 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroGraph: Benchmarks for Graph Machine Learning in Brain Connectomics
Jun 25, 2023Machine learning provides a valuable tool for analyzing high-dimensional functional neuroimaging data, and is proving effective in predicting various neurological conditions, psychiatric disorders, and cognitive patterns. In functional Magnetic Resonance Imaging (MRI) research, interactions between brain regions are commonly modeled using graph-based representations. The potency of graph machine learning methods has been established across myriad domains, marking a transformative step in data interpretation and predictive modeling. Yet, despite their promise, the transposition of these techniques to the neuroimaging domain remains surprisingly under-explored due to the expansive preprocessing pipeline and large parameter search space for graph-based datasets construction. In this paper, we introduce NeuroGraph, a collection of graph-based neuroimaging datasets that span multiple categories of behavioral and cognitive traits. We delve deeply into the dataset generation search space by crafting 35 datasets within both static and dynamic contexts, running in excess of 15 baseline methods for benchmarking. Additionally, we provide generic frameworks for learning on dynamic as well as static graphs. Our extensive experiments lead to several key observations. Notably, using correlation vectors as node features, incorporating larger number of regions of interest, and employing sparser graphs lead to improved performance. To foster further advancements in graph-based data driven Neuroimaging, we offer a comprehensive open source Python package that includes the datasets, baseline implementations, model training, and standard evaluation. The package is publicly accessible at https://anwar-said.github.io/anwarsaid/neurograph.html .
Learning-Based Heuristic for Combinatorial Optimization of the Minimum Dominating Set Problem using Graph Convolutional Networks
Jun 06, 2023A dominating set of a graph $\mathcal{G=(V, E)}$ is a subset of vertices $S\subseteq\mathcal{V}$ such that every vertex $v\in \mathcal{V} \setminus S$ outside the dominating set is adjacent to a vertex $u\in S$ within the set. The minimum dominating set problem seeks to find a dominating set of minimum cardinality and is a well-established NP-hard combinatorial optimization problem. We propose a novel learning-based heuristic approach to compute solutions for the minimum dominating set problem using graph convolutional networks. We conduct an extensive experimental evaluation of the proposed method on a combination of randomly generated graphs and real-world graph datasets. Our results indicate that the proposed learning-based approach can outperform a classical greedy approximation algorithm. Furthermore, we demonstrate the generalization capability of the graph convolutional network across datasets and its ability to scale to graphs of higher order than those on which it was trained. Finally, we utilize the proposed learning-based heuristic in an iterative greedy algorithm, achieving state-of-the-art performance in the computation of dominating sets.
Scaling Up 3D Kernels with Bayesian Frequency Re-parameterization for Medical Image Segmentation
Mar 10, 2023



With the inspiration of vision transformers, the concept of depth-wise convolution revisits to provide a large Effective Receptive Field (ERF) using Large Kernel (LK) sizes for medical image segmentation. However, the segmentation performance might be saturated and even degraded as the kernel sizes scaled up (e.g., $21\times 21\times 21$) in a Convolutional Neural Network (CNN). We hypothesize that convolution with LK sizes is limited to maintain an optimal convergence for locality learning. While Structural Re-parameterization (SR) enhances the local convergence with small kernels in parallel, optimal small kernel branches may hinder the computational efficiency for training. In this work, we propose RepUX-Net, a pure CNN architecture with a simple large kernel block design, which competes favorably with current network state-of-the-art (SOTA) (e.g., 3D UX-Net, SwinUNETR) using 6 challenging public datasets. We derive an equivalency between kernel re-parameterization and the branch-wise variation in kernel convergence. Inspired by the spatial frequency in the human visual system, we extend to vary the kernel convergence into element-wise setting and model the spatial frequency as a Bayesian prior to re-parameterize convolutional weights during training. Specifically, a reciprocal function is leveraged to estimate a frequency-weighted value, which rescales the corresponding kernel element for stochastic gradient descent. From the experimental results, RepUX-Net consistently outperforms 3D SOTA benchmarks with internal validation (FLARE: 0.929 to 0.944), external validation (MSD: 0.901 to 0.932, KiTS: 0.815 to 0.847, LiTS: 0.933 to 0.949, TCIA: 0.736 to 0.779) and transfer learning (AMOS: 0.880 to 0.911) scenarios in Dice Score.
Open Set Recognition using Vision Transformer with an Additional Detection Head
Mar 16, 2022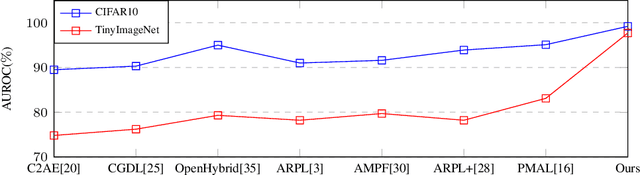
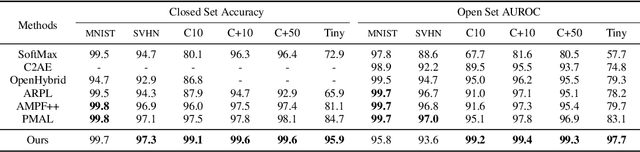
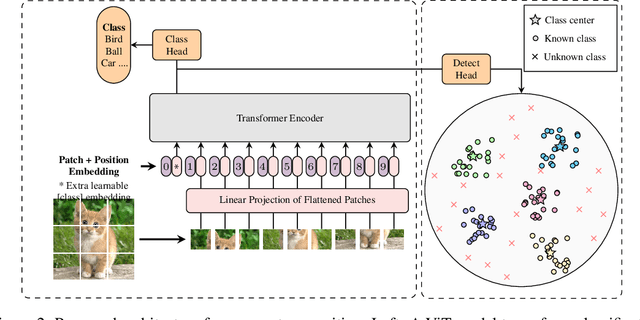
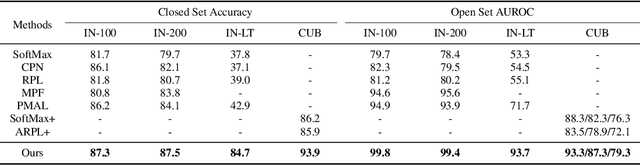
Deep neural networks have demonstrated prominent capacities for image classification tasks in a closed set setting, where the test data come from the same distribution as the training data. However, in a more realistic open set scenario, traditional classifiers with incomplete knowledge cannot tackle test data that are not from the training classes. Open set recognition (OSR) aims to address this problem by both identifying unknown classes and distinguishing known classes simultaneously. In this paper, we propose a novel approach to OSR that is based on the vision transformer (ViT) technique. Specifically, our approach employs two separate training stages. First, a ViT model is trained to perform closed set classification. Then, an additional detection head is attached to the embedded features extracted by the ViT, trained to force the representations of known data to class-specific clusters compactly. Test examples are identified as known or unknown based on their distance to the cluster centers. To the best of our knowledge, this is the first time to leverage ViT for the purpose of OSR, and our extensive evaluation against several OSR benchmark datasets reveals that our approach significantly outperforms other baseline methods and obtains new state-of-the-art performance.
Reliable Probability Intervals For Classification Using Inductive Venn Predictors Based on Distance Learning
Oct 07, 2021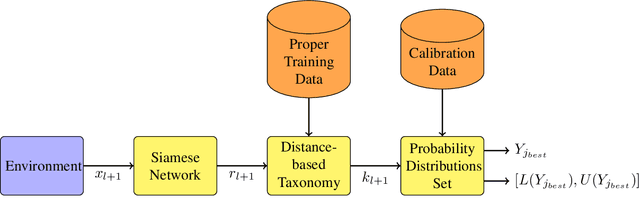
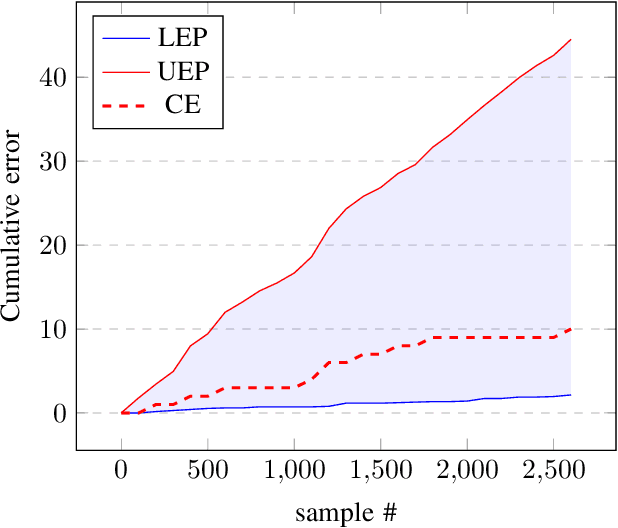

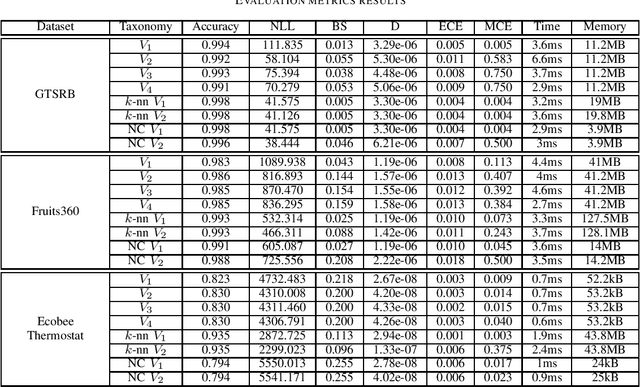
Deep neural networks are frequently used by autonomous systems for their ability to learn complex, non-linear data patterns and make accurate predictions in dynamic environments. However, their use as black boxes introduces risks as the confidence in each prediction is unknown. Different frameworks have been proposed to compute accurate confidence measures along with the predictions but at the same time introduce a number of limitations like execution time overhead or inability to be used with high-dimensional data. In this paper, we use the Inductive Venn Predictors framework for computing probability intervals regarding the correctness of each prediction in real-time. We propose taxonomies based on distance metric learning to compute informative probability intervals in applications involving high-dimensional inputs. Empirical evaluation on image classification and botnet attacks detection in Internet-of-Things (IoT) applications demonstrates improved accuracy and calibration. The proposed method is computationally efficient, and therefore, can be used in real-time.
* Published in IEEE International Conference on Omni-Layer Intelligent Systems (COINS), 2021
Improving Prediction Confidence in Learning-Enabled Autonomous Systems
Oct 07, 2021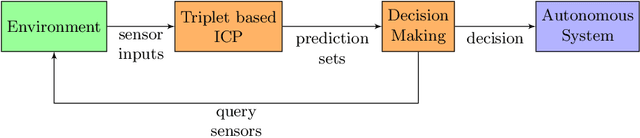

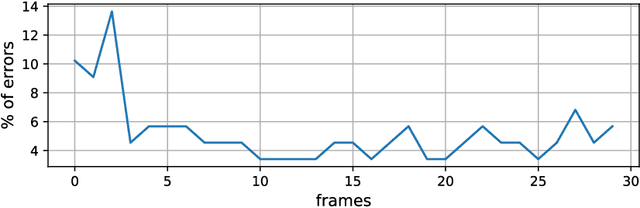

Autonomous systems use extensively learning-enabled components such as deep neural networks (DNNs) for prediction and decision making. In this paper, we utilize a feedback loop between learning-enabled components used for classification and the sensors of an autonomous system in order to improve the confidence of the predictions. We design a classifier using Inductive Conformal Prediction (ICP) based on a triplet network architecture in order to learn representations that can be used to quantify the similarity between test and training examples. The method allows computing confident set predictions with an error rate predefined using a selected significance level. A feedback loop that queries the sensors for a new input is used to further refine the predictions and increase the classification accuracy. The method is computationally efficient, scalable to high-dimensional inputs, and can be executed in a feedback loop with the system in real-time. The approach is evaluated using a traffic sign recognition dataset and the results show that the error rate is reduced.
* Published in Dynamic Data Driven Applications Systems. DDDAS 2020
Assurance Monitoring of Learning Enabled Cyber-Physical Systems Using Inductive Conformal Prediction based on Distance Learning
Oct 07, 2021Machine learning components such as deep neural networks are used extensively in Cyber-Physical Systems (CPS). However, such components may introduce new types of hazards that can have disastrous consequences and need to be addressed for engineering trustworthy systems. Although deep neural networks offer advanced capabilities, they must be complemented by engineering methods and practices that allow effective integration in CPS. In this paper, we proposed an approach for assurance monitoring of learning-enabled CPS based on the conformal prediction framework. In order to allow real-time assurance monitoring, the approach employs distance learning to transform high-dimensional inputs into lower size embedding representations. By leveraging conformal prediction, the approach provides well-calibrated confidence and ensures a bounded small error rate while limiting the number of inputs for which an accurate prediction cannot be made. We demonstrate the approach using three data sets of mobile robot following a wall, speaker recognition, and traffic sign recognition. The experimental results demonstrate that the error rates are well-calibrated while the number of alarms is very small. Further, the method is computationally efficient and allows real-time assurance monitoring of CPS.
* Published in Artificial Intelligence for Engineering Design, Analysis and Manufacturing. arXiv admin note: text overlap with arXiv:2001.05014
Detection of Dataset Shifts in Learning-Enabled Cyber-Physical Systems using Variational Autoencoder for Regression
Apr 14, 2021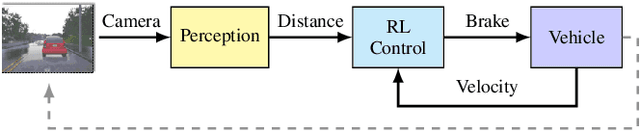
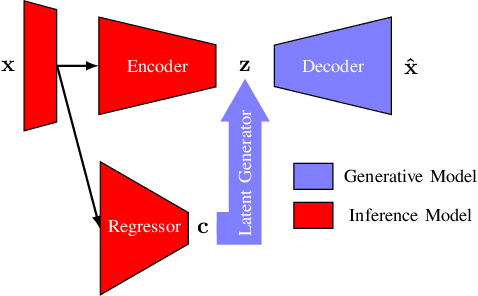
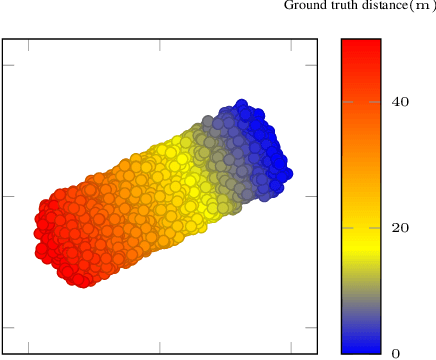
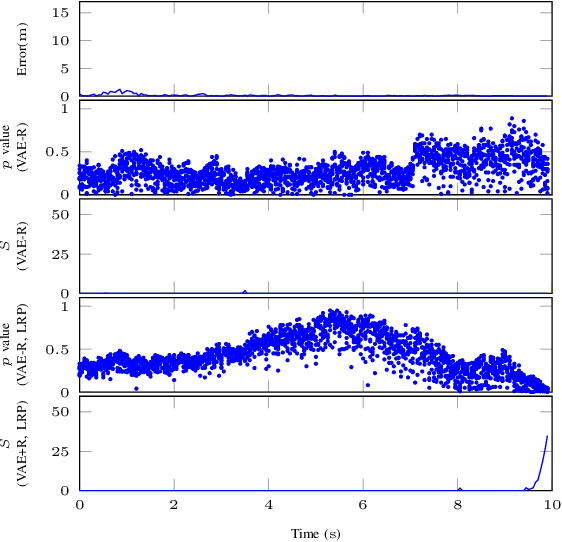
Cyber-physical systems (CPSs) use learning-enabled components (LECs) extensively to cope with various complex tasks under high-uncertainty environments. However, the dataset shifts between the training and testing phase may lead the LECs to become ineffective to make large-error predictions, and further, compromise the safety of the overall system. In our paper, we first provide the formal definitions for different types of dataset shifts in learning-enabled CPS. Then, we propose an approach to detect the dataset shifts effectively for regression problems. Our approach is based on the inductive conformal anomaly detection and utilizes a variational autoencoder for regression model which enables the approach to take into consideration both LEC input and output for detecting dataset shifts. Additionally, in order to improve the robustness of detection, layer-wise relevance propagation (LRP) is incorporated into our approach. We demonstrate our approach by using an advanced emergency braking system implemented in an open-source simulator for self-driving cars. The evaluation results show that our approach can detect different types of dataset shifts with a small number of false alarms while the execution time is smaller than the sampling period of the system.
Byzantine Resilient Distributed Multi-Task Learning
Oct 25, 2020


Distributed multi-task learning provides significant advantages in multi-agent networks with heterogeneous data sources where agents aim to learn distinct but correlated models simultaneously. However, distributed algorithms for learning relatedness among tasks are not resilient in the presence of Byzantine agents. In this paper, we present an approach for Byzantine resilient distributed multi-task learning. We propose an efficient online weight assignment rule by measuring the accumulated loss using an agent's data and its neighbors' models. A small accumulated loss indicates a large similarity between the two tasks. In order to ensure the Byzantine resilience of the aggregation at a normal agent, we introduce a step for filtering out larger losses. We analyze the approach for convex models and show that normal agents converge resiliently towards their true targets. Further, an agent's learning performance using the proposed weight assignment rule is guaranteed to be at least as good as in the non-cooperative case as measured by the expected regret. Finally, we demonstrate the approach using three case studies, including regression and classification problems, and show that our method exhibits good empirical performance for non-convex models, such as convolutional neural networks.
Detecting Adversarial Examples in Learning-Enabled Cyber-Physical Systems using Variational Autoencoder for Regression
Mar 21, 2020
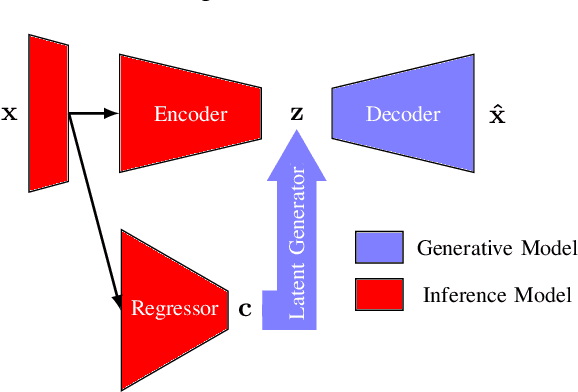
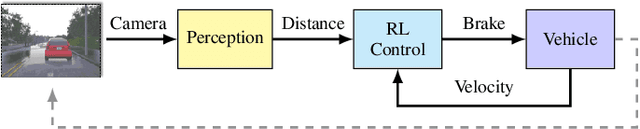
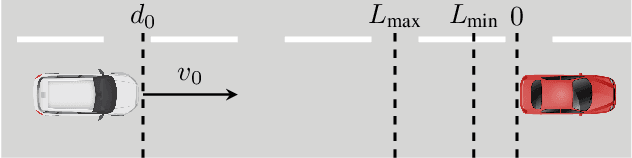
Learning-enabled components (LECs) are widely used in cyber-physical systems (CPS) since they can handle the uncertainty and variability of the environment and increase the level of autonomy. However, it has been shown that LECs such as deep neural networks (DNN) are not robust and adversarial examples can cause the model to make a false prediction. The paper considers the problem of efficiently detecting adversarial examples in LECs used for regression in CPS. The proposed approach is based on inductive conformal prediction and uses a regression model based on variational autoencoder. The architecture allows to take into consideration both the input and the neural network prediction for detecting adversarial, and more generally, out-of-distribution examples. We demonstrate the method using an advanced emergency braking system implemented in an open source simulator for self-driving cars where a DNN is used to estimate the distance to an obstacle. The simulation results show that the method can effectively detect adversarial examples with a short detection delay.