 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Multimodal Reinforcement Learning with Modality Alignment and Importance Enhancement
Feb 18, 2023Many real-world applications require an agent to make robust and deliberate decisions with multimodal information (e.g., robots with multi-sensory inputs). However, it is very challenging to train the agent via reinforcement learning (RL) due to the heterogeneity and dynamic importance of different modalities. Specifically, we observe that these issues make conventional RL methods difficult to learn a useful state representation in the end-to-end training with multimodal information. To address this, we propose a novel multimodal RL approach that can do multimodal alignment and importance enhancement according to their similarity and importance in terms of RL tasks respectively. By doing so, we are able to learn an effective state representation and consequentially improve the RL training process. We test our approach on several multimodal RL domains, showing that it outperforms state-of-the-art methods in terms of learning speed and policy quality.
Multi-label Relation Modeling in Facial Action Units Detection
Feb 08, 2020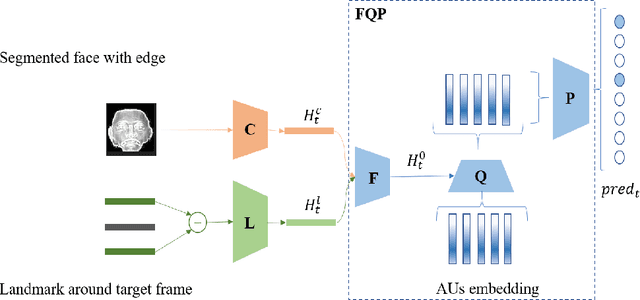
This paper describes an approach to the facial action units detections. The involved action units (AU) include AU1 (Inner Brow Raiser), AU2 (Outer Brow Raiser), AU4 (Brow Lowerer), AU6 (Cheek Raise), AU12 (Lip Corner Puller), AU15 (Lip Corner Depressor), AU20 (Lip Stretcher), and AU25 (Lip Part). Our work relies on the dataset released by the FG-2020 Competition: Affective Behavior Analysis In-the-Wild (ABAW). The proposed method consists of the data preprocessing, the feature extraction and the AU classification. The data preprocessing includes the detection of face texture and landmarks. The texture static and landmark dynamic features are extracted through neural networks and then fused as the feature latent representation. Finally, the fused feature is taken as the initial hidden state of a recurrent neural network with a trainable lookup AU table. The output of the RNN is the results of AU classification. The detected accuracy is evaluated with 0.5$\times$accuracy + 0.5$\times$F1. Our method achieve 0.56 with the validation data that is specified by the organization committee.