 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Two-stage Learning with Sign-based Voting
Dec 10, 2021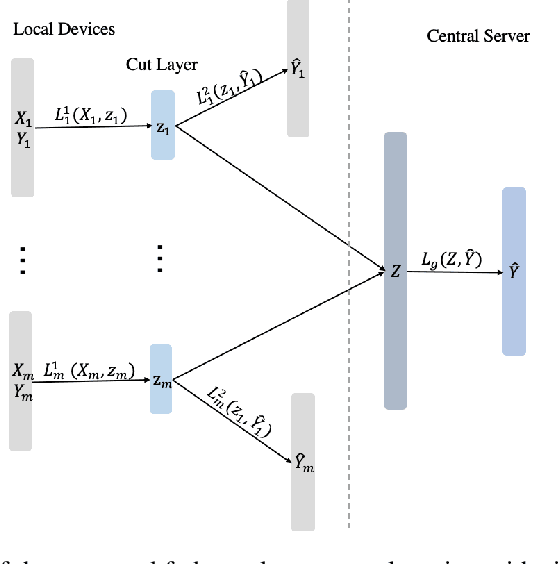
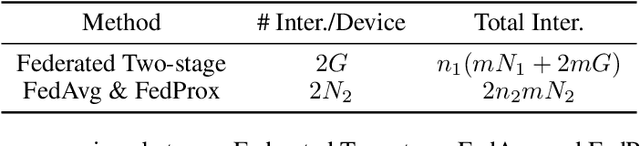
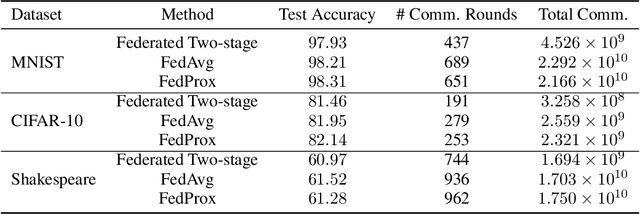
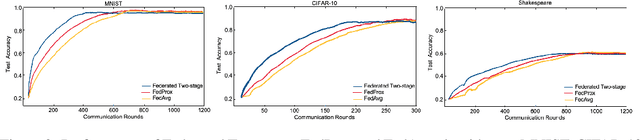
Federated learning is a distributed machine learning mechanism where local devices collaboratively train a shared global model under the orchestration of a central server, while keeping all private data decentralized. In the system, model parameters and its updates are transmitted instead of raw data, and thus the communication bottleneck has become a key challenge. Besides, recent larger and deeper machine learning models also pose more difficulties in deploying them in a federated environment. In this paper, we design a federated two-stage learning framework that augments prototypical federated learning with a cut layer on devices and uses sign-based stochastic gradient descent with the majority vote method on model updates. Cut layer on devices learns informative and low-dimension representations of raw data locally, which helps reduce global model parameters and prevents data leakage. Sign-based SGD with the majority vote method for model updates also helps alleviate communication limitations. Empirically, we show that our system is an efficient and privacy preserving federated learning scheme and suits for general application scenarios.
Towards Heterogeneous Clients with Elastic Federated Learning
Jun 17, 2021
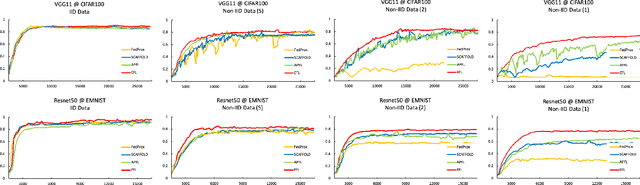
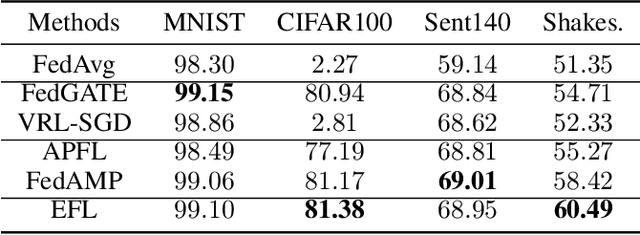
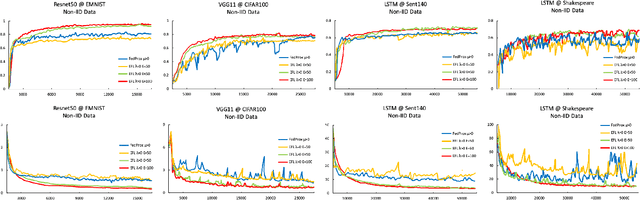
Federated learning involves training machine learning models over devices or data silos, such as edge processors or data warehouses, while keeping the data local. Training in heterogeneous and potentially massive networks introduces bias into the system, which is originated from the non-IID data and the low participation rate in reality. In this paper, we propose Elastic Federated Learning (EFL), an unbiased algorithm to tackle the heterogeneity in the system, which makes the most informative parameters less volatile during training, and utilizes the incomplete local updates. It is an efficient and effective algorithm that compresses both upstream and downstream communications. Theoretically, the algorithm has convergence guarantee when training on the non-IID data at the low participation rate. Empirical experiments corroborate the competitive performance of EFL framework on the robustness and the efficiency.
Binary Random Projections with Controllable Sparsity Patterns
Jun 29, 2020


Random projection is often used to project higher-dimensional vectors onto a lower-dimensional space, while approximately preserving their pairwise distances. It has emerged as a powerful tool in various data processing tasks and has attracted considerable research interest. Partly motivated by the recent discoveries in neuroscience, in this paper we study the problem of random projection using binary matrices with controllable sparsity patterns. Specifically, we proposed two sparse binary projection models that work on general data vectors. Compared with the conventional random projection models with dense projection matrices, our proposed models enjoy significant computational advantages due to their sparsity structure, as well as improved accuracies in empirical evaluations.
Sparse Lifting of Dense Vectors: Unifying Word and Sentence Representations
Nov 05, 2019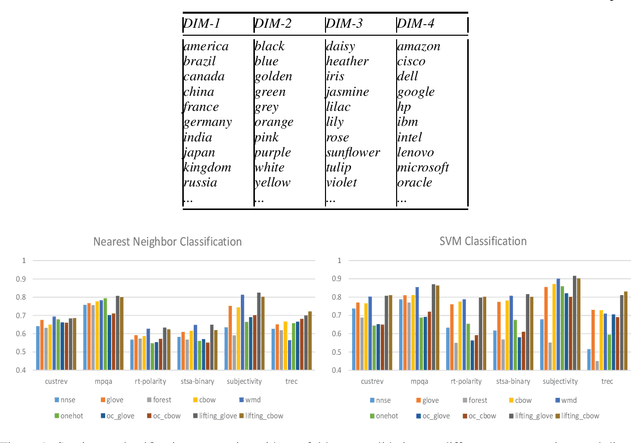
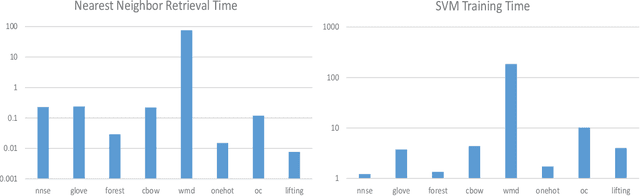
As the first step in automated natural language processing, representing words and sentences is of central importance and has attracted significant research attention. Different approaches, from the early one-hot and bag-of-words representation to more recent distributional dense and sparse representations, were proposed. Despite the successful results that have been achieved, such vectors tend to consist of uninterpretable components and face nontrivial challenge in both memory and computational requirement in practical applications. In this paper, we designed a novel representation model that projects dense word vectors into a higher dimensional space and favors a highly sparse and binary representation of word vectors with potentially interpretable components, while trying to maintain pairwise inner products between original vectors as much as possible. Computationally, our model is relaxed as a symmetric non-negative matrix factorization problem which admits a fast yet effective solution. In a series of empirical evaluations, the proposed model exhibited consistent improvement and high potential in practical applications.
An Augmented Transformer Architecture for Natural Language Generation Tasks
Oct 30, 2019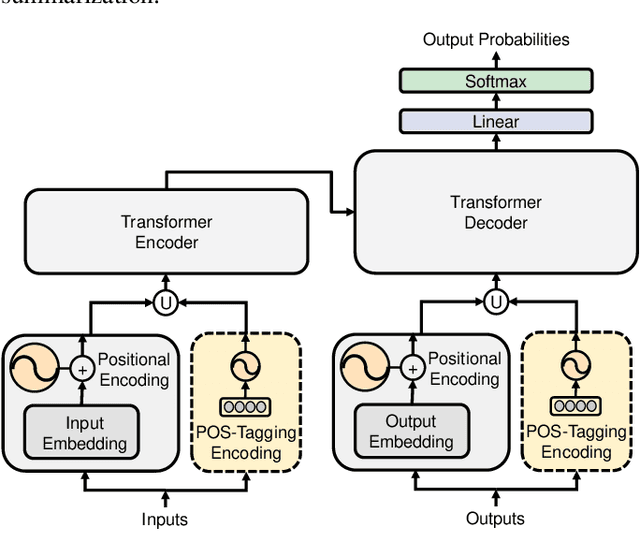
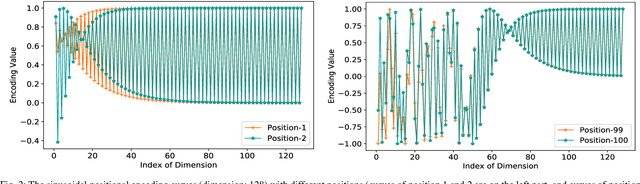
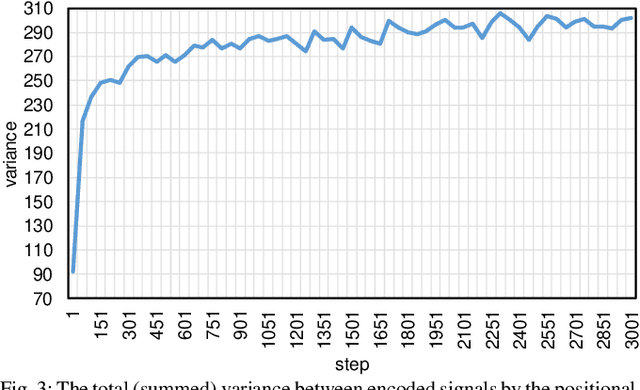
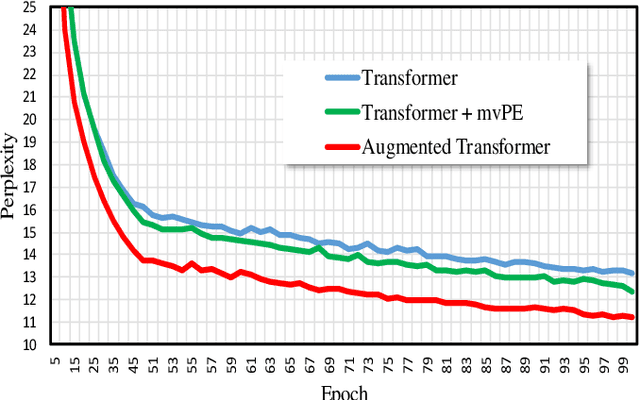
The Transformer based neural networks have been showing significant advantages on most evaluations of various natural language processing and other sequence-to-sequence tasks due to its inherent architecture based superiorities. Although the main architecture of the Transformer has been continuously being explored, little attention was paid to the positional encoding module. In this paper, we enhance the sinusoidal positional encoding algorithm by maximizing the variances between encoded consecutive positions to obtain additional promotion. Furthermore, we propose an augmented Transformer architecture encoded with additional linguistic knowledge, such as the Part-of-Speech (POS) tagging, to boost the performance on some natural language generation tasks, e.g., the automatic translation and summarization tasks. Experiments show that the proposed architecture attains constantly superior results compared to the vanilla Transformer.
Modeling Winner-Take-All Competition in Sparse Binary Projections
Jul 27, 2019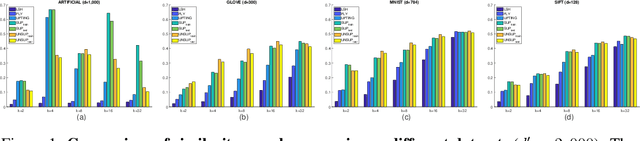

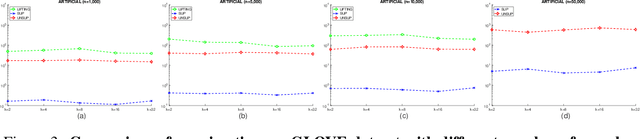
Inspired by the advances in biological science, the study of sparse binary projection models has attracted considerable recent research attention. The models project dense input samples into a higher-dimensional space and output sparse binary vectors after Winner-Take-All competition, subject to the constraint that the projection matrix is also sparse and binary. Following the work along this line, we developed a supervised-WTA model under the supervised setting where training samples with both input and output representations are available, from which the projection matrix can be obtained with a simple, efficient yet effective algorithm. We further extended the model and the algorithm to an unsupervised setting where only the input representation of the samples is available. In a series of empirical evaluation on similarity search tasks, both models reported significantly improved results over the state-of-the-art methods in both search accuracy and running time. The successful results give us strong confidence that the proposed work provides a highly practical tool to real world applications.
AuxBlocks: Defense Adversarial Example via Auxiliary Blocks
Feb 18, 2019
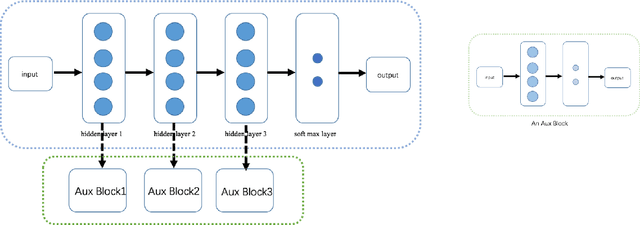

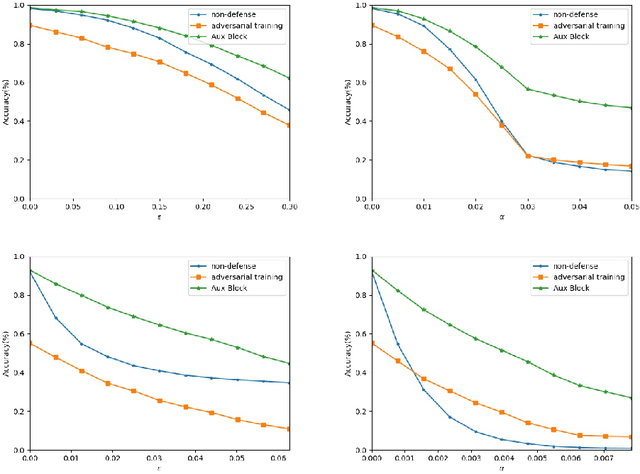
Deep learning models are vulnerable to adversarial examples, which poses an indisputable threat to their applications. However, recent studies observe gradient-masking defenses are self-deceiving methods if an attacker can realize this defense. In this paper, we propose a new defense method based on appending information. We introduce the Aux Block model to produce extra outputs as a self-ensemble algorithm and analytically investigate the robustness mechanism of Aux Block. We have empirically studied the efficiency of our method against adversarial examples in two types of white-box attacks, and found that even in the full white-box attack where an adversary can craft malicious examples from defense models, our method has a more robust performance of about 54.6% precision on Cifar10 dataset and 38.7% precision on Mini-Imagenet dataset. Another advantage of our method is that it is able to maintain the prediction accuracy of the classification model on clean images, and thereby exhibits its high potential in practical applications