 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
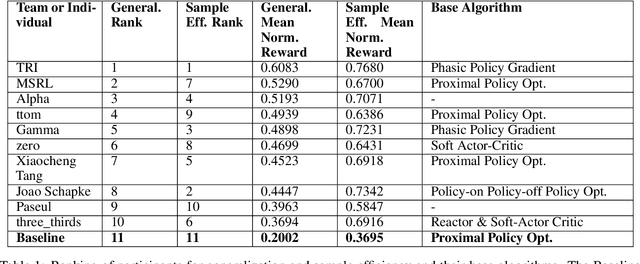
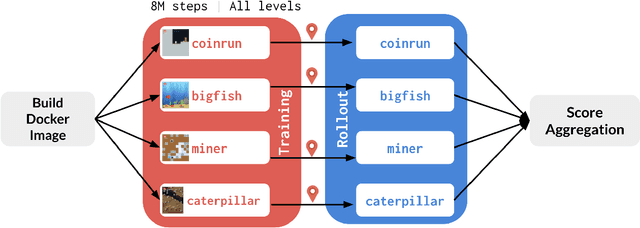
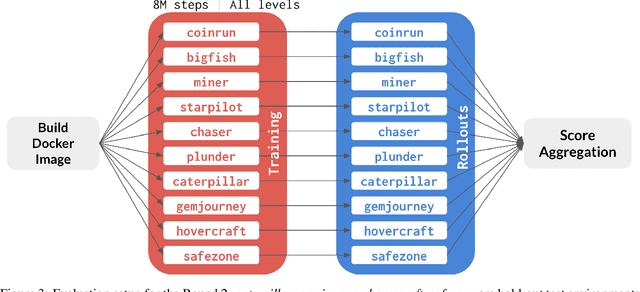
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.
Real-world Ride-hailing Vehicle Repositioning using Deep Reinforcement Learning
Mar 08, 2021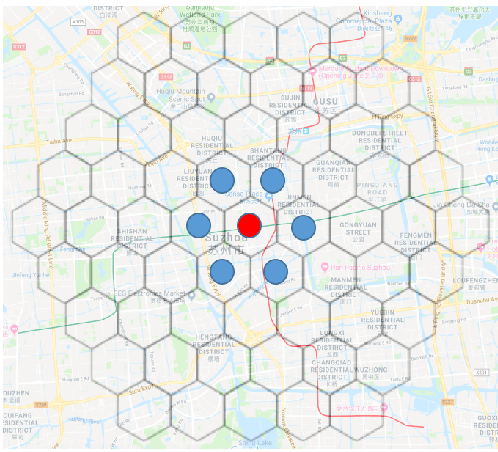
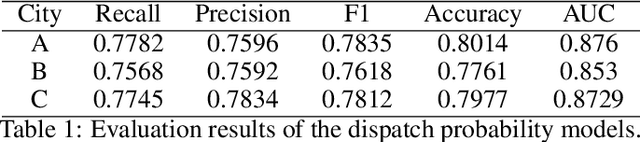
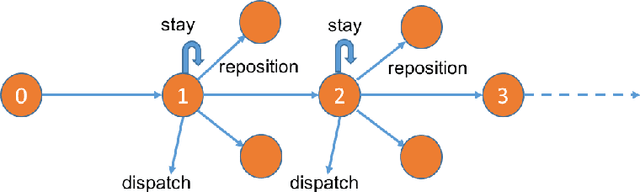

We present a new practical framework based on deep reinforcement learning and decision-time planning for real-world vehicle repositioning on ride-hailing (a type of mobility-on-demand, MoD) platforms. Our approach learns the spatiotemporal state-value function using a batch training algorithm with deep value networks. The optimal repositioning action is generated on-demand through value-based policy search, which combines planning and bootstrapping with the value networks. For the large-fleet problems, we develop several algorithmic features that we incorporate into our framework and that we demonstrate to induce coordination among the algorithmically-guided vehicles. We benchmark our algorithm with baselines in a ride-hailing simulation environment to demonstrate its superiority in improving income efficiency meausred by income-per-hour. We have also designed and run a real-world experiment program with regular drivers on a major ride-hailing platform. We have observed significantly positive results on key metrics comparing our method with experienced drivers who performed idle-time repositioning based on their own expertise.
DrNAS: Dirichlet Neural Architecture Search
Jun 19, 2020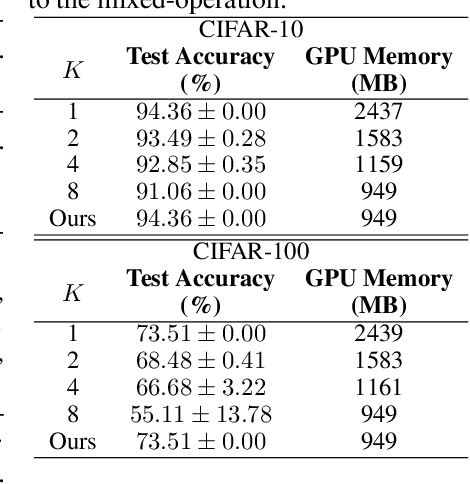

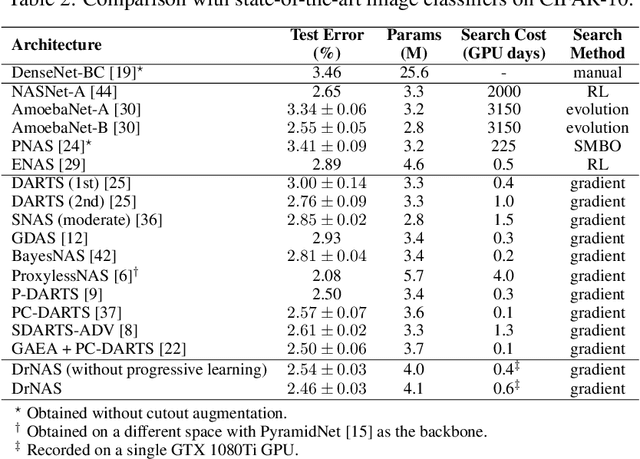
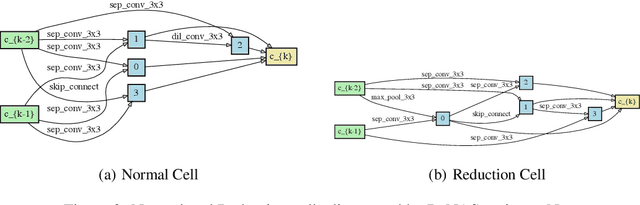
This paper proposes a novel differentiable architecture search method by formulating it into a distribution learning problem. We treat the continuously relaxed architecture mixing weight as random variables, modeled by Dirichlet distribution. With recently developed pathwise derivatives, the Dirichlet parameters can be easily optimized with gradient-based optimizer in an end-to-end manner. This formulation improves the generalization ability and induces stochasticity that naturally encourages exploration in the search space. Furthermore, to alleviate the large memory consumption of differentiable NAS, we propose a simple yet effective progressive learning scheme that enables searching directly on large-scale tasks, eliminating the gap between search and evaluation phases. Extensive experiments demonstrate the effectiveness of our method. Specifically, we obtain a test error of 2.46% for CIFAR-10, 23.7% for ImageNet under the mobile setting. On NAS-Bench-201, we also achieve state-of-the-art results on all three datasets and provide insights for the effective design of neural architecture search algorithms.
Deep Reinforcement Learning for Multi-Driver Vehicle Dispatching and Repositioning Problem
Nov 25, 2019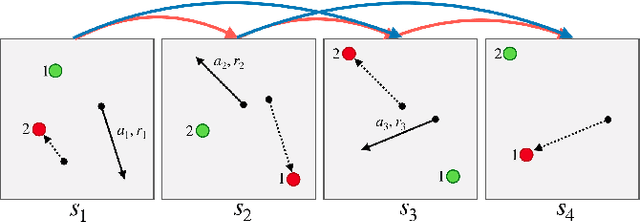
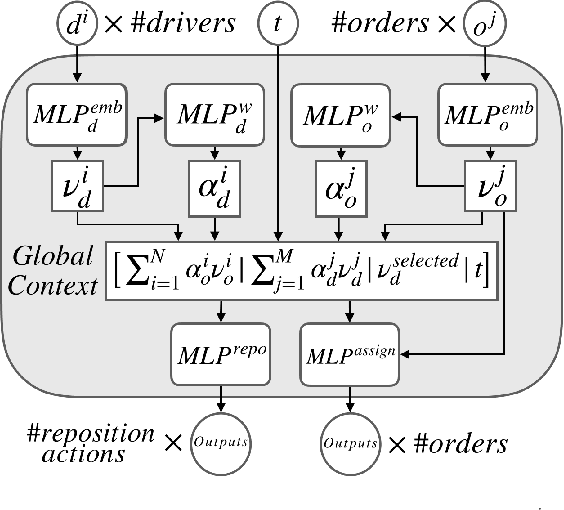
Order dispatching and driver repositioning (also known as fleet management) in the face of spatially and temporally varying supply and demand are central to a ride-sharing platform marketplace. Hand-crafting heuristic solutions that account for the dynamics in these resource allocation problems is difficult, and may be better handled by an end-to-end machine learning method. Previous works have explored machine learning methods to the problem from a high-level perspective, where the learning method is responsible for either repositioning the drivers or dispatching orders, and as a further simplification, the drivers are considered independent agents maximizing their own reward functions. In this paper we present a deep reinforcement learning approach for tackling the full fleet management and dispatching problems. In addition to treating the drivers as individual agents, we consider the problem from a system-centric perspective, where a central fleet management agent is responsible for decision-making for all drivers.
Practical Inexact Proximal Quasi-Newton Method with Global Complexity Analysis
Jul 14, 2015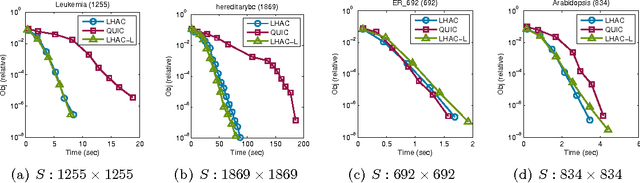

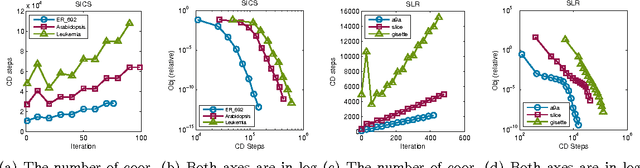
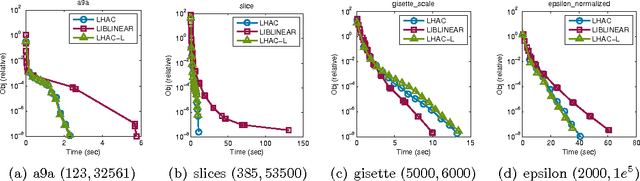
Recently several methods were proposed for sparse optimization which make careful use of second-order information [10, 28, 16, 3] to improve local convergence rates. These methods construct a composite quadratic approximation using Hessian information, optimize this approximation using a first-order method, such as coordinate descent and employ a line search to ensure sufficient descent. Here we propose a general framework, which includes slightly modified versions of existing algorithms and also a new algorithm, which uses limited memory BFGS Hessian approximations, and provide a novel global convergence rate analysis, which covers methods that solve subproblems via coordinate descent.
HIPAD - A Hybrid Interior-Point Alternating Direction algorithm for knowledge-based SVM and feature selection
Nov 16, 2014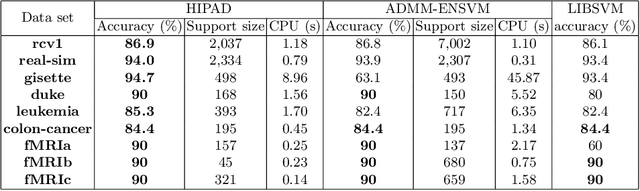

We consider classification tasks in the regime of scarce labeled training data in high dimensional feature space, where specific expert knowledge is also available. We propose a new hybrid optimization algorithm that solves the elastic-net support vector machine (SVM) through an alternating direction method of multipliers in the first phase, followed by an interior-point method for the classical SVM in the second phase. Both SVM formulations are adapted to knowledge incorporation. Our proposed algorithm addresses the challenges of automatic feature selection, high optimization accuracy, and algorithmic flexibility for taking advantage of prior knowledge. We demonstrate the effectiveness and efficiency of our algorithm and compare it with existing methods on a collection of synthetic and real-world data.
Efficiently Using Second Order Information in Large l1 Regularization Problems
Mar 27, 2013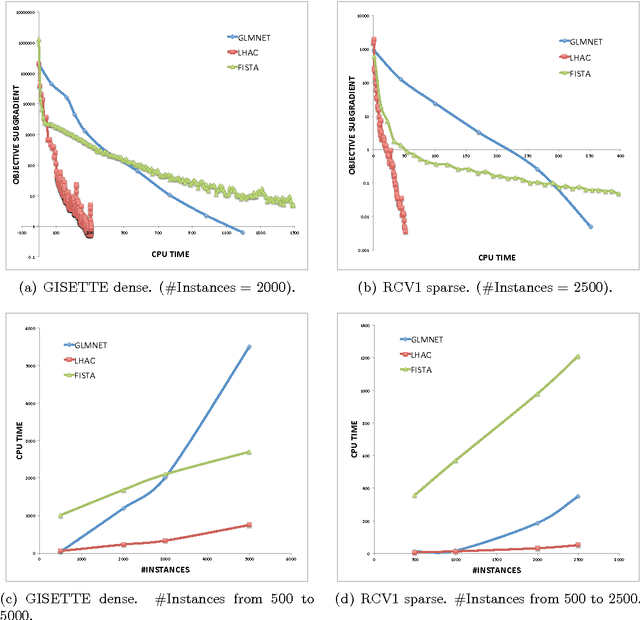
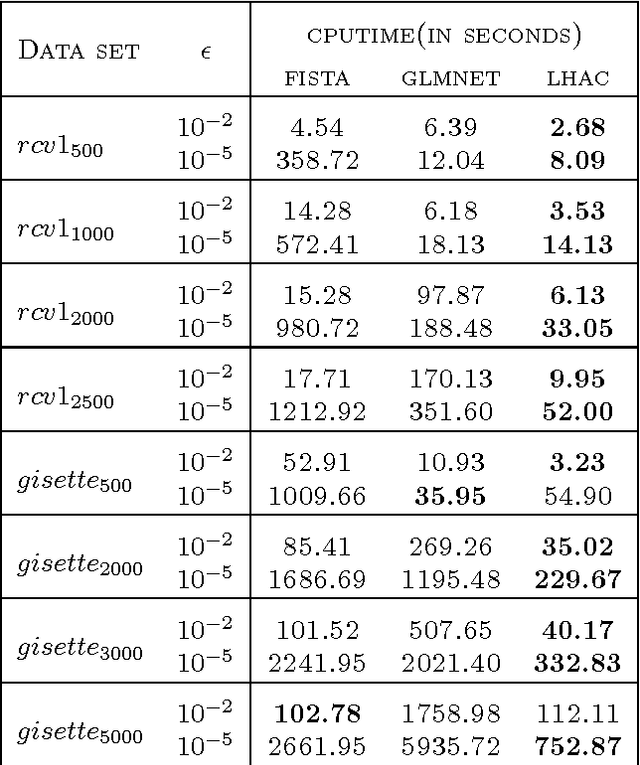
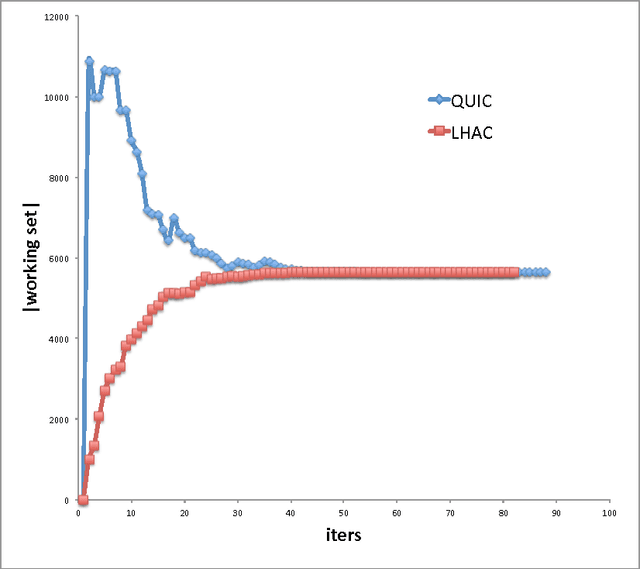
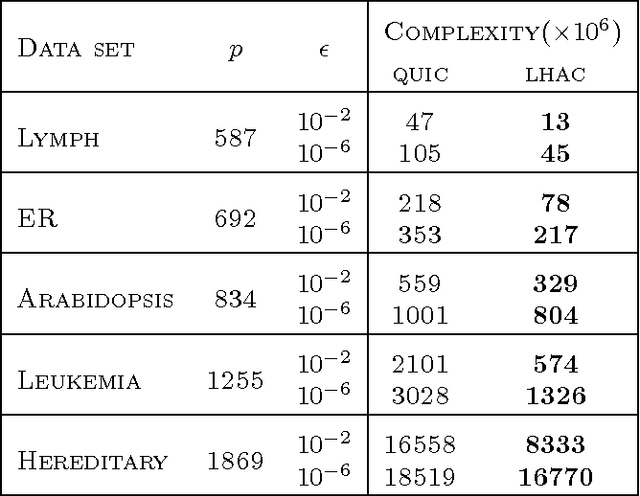
We propose a novel general algorithm LHAC that efficiently uses second-order information to train a class of large-scale l1-regularized problems. Our method executes cheap iterations while achieving fast local convergence rate by exploiting the special structure of a low-rank matrix, constructed via quasi-Newton approximation of the Hessian of the smooth loss function. A greedy active-set strategy, based on the largest violations in the dual constraints, is employed to maintain a working set that iteratively estimates the complement of the optimal active set. This allows for smaller size of subproblems and eventually identifies the optimal active set. Empirical comparisons confirm that LHAC is highly competitive with several recently proposed state-of-the-art specialized solvers for sparse logistic regression and sparse inverse covariance matrix selection.