 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymBa: Symbolic Backward Chaining for Multi-step Natural Language Reasoning
Feb 20, 2024Large Language Models (LLMs) have recently demonstrated remarkable reasoning ability as in Chain-of-thought prompting, but faithful multi-step reasoning remains a challenge. We specifically focus on backward chaining, where the query is recursively decomposed using logical rules until proven. To address the limitations of current backward chaining implementations, we propose SymBa (Symbolic Backward Chaining). In SymBa, the symbolic top-down solver controls the entire proof process and the LLM is called to generate a single reasoning step only when the solver encounters a dead end. By this novel solver-LLM integration, while being able to produce an interpretable, structured proof, SymBa achieves significant improvement in performance, proof faithfulness, and efficiency in diverse multi-step reasoning benchmarks (ProofWriter, Birds-Electricity, GSM8k, CLUTRR-TF, ECtHR Article 6) compared to backward chaining baselines.
NESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
Sep 08, 2023



The statistical analysis of large scale legal corpus can provide valuable legal insights. For such analysis one needs to (1) select a subset of the corpus using document retrieval tools, (2) structuralize text using information extraction (IE) systems, and (3) visualize the data for the statistical analysis. Each process demands either specialized tools or programming skills whereas no comprehensive unified "no-code" tools have been available. Especially for IE, if the target information is not predefined in the ontology of the IE system, one needs to build their own system. Here we provide NESTLE, a no code tool for large-scale statistical analysis of legal corpus. With NESTLE, users can search target documents, extract information, and visualize the structured data all via the chat interface with accompanying auxiliary GUI for the fine-level control. NESTLE consists of three main components: a search engine, an end-to-end IE system, and a Large Language Model (LLM) that glues the whole components together and provides the chat interface. Powered by LLM and the end-to-end IE system, NESTLE can extract any type of information that has not been predefined in the IE system opening up the possibility of unlimited customizable statistical analysis of the corpus without writing a single line of code. The use of the custom end-to-end IE system also enables faster and low-cost IE on large scale corpus. We validate our system on 15 Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE. The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable performance by training the internal IE module with 4 human-labeled, and 192 LLM-labeled examples. The detailed analysis provides the insight on the trade-off between accuracy, time, and cost in building such system.
Data-efficient End-to-end Information Extraction for Statistical Legal Analysis
Nov 03, 2022



Legal practitioners often face a vast amount of documents. Lawyers, for instance, search for appropriate precedents favorable to their clients, while the number of legal precedents is ever-growing. Although legal search engines can assist finding individual target documents and narrowing down the number of candidates, retrieved information is often presented as unstructured text and users have to examine each document thoroughly which could lead to information overloading. This also makes their statistical analysis challenging. Here, we present an end-to-end information extraction (IE) system for legal documents. By formulating IE as a generation task, our system can be easily applied to various tasks without domain-specific engineering effort. The experimental results of four IE tasks on Korean precedents shows that our IE system can achieve competent scores (-2.3 on average) compared to the rule-based baseline with as few as 50 training examples per task and higher score (+5.4 on average) with 200 examples. Finally, our statistical analysis on two case categories--drunk driving and fraud--with 35k precedents reveals the resulting structured information from our IE system faithfully reflects the macroscopic features of Korean legal system.
A Multi-Task Benchmark for Korean Legal Language Understanding and Judgement Prediction
Jun 10, 2022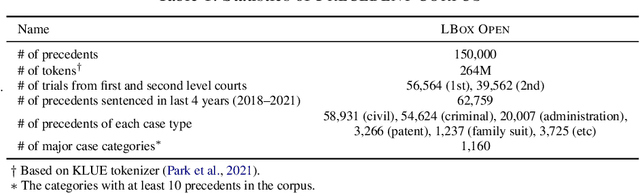
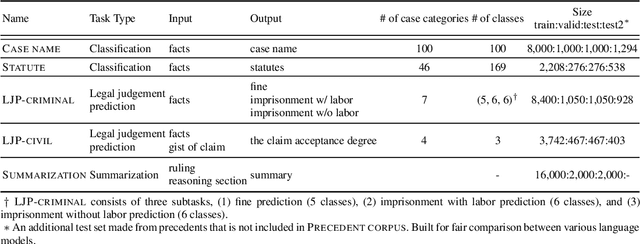
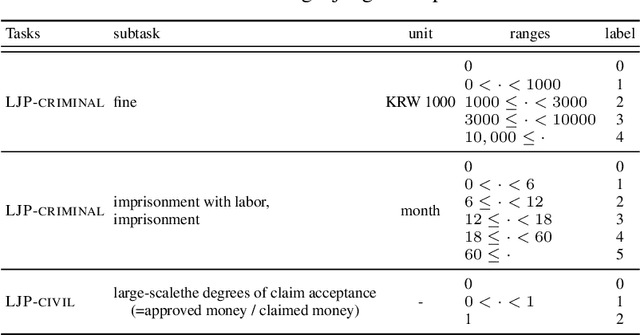
The recent advances of deep learning have dramatically changed how machine learning, especially in the domain of natural language processing, can be applied to legal domain. However, this shift to the data-driven approaches calls for larger and more diverse datasets, which are nevertheless still small in number, especially in non-English languages. Here we present the first large-scale benchmark of Korean legal AI datasets, LBox Open, that consists of one legal corpus, two classification tasks, two legal judgement prediction (LJP) tasks, and one summarization task. The legal corpus consists of 150k Korean precedents (264M tokens), of which 63k are sentenced in last 4 years and 96k are from the first and the second level courts in which factual issues are reviewed. The two classification tasks are case names (10k) and statutes (3k) prediction from the factual description of individual cases. The LJP tasks consist of (1) 11k criminal examples where the model is asked to predict fine amount, imprisonment with labor, and imprisonment without labor ranges for the given facts, and (2) 5k civil examples where the inputs are facts and claim for relief and outputs are the degrees of claim acceptance. The summarization task consists of the Supreme Court precedents and the corresponding summaries. We also release LCube, the first Korean legal language model trained on the legal corpus from this study. Given the uniqueness of the Law of South Korea and the diversity of the legal tasks covered in this work, we believe that LBox Open contributes to the multilinguality of global legal research. LBox Open and LCube will be publicly available.
Semi-Structured Query Grounding for Document-Oriented Databases with Deep Retrieval and Its Application to Receipt and POI Matching
Feb 23, 2022
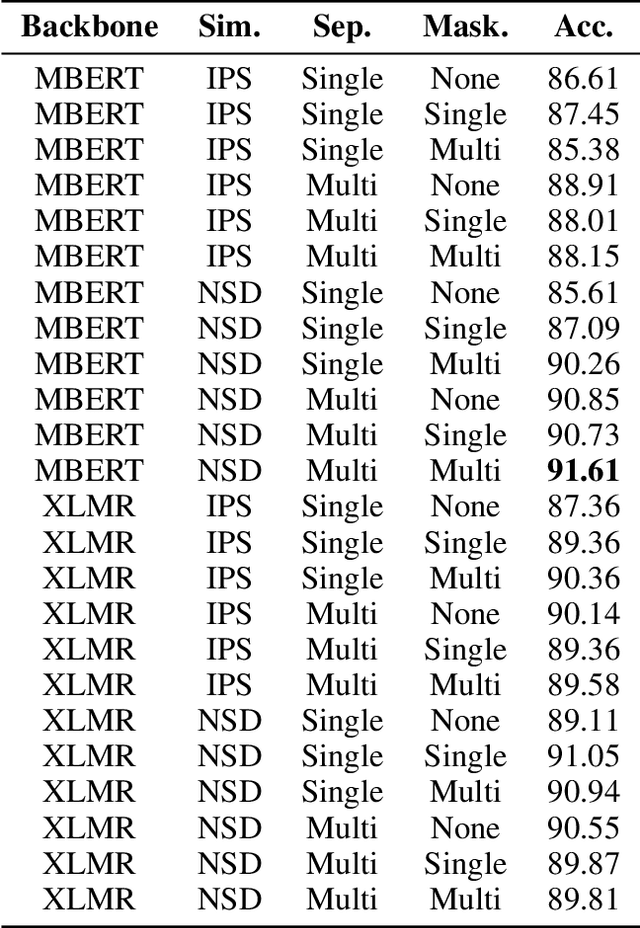

Semi-structured query systems for document-oriented databases have many real applications. One particular application that we are interested in is matching each financial receipt image with its corresponding place of interest (POI, e.g., restaurant) in the nationwide database. The problem is especially challenging in the real production environment where many similar or incomplete entries exist in the database and queries are noisy (e.g., errors in optical character recognition). In this work, we aim to address practical challenges when using embedding-based retrieval for the query grounding problem in semi-structured data. Leveraging recent advancements in deep language encoding for retrieval, we conduct extensive experiments to find the most effective combination of modules for the embedding and retrieval of both query and database entries without any manually engineered component. The proposed model significantly outperforms the conventional manual pattern-based model while requiring much less development and maintenance cost. We also discuss some core observations in our experiments, which could be helpful for practitioners working on a similar problem in other domains.
Donut: Document Understanding Transformer without OCR
Nov 30, 2021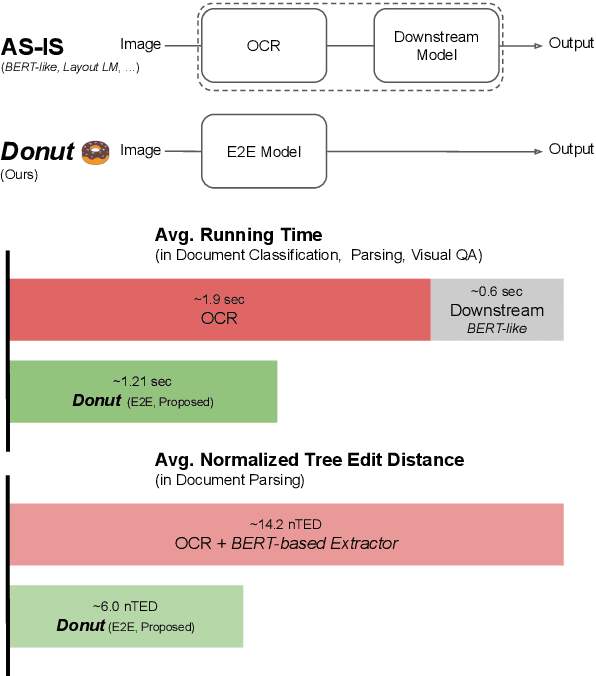
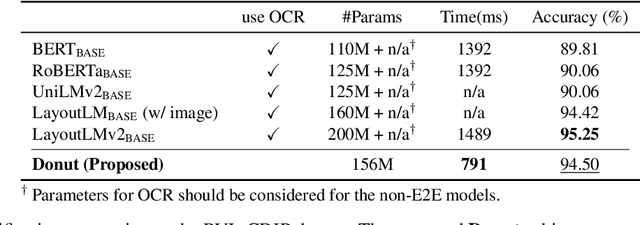
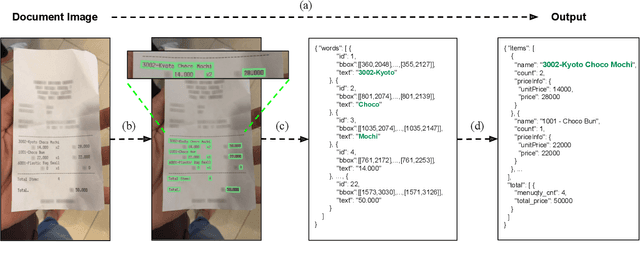

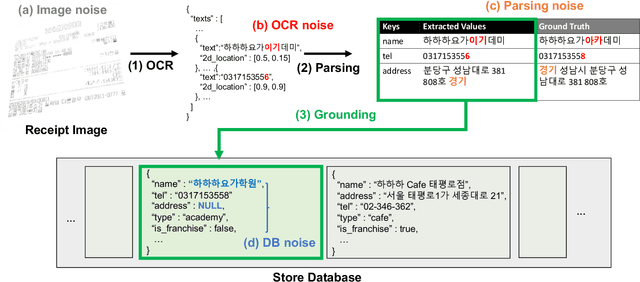
Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
Sep 10, 2021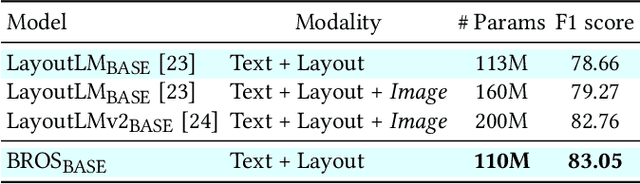
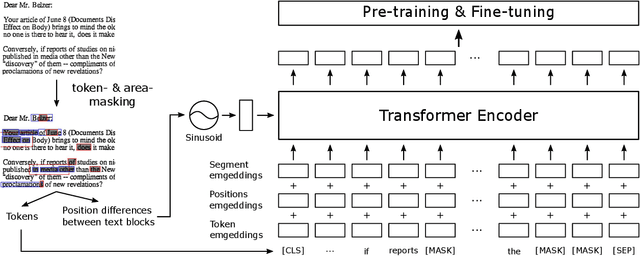

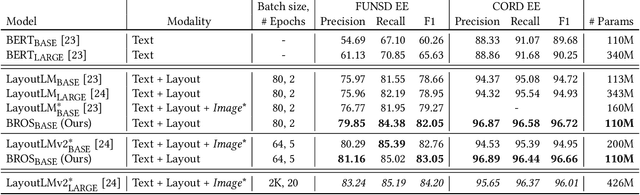
Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-training language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks--(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples--and demonstrates the superiority of BROS over previous methods. Our code will be open to the public.
Cost-effective End-to-end Information Extraction for Semi-structured Document Images
Apr 16, 2021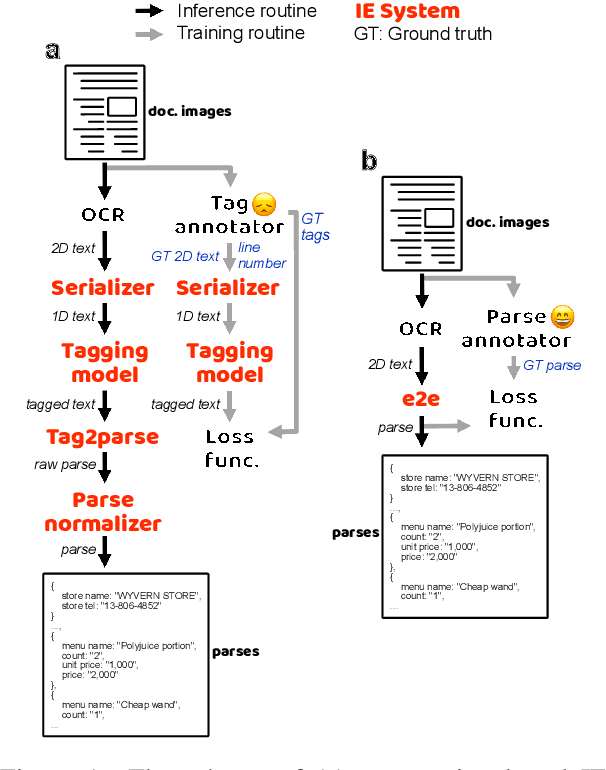

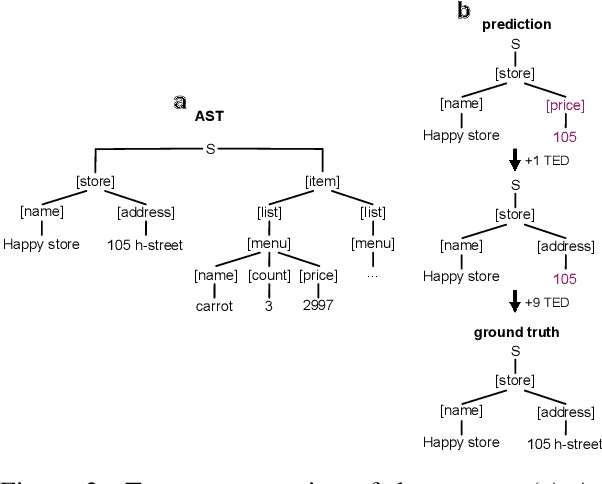

A real-world information extraction (IE) system for semi-structured document images often involves a long pipeline of multiple modules, whose complexity dramatically increases its development and maintenance cost. One can instead consider an end-to-end model that directly maps the input to the target output and simplify the entire process. However, such generation approach is known to lead to unstable performance if not designed carefully. Here we present our recent effort on transitioning from our existing pipeline-based IE system to an end-to-end system focusing on practical challenges that are associated with replacing and deploying the system in real, large-scale production. By carefully formulating document IE as a sequence generation task, we show that a single end-to-end IE system can be built and still achieve competent performance.
Tractable loss function and color image generation of multinary restricted Boltzmann machine
Nov 27, 2020
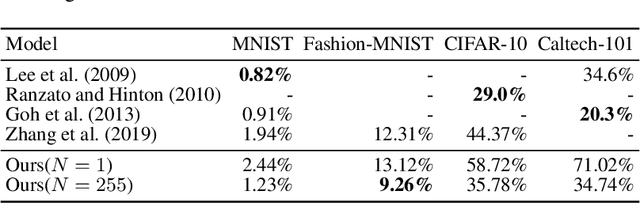

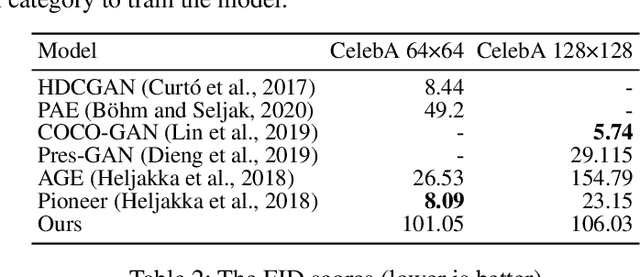
The restricted Boltzmann machine (RBM) is a representative generative model based on the concept of statistical mechanics. In spite of the strong merit of interpretability, unavailability of backpropagation makes it less competitive than other generative models. Here we derive differentiable loss functions for both binary and multinary RBMs. Then we demonstrate their learnability and performance by generating colored face images.
Syntactic Question Abstraction and Retrieval for Data-Scarce Semantic Parsing
May 01, 2020

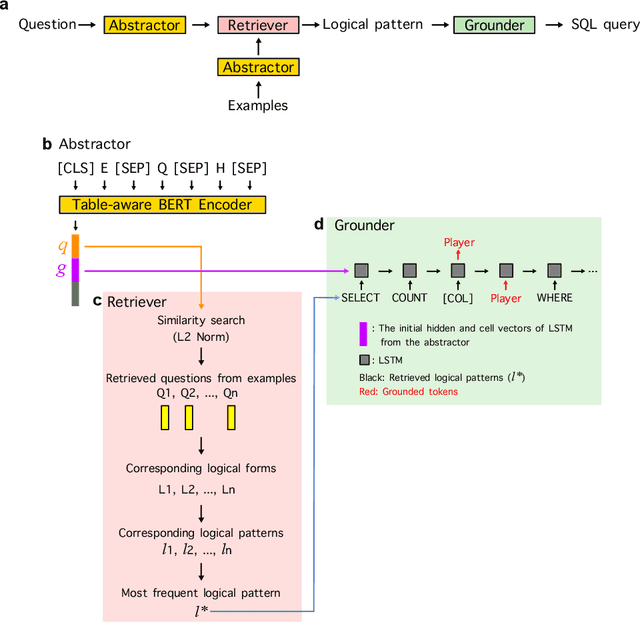

Deep learning approaches to semantic parsing require a large amount of labeled data, but annotating complex logical forms is costly. Here, we propose Syntactic Question Abstraction and Retrieval (SQAR), a method to build a neural semantic parser that translates a natural language (NL) query to a SQL logical form (LF) with less than 1,000 annotated examples. SQAR first retrieves a logical pattern from the train data by computing the similarity between NL queries and then grounds a lexical information on the retrieved pattern in order to generate the final LF. We validate SQAR by training models using various small subsets of WikiSQL train data achieving up to 4.9% higher LF accuracy compared to the previous state-of-the-art models on WikiSQL test set. We also show that by using query-similarity to retrieve logical pattern, SQAR can leverage a paraphrasing dataset achieving up to 5.9% higher LF accuracy compared to the case where SQAR is trained by using only WikiSQL data. In contrast to a simple pattern classification approach, SQAR can generate unseen logical patterns upon the addition of new examples without re-training the model. We also discuss an ideal way to create cost efficient and robust train datasets when the data distribution can be approximated under a data-hungry setting.