 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sound Source Localization with Joint Slot Attention on Image and Audio
Apr 21, 2025



Sound source localization (SSL) is the task of locating the source of sound within an image. Due to the lack of localization labels, the de facto standard in SSL has been to represent an image and audio as a single embedding vector each, and use them to learn SSL via contrastive learning. To this end, previous work samples one of local image features as the image embedding and aggregates all local audio features to obtain the audio embedding, which is far from optimal due to the presence of noise and background irrelevant to the actual target in the input. We present a novel SSL method that addresses this chronic issue by joint slot attention on image and audio. To be specific, two slots competitively attend image and audio features to decompose them into target and off-target representations, and only target representations of image and audio are used for contrastive learning. Also, we introduce cross-modal attention matching to further align local features of image and audio. Our method achieved the best in almost all settings on three public benchmarks for SSL, and substantially outperformed all the prior work in cross-modal retrieval.
Gradient Scaling on Deep Spiking Neural Networks with Spike-Dependent Local Information
Aug 01, 2023



Deep spiking neural networks (SNNs) are promising neural networks for their model capacity from deep neural network architecture and energy efficiency from SNNs' operations. To train deep SNNs, recently, spatio-temporal backpropagation (STBP) with surrogate gradient was proposed. Although deep SNNs have been successfully trained with STBP, they cannot fully utilize spike information. In this work, we proposed gradient scaling with local spike information, which is the relation between pre- and post-synaptic spikes. Considering the causality between spikes, we could enhance the training performance of deep SNNs. According to our experiments, we could achieve higher accuracy with lower spikes by adopting the gradient scaling on image classification tasks, such as CIFAR10 and CIFAR100.
Markov chain Hebbian learning algorithm with ternary synaptic units
Nov 23, 2017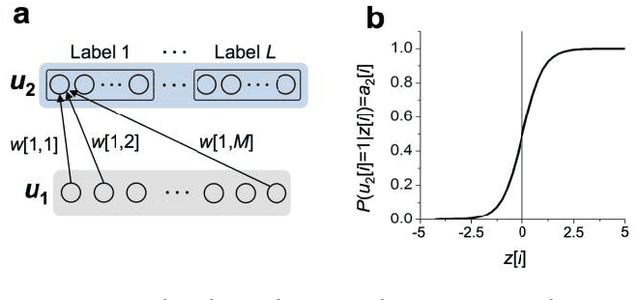

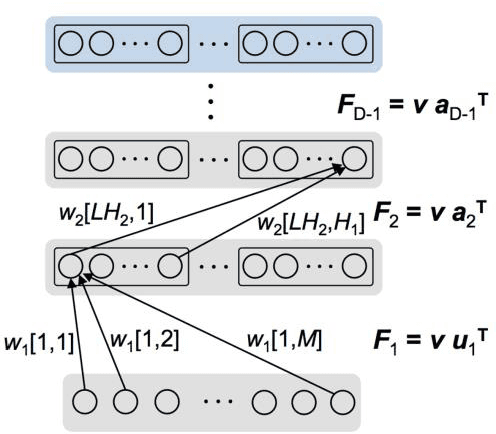
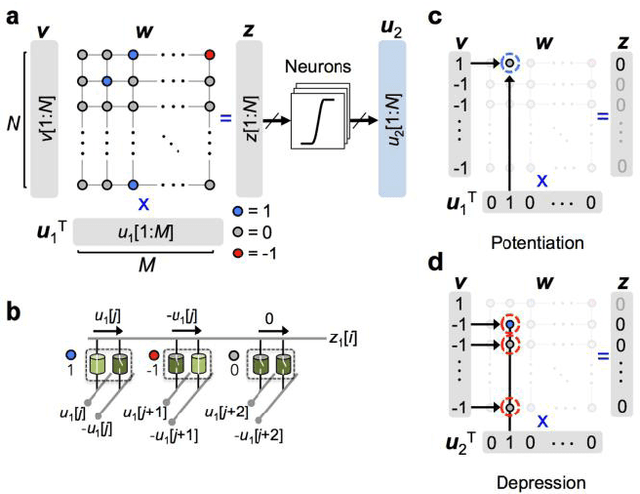
In spite of remarkable progress in machine learning techniques, the state-of-the-art machine learning algorithms often keep machines from real-time learning (online learning) due in part to computational complexity in parameter optimization. As an alternative, a learning algorithm to train a memory in real time is proposed, which is named as the Markov chain Hebbian learning algorithm. The algorithm pursues efficient memory use during training in that (i) the weight matrix has ternary elements (-1, 0, 1) and (ii) each update follows a Markov chain--the upcoming update does not need past weight memory. The algorithm was verified by two proof-of-concept tasks (handwritten digit recognition and multiplication table memorization) in which numbers were taken as symbols. Particularly, the latter bases multiplication arithmetic on memory, which may be analogous to humans' mental arithmetic. The memory-based multiplication arithmetic feasibly offers the basis of factorization, supporting novel insight into the arithmetic.