 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdeNet: Deep learning architecture that identifies damaged electrical insulators in power lines
Mar 02, 2021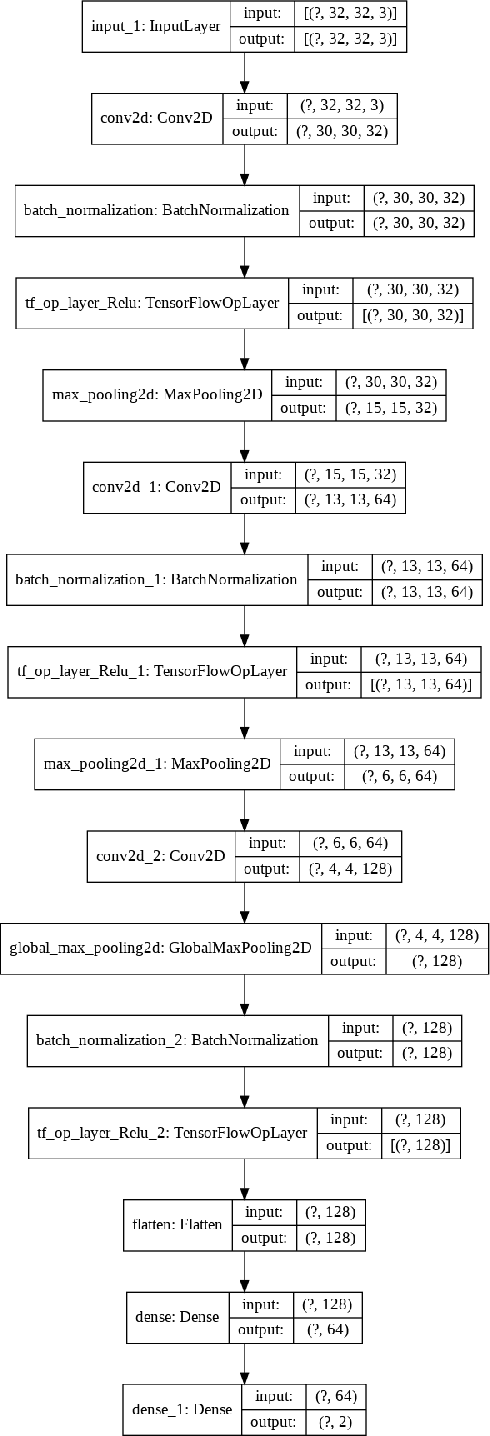



Ceramic insulators are important to electronic systems, designed and installed to protect humans from the danger of high voltage electric current. However, insulators are not immortal, and natural deterioration can gradually damage them. Therefore, the condition of insulators must be continually monitored, which is normally done using UAVs. UAVs collect many images of insulators, and these images are then analyzed to identify those that are damaged. Here we describe AdeNet as a deep neural network designed to identify damaged insulators, and test multiple approaches to automatic analysis of the condition of insulators. Several deep neural networks were tested, as were shallow learning methods. The best results (88.8\%) were achieved using AdeNet without transfer learning. AdeNet also reduced the false negative rate to $\sim$7\%. While the method cannot fully replace human inspection, its high throughput can reduce the amount of labor required to monitor lines for damaged insulators and provide early warning to replace damaged insulators.
Segmentation of Breast Microcalcifications: A Multi-Scale Approach
Feb 01, 2021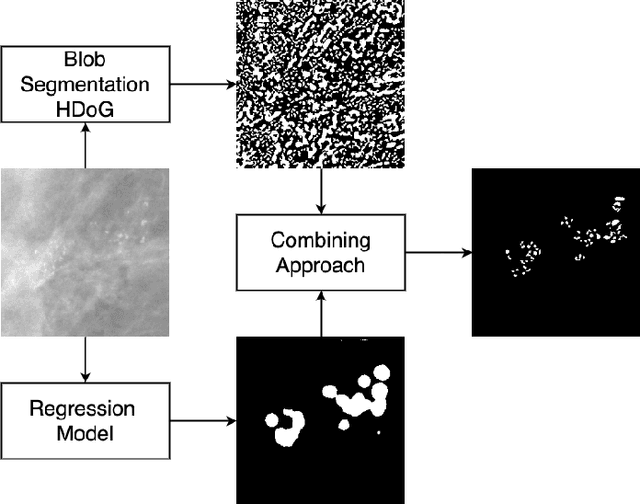


Accurate characterization of microcalcifications (MCs) in 2D full-field digital screening mammography is a necessary step towards reducing diagnostic uncertainty associated with the callback of women with suspicious MCs. Quantitative analysis of MCs has the potential to better identify MCs that have a higher likelihood of corresponding to invasive cancer. However, automated identification and segmentation of MCs remains a challenging task with high false positive rates. We present Hessian Difference of Gaussians Regression (HDoGReg), a two stage multi-scale approach to MC segmentation. Candidate high optical density objects are first delineated using blob detection and Hessian analysis. A regression convolutional network, trained to output a function with higher response near MCs, chooses the objects which constitute actual MCs. The method is trained and validated on 435 mammograms from two separate datasets. HDoGReg achieved a mean intersection over the union of 0.670$\pm$0.121 per image, intersection over the union per MC object of 0.607$\pm$0.250 and true positive rate of 0.744 at 0.4 false positive detections per $cm^2$. The results of HDoGReg perform better when compared to state-of-the-art MC segmentation and detection methods.
Feature Selection for Learning to Predict Outcomes of Compute Cluster Jobs with Application to Decision Support
Dec 14, 2020

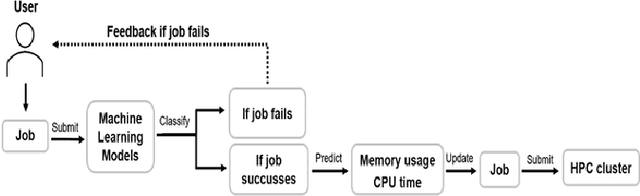
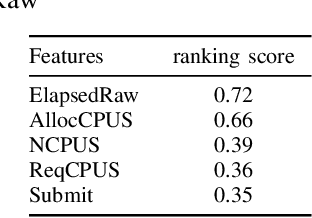
We present a machine learning framework and a new test bed for data mining from the Slurm Workload Manager for high-performance computing (HPC) clusters. The focus was to find a method for selecting features to support decisions: helping users decide whether to resubmit failed jobs with boosted CPU and memory allocations or migrate them to a computing cloud. This task was cast as both supervised classification and regression learning, specifically, sequential problem solving suitable for reinforcement learning. Selecting relevant features can improve training accuracy, reduce training time, and produce a more comprehensible model, with an intelligent system that can explain predictions and inferences. We present a supervised learning model trained on a Simple Linux Utility for Resource Management (Slurm) data set of HPC jobs using three different techniques for selecting features: linear regression, lasso, and ridge regression. Our data set represented both HPC jobs that failed and those that succeeded, so our model was reliable, less likely to overfit, and generalizable. Our model achieved an R^2 of 95\% with 99\% accuracy. We identified five predictors for both CPU and memory properties.
Shape-aware Generative Adversarial Networks for Attribute Transfer
Oct 11, 2020
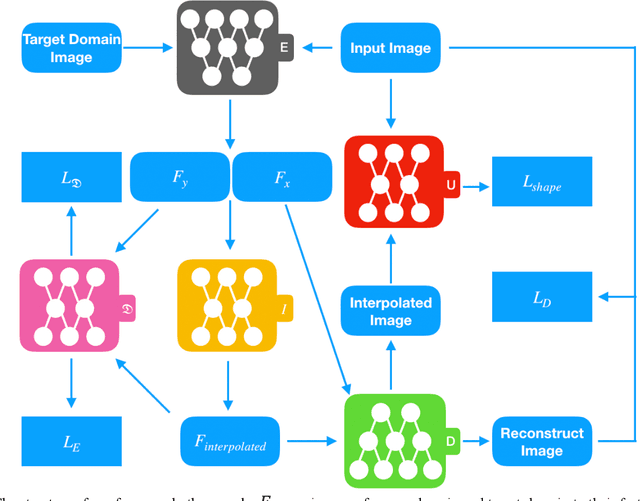
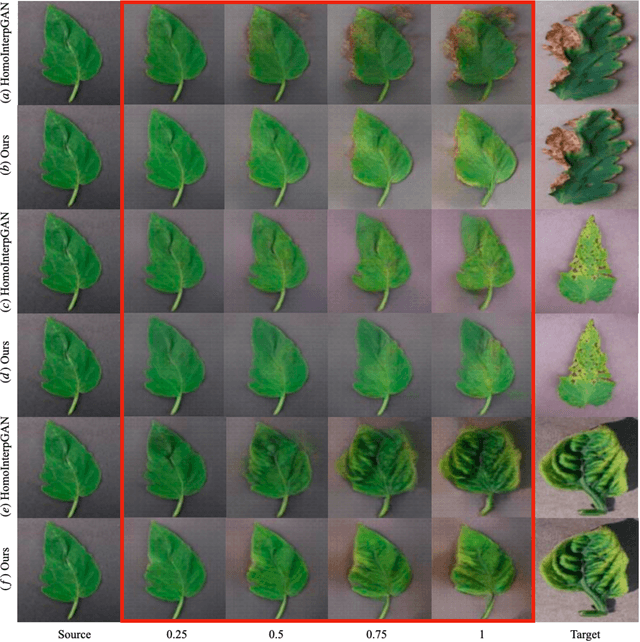

Generative adversarial networks (GANs) have been successfully applied to transfer visual attributes in many domains, including that of human face images. This success is partly attributable to the facts that human faces have similar shapes and the positions of eyes, noses, and mouths are fixed among different people. Attribute transfer is more challenging when the source and target domain share different shapes. In this paper, we introduce a shape-aware GAN model that is able to preserve shape when transferring attributes, and propose its application to some real-world domains. Compared to other state-of-art GANs-based image-to-image translation models, the model we propose is able to generate more visually appealing results while maintaining the quality of results from transfer learning.
Using a Generative Adversarial Network for CT Normalization and its Impact on Radiomic Features
Jan 22, 2020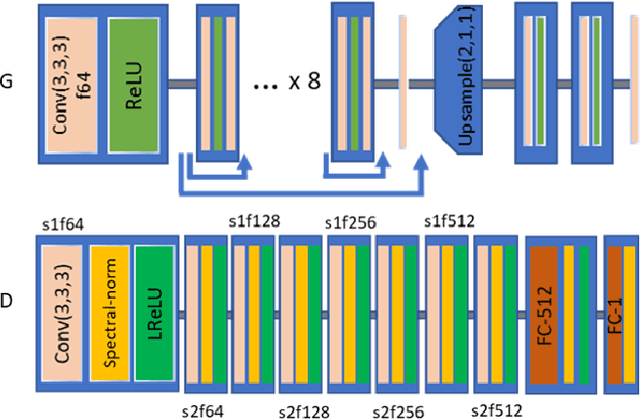
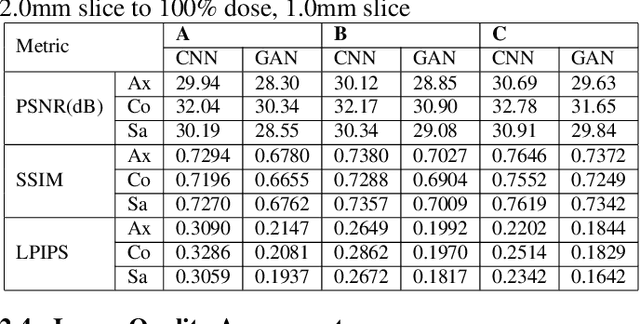
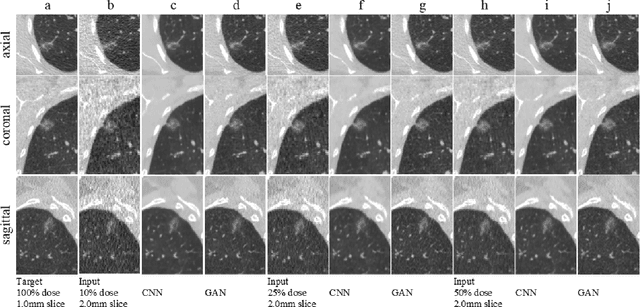
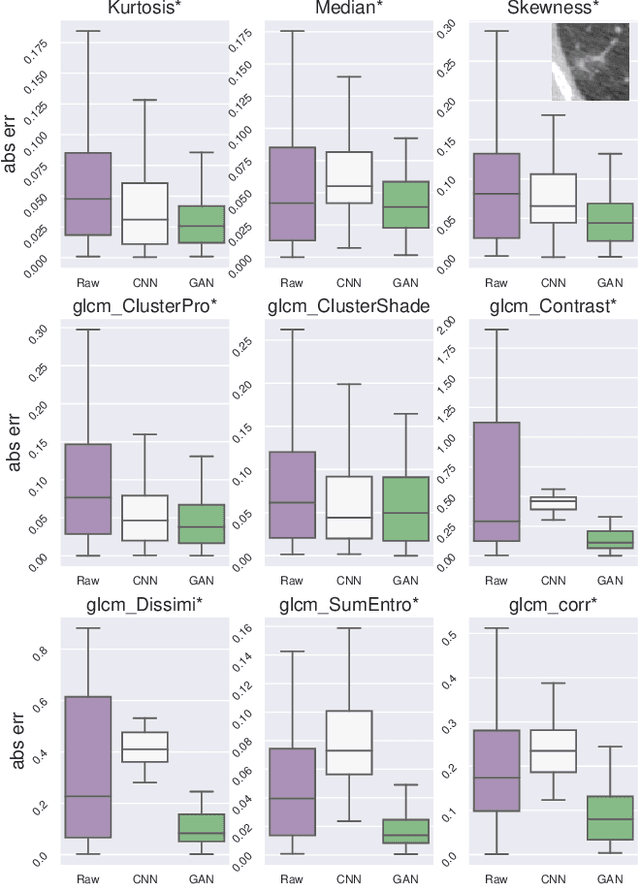
Computer-Aided-Diagnosis (CADx) systems assist radiologists with identifying and classifying potentially malignant pulmonary nodules on chest CT scans using morphology and texture-based (radiomic) features. However, radiomic features are sensitive to differences in acquisitions due to variations in dose levels and slice thickness. This study investigates the feasibility of generating a normalized scan from heterogeneous CT scans as input. We obtained projection data from 40 low-dose chest CT scans, simulating acquisitions at 10%, 25% and 50% dose and reconstructing the scans at 1.0mm and 2.0mm slice thickness. A 3D generative adversarial network (GAN) was used to simultaneously normalize reduced dose, thick slice (2.0mm) images to normal dose (100%), thinner slice (1.0mm) images. We evaluated the normalized image quality using peak signal-to-noise ratio (PSNR), structural similarity index (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS). Our GAN improved perceptual similarity by 35%, compared to a baseline CNN method. Our analysis also shows that the GAN-based approach led to a significantly smaller error (p-value < 0.05) in nine studied radiomic features. These results indicated that GANs could be used to normalize heterogeneous CT images and reduce the variability in radiomic feature values.
Sequential Triggers for Watermarking of Deep Reinforcement Learning Policies
Jun 03, 2019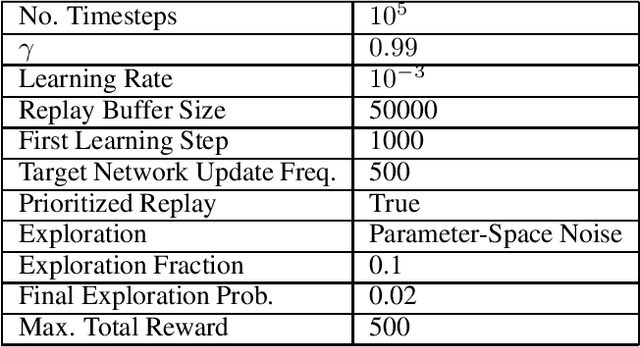
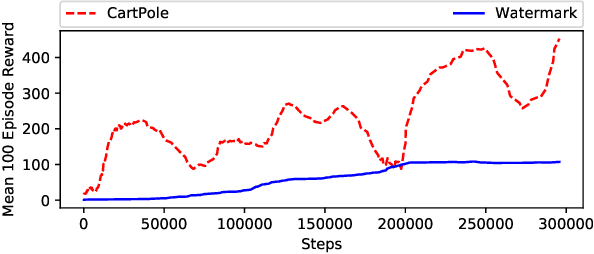
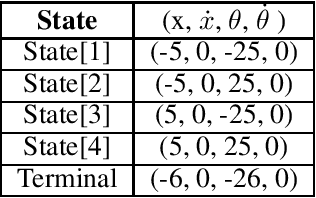
This paper proposes a novel scheme for the watermarking of Deep Reinforcement Learning (DRL) policies. This scheme provides a mechanism for the integration of a unique identifier within the policy in the form of its response to a designated sequence of state transitions, while incurring minimal impact on the nominal performance of the policy. The applications of this watermarking scheme include detection of unauthorized replications of proprietary policies, as well as enabling the graceful interruption or termination of DRL activities by authorized entities. We demonstrate the feasibility of our proposal via experimental evaluation of watermarking a DQN policy trained in the Cartpole environment.
Adversarial Exploitation of Policy Imitation
Jun 03, 2019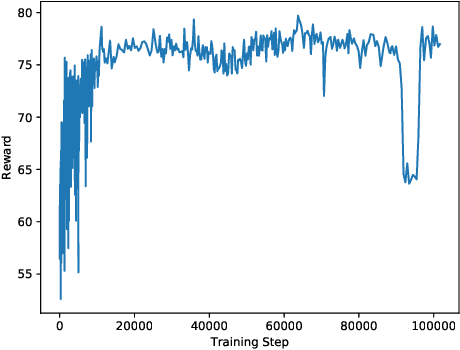

This paper investigates a class of attacks targeting the confidentiality aspect of security in Deep Reinforcement Learning (DRL) policies. Recent research have established the vulnerability of supervised machine learning models (e.g., classifiers) to model extraction attacks. Such attacks leverage the loosely-restricted ability of the attacker to iteratively query the model for labels, thereby allowing for the forging of a labeled dataset which can be used to train a replica of the original model. In this work, we demonstrate the feasibility of exploiting imitation learning techniques in launching model extraction attacks on DRL agents. Furthermore, we develop proof-of-concept attacks that leverage such techniques for black-box attacks against the integrity of DRL policies. We also present a discussion on potential solution concepts for mitigation techniques.
Analysis and Improvement of Adversarial Training in DQN Agents With Adversarially-Guided Exploration (AGE)
Jun 03, 2019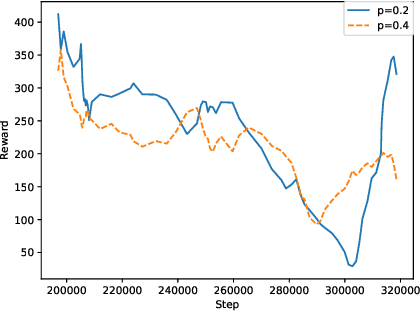
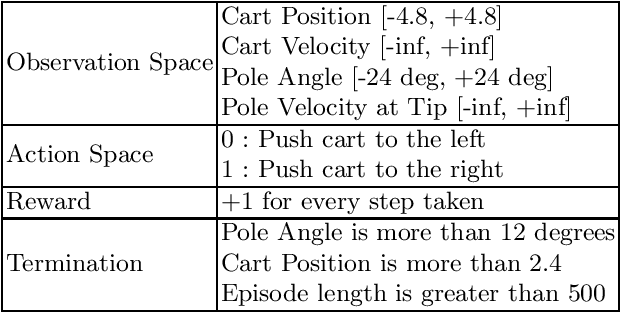
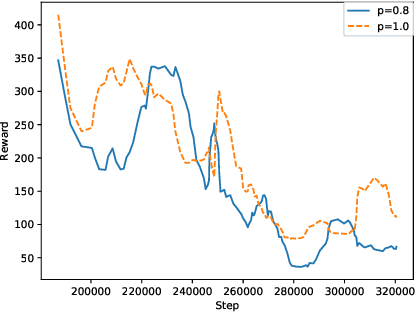
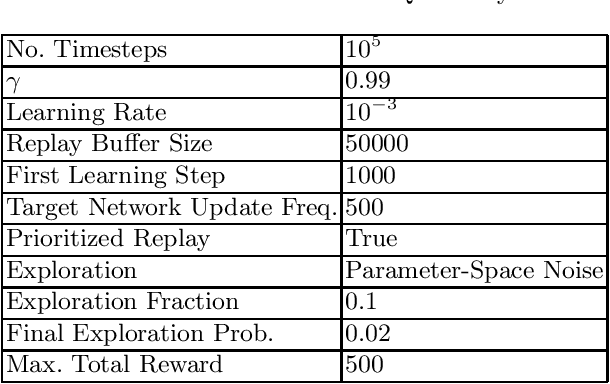
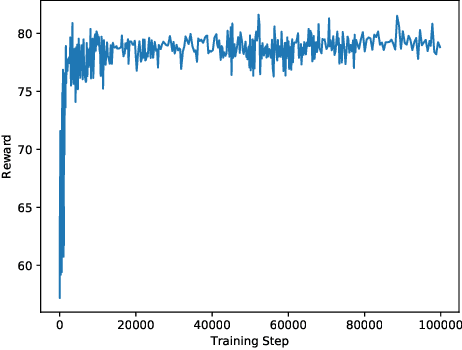
This paper investigates the effectiveness of adversarial training in enhancing the robustness of Deep Q-Network (DQN) policies to state-space perturbations. We first present a formal analysis of adversarial training in DQN agents and its performance with respect to the proportion of adversarial perturbations to nominal observations used for training. Next, we consider the sample-inefficiency of current adversarial training techniques, and propose a novel Adversarially-Guided Exploration (AGE) mechanism based on a modified hybrid of the $\epsilon$-greedy algorithm and Boltzmann exploration. We verify the feasibility of this exploration mechanism through experimental evaluation of its performance in comparison with the traditional decaying $\epsilon$-greedy and parameter-space noise exploration algorithms.
RL-Based Method for Benchmarking the Adversarial Resilience and Robustness of Deep Reinforcement Learning Policies
Jun 03, 2019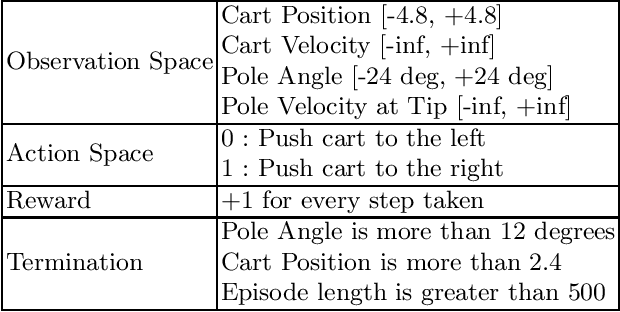
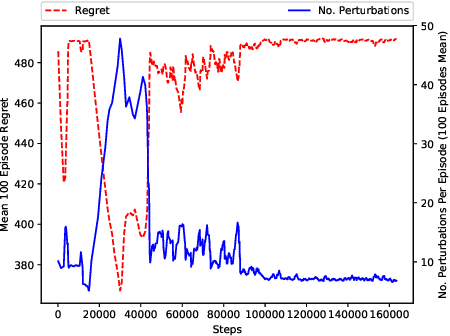
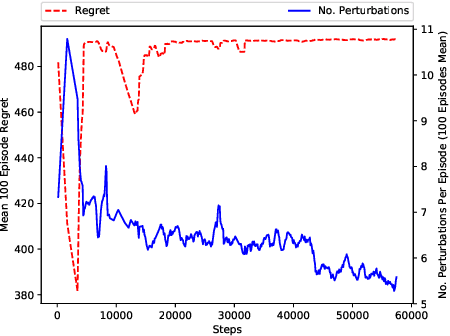
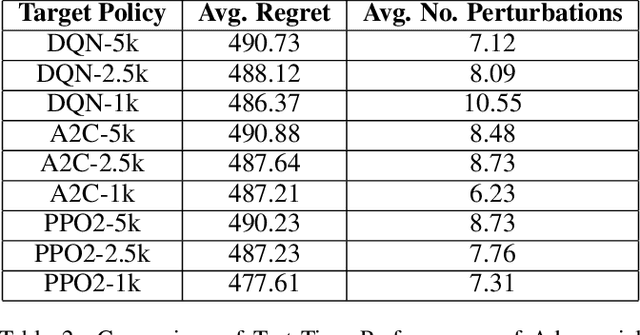
This paper investigates the resilience and robustness of Deep Reinforcement Learning (DRL) policies to adversarial perturbations in the state space. We first present an approach for the disentanglement of vulnerabilities caused by representation learning of DRL agents from those that stem from the sensitivity of the DRL policies to distributional shifts in state transitions. Building on this approach, we propose two RL-based techniques for quantitative benchmarking of adversarial resilience and robustness in DRL policies against perturbations of state transitions. We demonstrate the feasibility of our proposals through experimental evaluation of resilience and robustness in DQN, A2C, and PPO2 policies trained in the Cartpole environment.
OpBerg: Discovering causal sentences using optimal alignments
Apr 03, 2019The biological literature is rich with sentences that describe causal relations. Methods that automatically extract such sentences can help biologists to synthesize the literature and even discover latent relations that had not been articulated explicitly. Current methods for extracting causal sentences are based on either machine learning or a predefined database of causal terms. Machine learning approaches require a large set of labeled training data and can be susceptible to noise. Methods based on predefined databases are limited by the quality of their curation and are unable to capture new concepts or mistakes in the input. We address these challenges by adapting and improving a method designed for a seemingly unrelated problem: finding alignments between genomic sequences. This paper presents a novel and outperforming method for extracting causal relations from text by aligning the part-of-speech representations of an input set with that of known causal sentences. Our experiments show that when applied to the task of finding causal sentences in biological literature, our method improves on the accuracy of other methods in a computationally efficient manner.