 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReset-Free Guided Policy Search: Efficient Deep Reinforcement Learning with Stochastic Initial States
Oct 06, 2016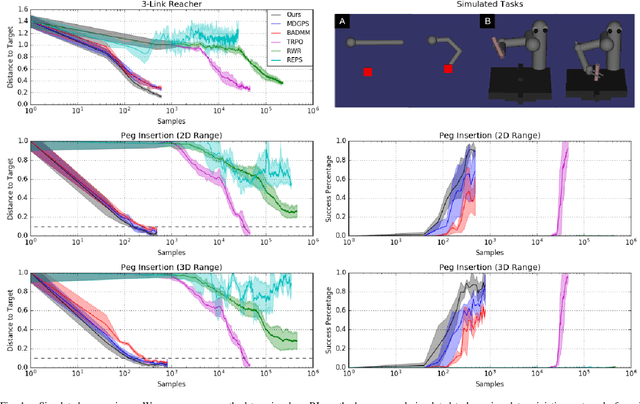
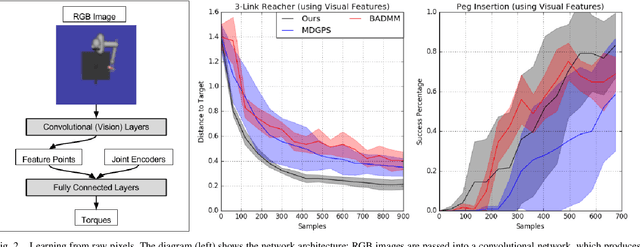

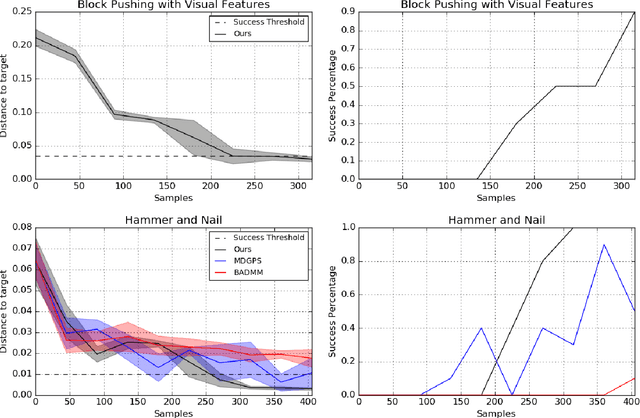
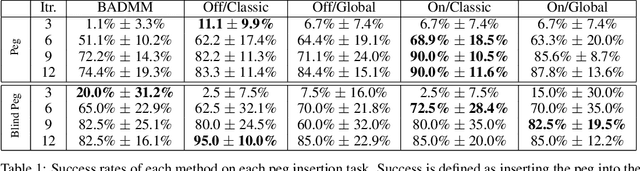
Autonomous learning of robotic skills can allow general-purpose robots to learn wide behavioral repertoires without requiring extensive manual engineering. However, robotic skill learning methods typically make one of several trade-offs to enable practical real-world learning, such as requiring manually designed policy or value function representations, initialization from human-provided demonstrations, instrumentation of the training environment, or extremely long training times. In this paper, we propose a new reinforcement learning algorithm for learning manipulation skills that can train general-purpose neural network policies with minimal human engineering, while still allowing for fast, efficient learning in stochastic environments. Our approach builds on the guided policy search (GPS) algorithm, which transforms the reinforcement learning problem into supervised learning from a computational teacher (without human demonstrations). In contrast to prior GPS methods, which require a consistent set of initial states to which the system must be reset after each episode, our approach can handle randomized initial states, allowing it to be used in environments where deterministic resets are impossible. We compare our method to existing policy search techniques in simulation, showing that it can train high-dimensional neural network policies with the same sample efficiency as prior GPS methods, and present real-world results on a PR2 robotic manipulator.
Guided Policy Search as Approximate Mirror Descent
Jul 15, 2016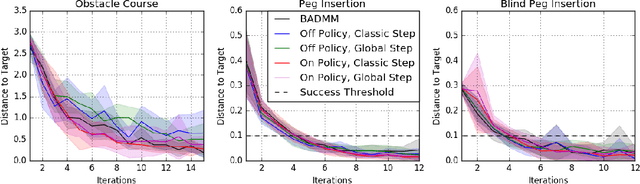
Guided policy search algorithms can be used to optimize complex nonlinear policies, such as deep neural networks, without directly computing policy gradients in the high-dimensional parameter space. Instead, these methods use supervised learning to train the policy to mimic a "teacher" algorithm, such as a trajectory optimizer or a trajectory-centric reinforcement learning method. Guided policy search methods provide asymptotic local convergence guarantees by construction, but it is not clear how much the policy improves within a small, finite number of iterations. We show that guided policy search algorithms can be interpreted as an approximate variant of mirror descent, where the projection onto the constraint manifold is not exact. We derive a new guided policy search algorithm that is simpler and provides appealing improvement and convergence guarantees in simplified convex and linear settings, and show that in the more general nonlinear setting, the error in the projection step can be bounded. We provide empirical results on several simulated robotic navigation and manipulation tasks that show that our method is stable and achieves similar or better performance when compared to prior guided policy search methods, with a simpler formulation and fewer hyperparameters.