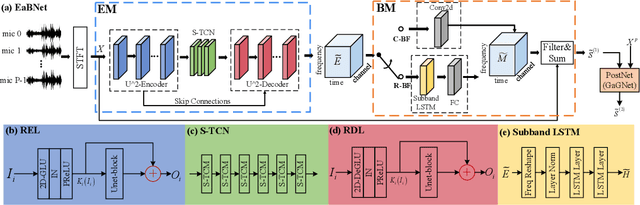
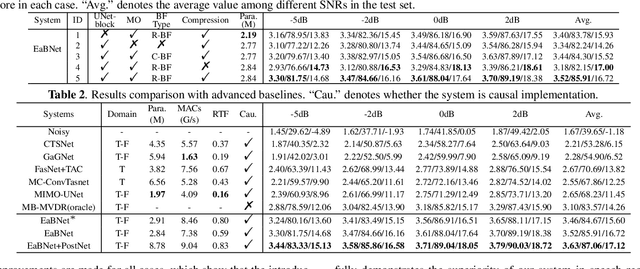
The spatial covariance matrix has been considered to be significant for beamformers. Standing upon the intersection of traditional beamformers and deep neural networks, we propose a causal neural beamformer paradigm called Embedding and Beamforming, and two core modules are designed accordingly, namely EM and BM. For EM, instead of estimating spatial covariance matrix explicitly, the 3-D embedding tensor is learned with the network, where both spectral and spatial discriminative information can be represented. For BM, a network is directly leveraged to derive the beamforming weights so as to implement filter-and-sum operation. To further improve the speech quality, a post-processing module is introduced to further suppress the residual noise. Based on the DNS-Challenge dataset, we conduct the experiments for multichannel speech enhancement and the results show that the proposed system outperforms previous advanced baselines by a large margin in multiple evaluation metrics.
Unbiased IoU for Spherical Image Object Detection
Aug 18, 2021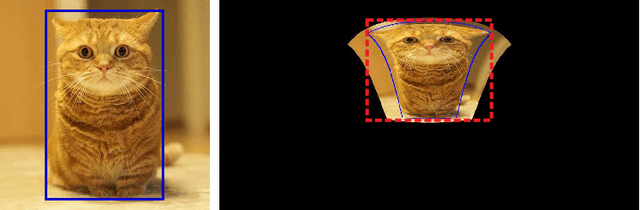
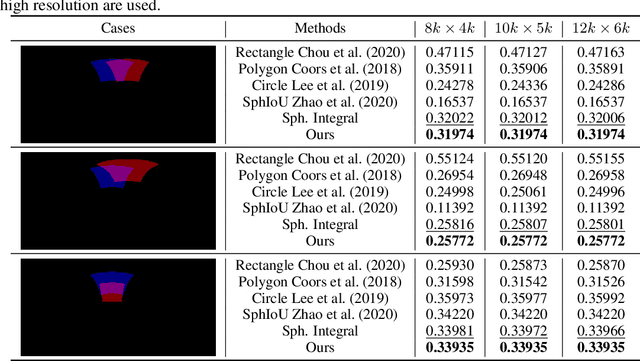
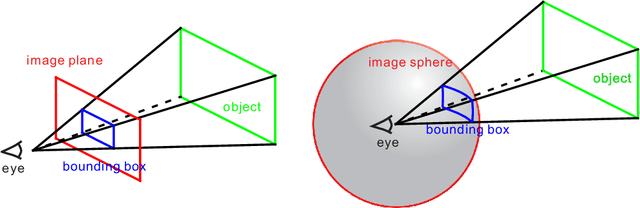

As one of the most fundamental and challenging problems in computer vision, object detection tries to locate object instances and find their categories in natural images. The most important step in the evaluation of object detection algorithm is calculating the intersection-over-union (IoU) between the predicted bounding box and the ground truth one. Although this procedure is well-defined and solved for planar images, it is not easy for spherical image object detection. Existing methods either compute the IoUs based on biased bounding box representations or make excessive approximations, thus would give incorrect results. In this paper, we first identify that spherical rectangles are unbiased bounding boxes for objects in spherical images, and then propose an analytical method for IoU calculation without any approximations. Based on the unbiased representation and calculation, we also present an anchor free object detection algorithm for spherical images. The experiments on two spherical object detection datasets show that the proposed method can achieve better performance than existing methods.