 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation
May 20, 2026Deep research, in which an agent searches the open web, collects evidence, and derives an answer through extended reasoning, is a prominent use case for frontier language models. Frontier deep research products score high on existing benchmarks, making it difficult to distinguish their capabilities from current evaluation data alone. We introduce DeepWeb-Bench, a deep research benchmark that is substantially harder than existing benchmarks for the current frontier. Difficulty comes from three properties of the data itself: each task requires massive evidence collection, cross-source reconciliation, and long-horizon multi-step derivation. We represent these three sources of difficulty as four capability families (Retrieval, Derivation, Reasoning, and Calibration) and report results sliced by family. Every reference answer is accompanied by a source-provenance record with four disclosure levels and cross-source checks where available, making scores easier to audit against the underlying evidence. We evaluate DeepWeb-Bench on nine frontier models and report three findings: (1) retrieval is not the bottleneck, as retrieval failures account for only 12-14% of errors while derivation and calibration failures account for over 70%; (2) strong and weak models fail in qualitatively different ways, with strong models' errors dominated by incomplete derivation and weak models' by hallucinated precision; and (3) models exhibit genuine specialization across domains, with cross-model agreement of only rho = 0.61 and per-case disagreement reaching 18.8 percentage points. The public benchmark release includes the data, rubrics, and evaluation code.
ViDR: Grounding Multimodal Deep Research Reports in Source Visual Evidence
May 13, 2026Recent deep research systems have improved the ability of large language models to produce long, grounded reports through iterative retrieval and reasoning. However, most text-centered systems rely mainly on textual evidence, while multimodal systems often retrieve images only weakly or generate charts themselves, leaving source figures underused as evidence. We present ViDR, a multimodal deep research framework that grounds long-form reports in source figures. ViDR treats source figures as retrievable, interpretable, routable, and verifiable evidence objects, while still generating analytical charts when needed. It builds an evidence-indexed outline linking claims to textual and visual evidence, refines noisy web images into source-figure evidence atoms through context-aware filtering, outline-aware reranking, and VLM-based visual analysis, and generates each section with section-specific evidence. ViDR further validates visual references to reduce hallucinated or misplaced figures. We also introduce MMR Bench+, a benchmark for evaluating visual evidence use in deep research reports, covering source-figure retrieval, placement, interpretation, verifiability, and analytical chart generation. Experiments show that ViDR improves overall report quality, source-figure integration, and verifiability over strong commercial and open-source baselines. These results suggest that source visual evidence is important for multimodal deep research, as it strengthens evidential grounding, visual support, and report verifiability.
M3-BENCH: Process-Aware Evaluation of LLM Agents Social Behaviors in Mixed-Motive Games
Jan 13, 2026As the capabilities of large language model (LLM) agents continue to advance, their advanced social behaviors, such as cooperation, deception, and collusion, call for systematic evaluation. However, existing benchmarks often emphasize a single capability dimension or rely solely on behavioral outcomes, overlooking rich process information from agents' decision reasoning and communicative interactions. To address this gap, we propose M3-Bench, a multi-stage benchmark for mixed-motive games, together with a process-aware evaluation framework that conducts synergistic analysis across three modules: BTA (Behavioral Trajectory Analysis), RPA (Reasoning Process Analysis), and CCA (Communication Content Analysis). Furthermore, we integrate the Big Five personality model and Social Exchange Theory to aggregate multi-dimensional evidence into interpretable social behavior portraits, thereby characterizing agents' personality traits and capability profiles beyond simple task scores or outcome-based metrics. Experimental results show that M3-Bench can reliably distinguish diverse social behavior competencies across models, and it reveals that some models achieve seemingly reasonable behavioral outcomes while exhibiting pronounced inconsistencies in their reasoning and communication.
MDAgent2: Large Language Model for Code Generation and Knowledge Q&A in Molecular Dynamics
Jan 07, 2026Molecular dynamics (MD) simulations are essential for understanding atomic-scale behaviors in materials science, yet writing LAMMPS scripts remains highly specialized and time-consuming tasks. Although LLMs show promise in code generation and domain-specific question answering, their performance in MD scenarios is limited by scarce domain data, the high deployment cost of state-of-the-art LLMs, and low code executability. Building upon our prior MDAgent, we present MDAgent2, the first end-to-end framework capable of performing both knowledge Q&A and code generation within the MD domain. We construct a domain-specific data-construction pipeline that yields three high-quality datasets spanning MD knowledge, question answering, and code generation. Based on these datasets, we adopt a three stage post-training strategy--continued pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL)--to train two domain-adapted models, MD-Instruct and MD-Code. Furthermore, we introduce MD-GRPO, a closed-loop RL method that leverages simulation outcomes as reward signals and recycles low-reward trajectories for continual refinement. We further build MDAgent2-RUNTIME, a deployable multi-agent system that integrates code generation, execution, evaluation, and self-correction. Together with MD-EvalBench proposed in this work, the first benchmark for LAMMPS code generation and question answering, our models and system achieve performance surpassing several strong baselines.This work systematically demonstrates the adaptability and generalization capability of large language models in industrial simulation tasks, laying a methodological foundation for automatic code generation in AI for Science and industrial-scale simulations. URL: https://github.com/FredericVAN/PKU_MDAgent2
IoDResearch: Deep Research on Private Heterogeneous Data via the Internet of Data
Oct 02, 2025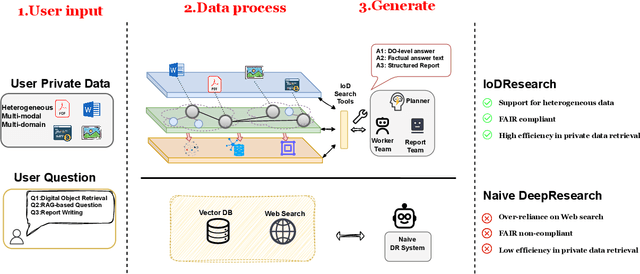
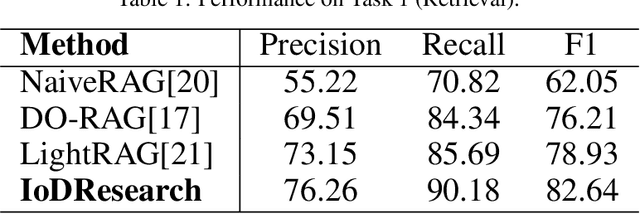
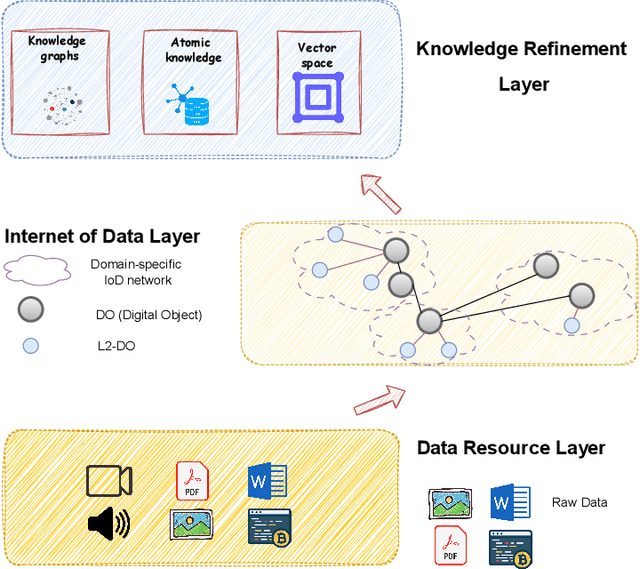
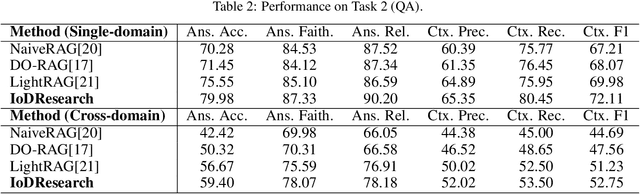
The rapid growth of multi-source, heterogeneous, and multimodal scientific data has increasingly exposed the limitations of traditional data management. Most existing DeepResearch (DR) efforts focus primarily on web search while overlooking local private data. Consequently, these frameworks exhibit low retrieval efficiency for private data and fail to comply with the FAIR principles, ultimately resulting in inefficiency and limited reusability. To this end, we propose IoDResearch (Internet of Data Research), a private data-centric Deep Research framework that operationalizes the Internet of Data paradigm. IoDResearch encapsulates heterogeneous resources as FAIR-compliant digital objects, and further refines them into atomic knowledge units and knowledge graphs, forming a heterogeneous graph index for multi-granularity retrieval. On top of this representation, a multi-agent system supports both reliable question answering and structured scientific report generation. Furthermore, we establish the IoD DeepResearch Benchmark to systematically evaluate both data representation and Deep Research capabilities in IoD scenarios. Experimental results on retrieval, QA, and report-writing tasks show that IoDResearch consistently surpasses representative RAG and Deep Research baselines. Overall, IoDResearch demonstrates the feasibility of private-data-centric Deep Research under the IoD paradigm, paving the way toward more trustworthy, reusable, and automated scientific discovery.