 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefVOS: A Closer Look at Referring Expressions for Video Object Segmentation
Oct 01, 2020

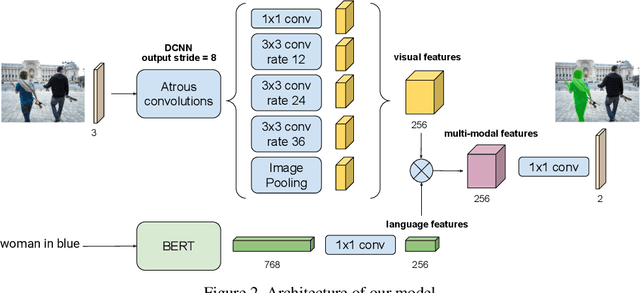
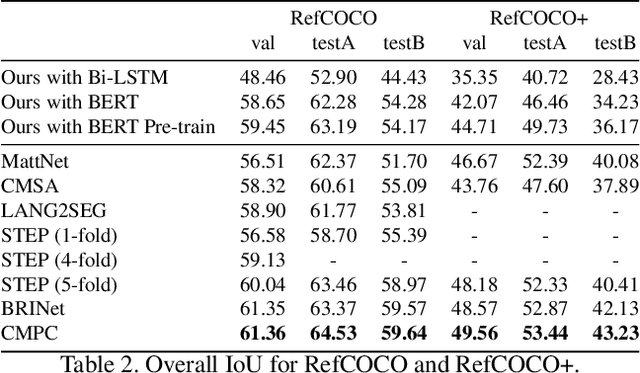
The task of video object segmentation with referring expressions (language-guided VOS) is to, given a linguistic phrase and a video, generate binary masks for the object to which the phrase refers. Our work argues that existing benchmarks used for this task are mainly composed of trivial cases, in which referents can be identified with simple phrases. Our analysis relies on a new categorization of the phrases in the DAVIS-2017 and Actor-Action datasets into trivial and non-trivial REs, with the non-trivial REs annotated with seven RE semantic categories. We leverage this data to analyze the results of RefVOS, a novel neural network that obtains competitive results for the task of language-guided image segmentation and state of the art results for language-guided VOS. Our study indicates that the major challenges for the task are related to understanding motion and static actions.
Mask-guided sample selection for Semi-Supervised Instance Segmentation
Aug 25, 2020
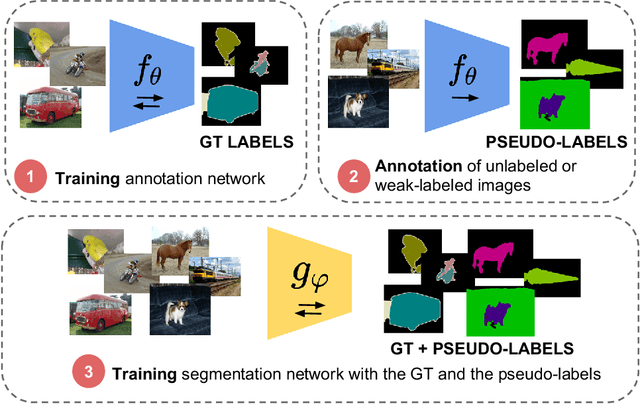
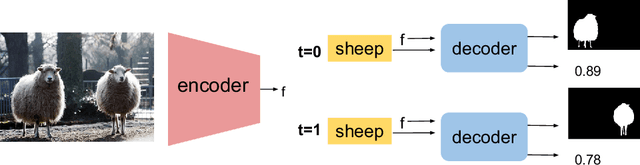
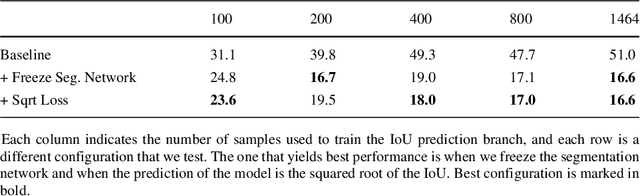
Image segmentation methods are usually trained with pixel-level annotations, which require significant human effort to collect. The most common solution to address this constraint is to implement weakly-supervised pipelines trained with lower forms of supervision, such as bounding boxes or scribbles. Another option are semi-supervised methods, which leverage a large amount of unlabeled data and a limited number of strongly-labeled samples. In this second setup, samples to be strongly-annotated can be selected randomly or with an active learning mechanism that chooses the ones that will maximize the model performance. In this work, we propose a sample selection approach to decide which samples to annotate for semi-supervised instance segmentation. Our method consists in first predicting pseudo-masks for the unlabeled pool of samples, together with a score predicting the quality of the mask. This score is an estimate of the Intersection Over Union (IoU) of the segment with the ground truth mask. We study which samples are better to annotate given the quality score, and show how our approach outperforms a random selection, leading to improved performance for semi-supervised instance segmentation with low annotation budgets.
How2Sign: A Large-scale Multimodal Dataset for Continuous American Sign Language
Aug 18, 2020
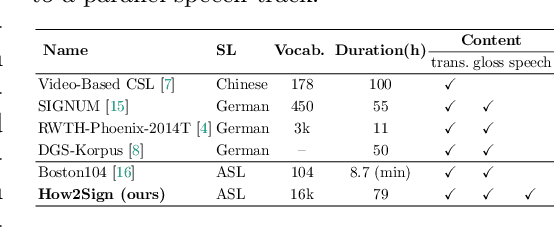
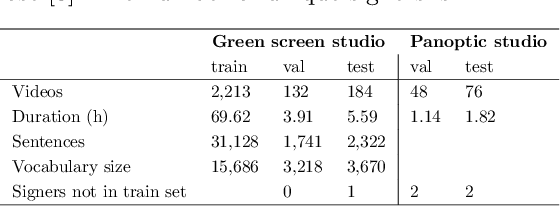
Sign Language is the primary means of communication for the majority of the Deaf community. One of the factors that has hindered the progress in the areas of automatic sign language recognition, generation, and translation is the absence of large annotated datasets, especially continuous sign language datasets, i.e. datasets that are annotated and segmented at the sentence or utterance level. Towards this end, in this work we introduce How2Sign, a work-in-progress dataset collection. How2Sign consists of a parallel corpus of 80 hours of sign language videos (collected with multi-view RGB and depth sensor data) with corresponding speech transcriptions and gloss annotations. In addition, a three-hour subset was further recorded in a geodesic dome setup using hundreds of cameras and sensors, which enables detailed 3D reconstruction and pose estimation and paves the way for vision systems to understand the 3D geometry of sign language.
Transcription-Enriched Joint Embeddings for Spoken Descriptions of Images and Videos
Jun 01, 2020
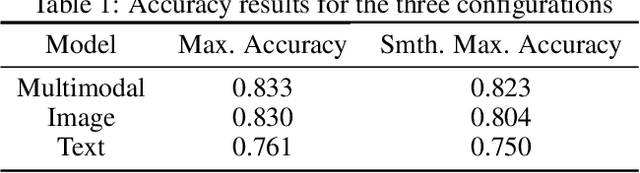
In this work, we propose an effective approach for training unique embedding representations by combining three simultaneous modalities: image and spoken and textual narratives. The proposed methodology departs from a baseline system that spawns a embedding space trained with only spoken narratives and image cues. Our experiments on the EPIC-Kitchen and Places Audio Caption datasets show that introducing the human-generated textual transcriptions of the spoken narratives helps to the training procedure yielding to get better embedding representations. The triad speech, image and words allows for a better estimate of the point embedding and show an improving of the performance within tasks like image and speech retrieval, even when text third modality, text, is not present in the task.
Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills
Feb 14, 2020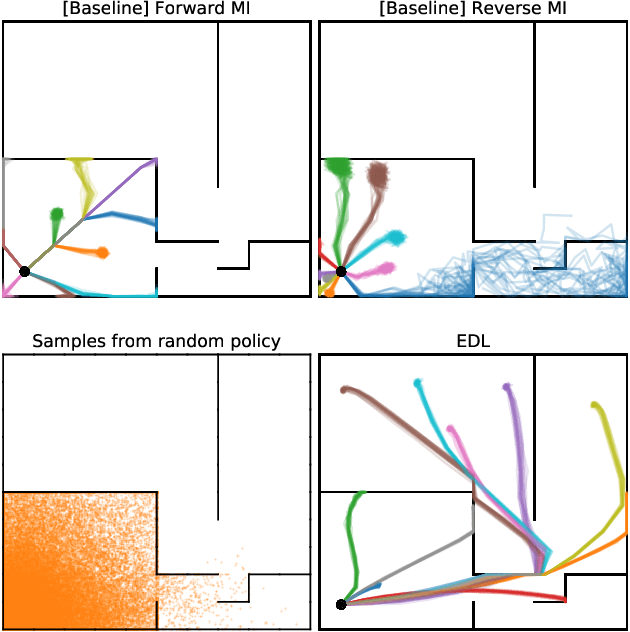



Acquiring abilities in the absence of a task-oriented reward function is at the frontier of reinforcement learning research. This problem has been studied through the lens of empowerment, which draws a connection between option discovery and information theory. Information-theoretic skill discovery methods have garnered much interest from the community, but little research has been conducted in understanding their limitations. Through theoretical analysis and empirical evidence, we show that existing algorithms suffer from a common limitation -- they discover options that provide a poor coverage of the state space. In light of this, we propose 'Explore, Discover and Learn' (EDL), an alternative approach to information-theoretic skill discovery. Crucially, EDL optimizes the same information-theoretic objective derived from the empowerment literature, but addresses the optimization problem using different machinery. We perform an extensive evaluation of skill discovery methods on controlled environments and show that EDL offers significant advantages, such as overcoming the coverage problem, reducing the dependence of learned skills on the initial state, and allowing the user to define a prior over which behaviors should be learned.
Recurrent Instance Segmentation using Sequences of Referring Expressions
Nov 05, 2019
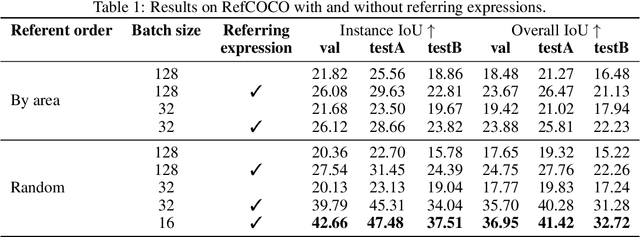
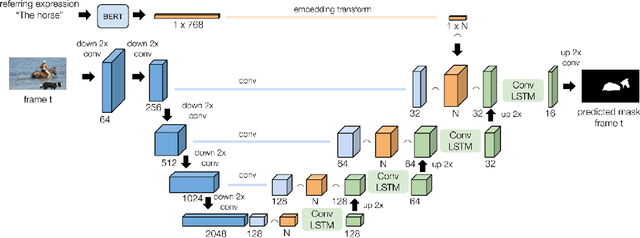

The goal of this work is to segment the objects in an image that are referred to by a sequence of linguistic descriptions (referring expressions). We propose a deep neural network with recurrent layers that output a sequence of binary masks, one for each referring expression provided by the user. The recurrent layers in the architecture allow the model to condition each predicted mask on the previous ones, from a spatial perspective within the same image. Our multimodal approach uses off-the-shelf architectures to encode both the image and the referring expressions. The visual branch provides a tensor of pixel embeddings that are concatenated with the phrase embeddings produced by a language encoder. Our experiments on the RefCOCO dataset for still images indicate how the proposed architecture successfully exploits the sequences of referring expressions to solve a pixel-wise task of instance segmentation.
Automatic Reminiscence Therapy for Dementia
Oct 25, 2019


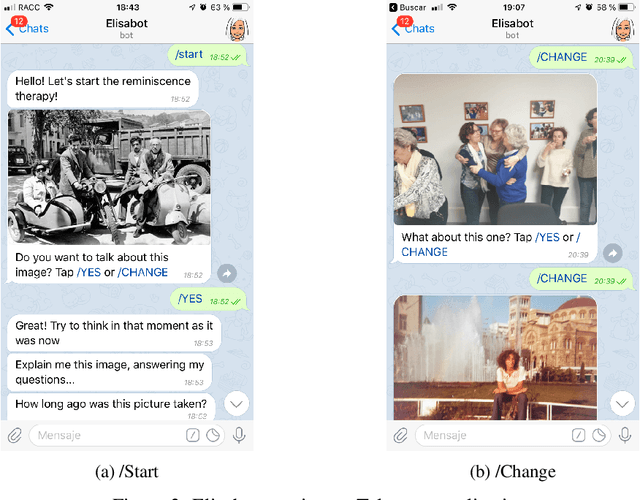
With people living longer than ever, the number of cases with dementia such as Alzheimer's disease increases steadily. It affects more than 46 million people worldwide, and it is estimated that in 2050 more than 100 million will be affected. While there are not effective treatments for these terminal diseases, therapies such as reminiscence, that stimulate memories from the past are recommended. Currently, reminiscence therapy takes place in care homes and is guided by a therapist or a carer. In this work, we present an AI-based solution to automatize the reminiscence therapy, which consists in a dialogue system that uses photos as input to generate questions. We run a usability case study with patients diagnosed of mild cognitive impairment that shows they found the system very entertaining and challenging. Overall, this paper presents how reminiscence therapy can be automatized by using machine learning, and deployed to smartphones and laptops, making the therapy more accessible to every person affected by dementia.
Hate Speech in Pixels: Detection of Offensive Memes towards Automatic Moderation
Oct 05, 2019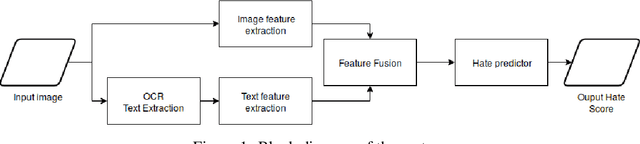

This work addresses the challenge of hate speech detection in Internet memes, and attempts using visual information to automatically detect hate speech, unlike any previous work of our knowledge. Memes are pixel-based multimedia documents that contain photos or illustrations together with phrases which, when combined, usually adopt a funny meaning. However, hate memes are also used to spread hate through social networks, so their automatic detection would help reduce their harmful societal impact. Our results indicate that the model can learn to detect some of the memes, but that the task is far from being solved with this simple architecture. While previous work focuses on linguistic hate speech, our experiments indicate how the visual modality can be much more informative for hate speech detection than the linguistic one in memes. In our experiments, we built a dataset of 5,020 memes to train and evaluate a multi-layer perceptron over the visual and language representations, whether independently or fused. The source code and mode and models are available https://github.com/imatge-upc/hate-speech-detection .
Simple vs complex temporal recurrences for video saliency prediction
Jul 16, 2019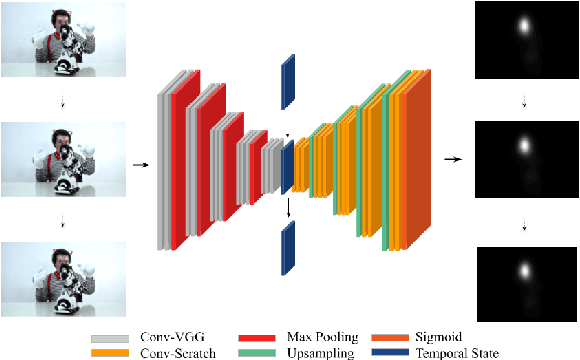
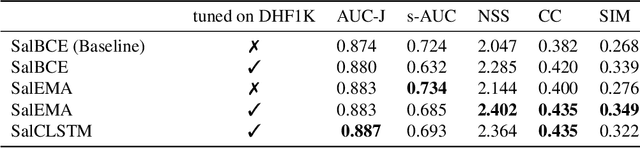
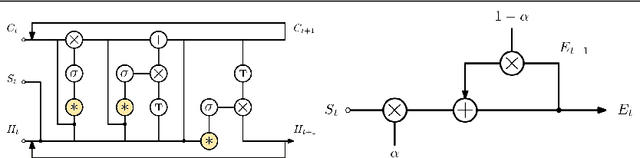
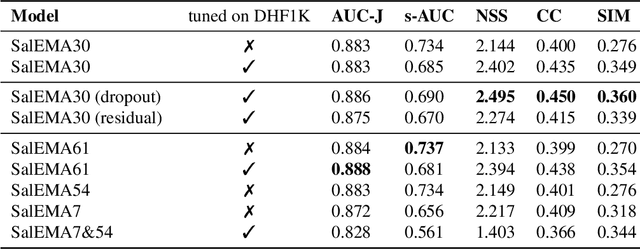
This paper investigates modifying an existing neural network architecture for static saliency prediction using two types of recurrences that integrate information from the temporal domain. The first modification is the addition of a ConvLSTM within the architecture, while the second is a conceptually simple exponential moving average of an internal convolutional state. We use weights pre-trained on the SALICON dataset and fine-tune our model on DHF1K. Our results show that both modifications achieve state-of-the-art results and produce similar saliency maps. Source code is available at https://git.io/fjPiB.
Budget-aware Semi-Supervised Semantic and Instance Segmentation
May 23, 2019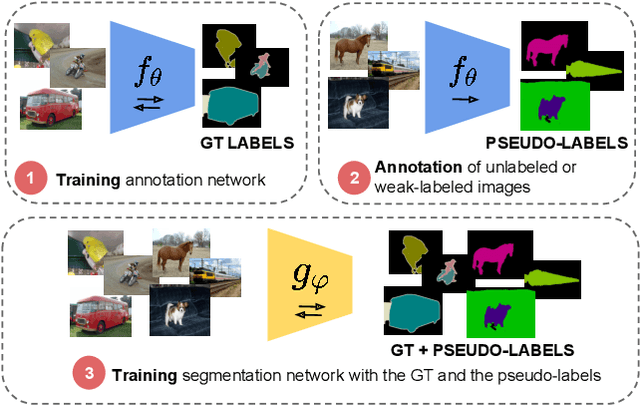


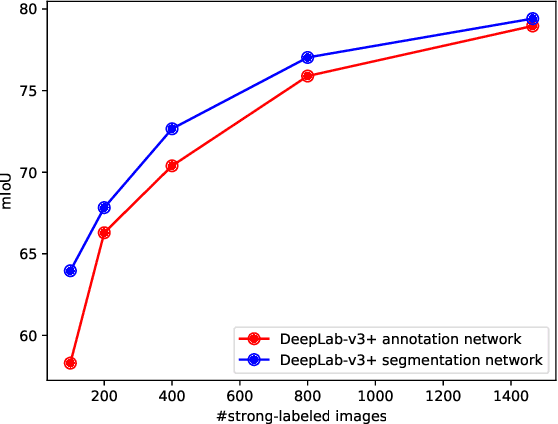
Methods that move towards less supervised scenarios are key for image segmentation, as dense labels demand significant human intervention. Generally, the annotation burden is mitigated by labeling datasets with weaker forms of supervision, e.g. image-level labels or bounding boxes. Another option are semi-supervised settings, that commonly leverage a few strong annotations and a huge number of unlabeled/weakly-labeled data. In this paper, we revisit semi-supervised segmentation schemes and narrow down significantly the annotation budget (in terms of total labeling time of the training set) compared to previous approaches. With a very simple pipeline, we demonstrate that at low annotation budgets, semi-supervised methods outperform by a wide margin weakly-supervised ones for both semantic and instance segmentation. Our approach also outperforms previous semi-supervised works at a much reduced labeling cost. We present results for the Pascal VOC benchmark and unify weakly and semi-supervised approaches by considering the total annotation budget, thus allowing a fairer comparison between methods.