 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving LLM Inference via Collaborative Obfuscation (Technical Report)
Mar 02, 2026The rapid development of large language models (LLMs) has driven the widespread adoption of cloud-based LLM inference services, while also bringing prominent privacy risks associated with the transmission and processing of private data in remote inference. For privacy-preserving LLM inference technologies to be practically applied in industrial scenarios, three core requirements must be satisfied simultaneously: (1) Accuracy and efficiency losses should be minimized to mitigate degradation in service experience. (2) The inference process can be run on large-scale clusters consist of heterogeneous legacy xPUs. (3) Compatibility with existing LLM infrastructures should be ensured to reuse their engineering optimizations. To the best of our knowledge, none of the existing privacy-preserving LLM inference methods satisfy all the above constraints while delivering meaningful privacy guarantees. In this paper, we propose AloePri, the first privacy-preserving LLM inference method for industrial applications. AloePri protects both the input and output data by covariant obfuscation, which jointly transforms data and model parameters to achieve better accuracy and privacy. We carefully design the transformation for each model component to ensure inference accuracy and data privacy while keeping full compatibility with existing infrastructures of Language Model as a Service. AloePri has been integrated into an industrial system for the evaluation of mainstream LLMs. The evaluation on Deepseek-V3.1-Terminus model (671B parameters) demonstrates that AloePri causes accuracy loss of 0.0%~3.5% and exhibits efficiency equivalent to that of plaintext inference. Meanwhile, AloePri successfully resists state-of-the-art attacks, with less than 5\% of tokens recovered. To the best of our knowledge, AloePri is the first method to exhibit practical applicability to large-scale models in real-world systems.
Ents: An Efficient Three-party Training Framework for Decision Trees by Communication Optimization
Jun 12, 2024



Multi-party training frameworks for decision trees based on secure multi-party computation enable multiple parties to train high-performance models on distributed private data with privacy preservation. The training process essentially involves frequent dataset splitting according to the splitting criterion (e.g. Gini impurity). However, existing multi-party training frameworks for decision trees demonstrate communication inefficiency due to the following issues: (1) They suffer from huge communication overhead in securely splitting a dataset with continuous attributes. (2) They suffer from huge communication overhead due to performing almost all the computations on a large ring to accommodate the secure computations for the splitting criterion. In this paper, we are motivated to present an efficient three-party training framework, namely Ents, for decision trees by communication optimization. For the first issue, we present a series of training protocols based on the secure radix sort protocols to efficiently and securely split a dataset with continuous attributes. For the second issue, we propose an efficient share conversion protocol to convert shares between a small ring and a large ring to reduce the communication overhead incurred by performing almost all the computations on a large ring. Experimental results from eight widely used datasets show that Ents outperforms state-of-the-art frameworks by $5.5\times \sim 9.3\times$ in communication sizes and $3.9\times \sim 5.3\times$ in communication rounds. In terms of training time, Ents yields an improvement of $3.5\times \sim 6.7\times$. To demonstrate its practicality, Ents requires less than three hours to securely train a decision tree on a widely used real-world dataset (Skin Segmentation) with more than 245,000 samples in the WAN setting.
Private, Efficient, and Accurate: Protecting Models Trained by Multi-party Learning with Differential Privacy
Aug 18, 2022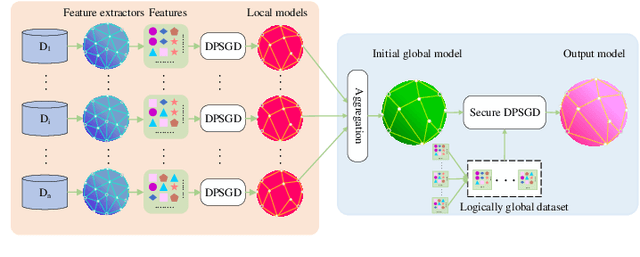
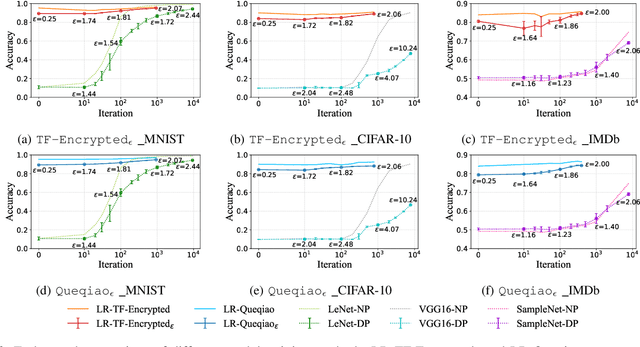
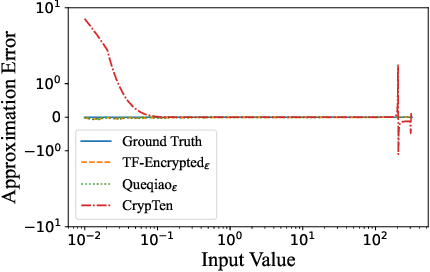
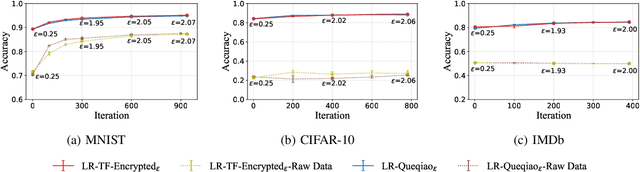
Secure multi-party computation-based machine learning, referred to as MPL, has become an important technology to utilize data from multiple parties with privacy preservation. While MPL provides rigorous security guarantees for the computation process, the models trained by MPL are still vulnerable to attacks that solely depend on access to the models. Differential privacy could help to defend against such attacks. However, the accuracy loss brought by differential privacy and the huge communication overhead of secure multi-party computation protocols make it highly challenging to balance the 3-way trade-off between privacy, efficiency, and accuracy. In this paper, we are motivated to resolve the above issue by proposing a solution, referred to as PEA (Private, Efficient, Accurate), which consists of a secure DPSGD protocol and two optimization methods. First, we propose a secure DPSGD protocol to enforce DPSGD in secret sharing-based MPL frameworks. Second, to reduce the accuracy loss led by differential privacy noise and the huge communication overhead of MPL, we propose two optimization methods for the training process of MPL: (1) the data-independent feature extraction method, which aims to simplify the trained model structure; (2) the local data-based global model initialization method, which aims to speed up the convergence of the model training. We implement PEA in two open-source MPL frameworks: TF-Encrypted and Queqiao. The experimental results on various datasets demonstrate the efficiency and effectiveness of PEA. E.g. when ${\epsilon}$ = 2, we can train a differentially private classification model with an accuracy of 88% for CIFAR-10 within 7 minutes under the LAN setting. This result significantly outperforms the one from CryptGPU, one SOTA MPL framework: it costs more than 16 hours to train a non-private deep neural network model on CIFAR-10 with the same accuracy.
SoK: Training Machine Learning Models over Multiple Sources with Privacy Preservation
Dec 06, 2020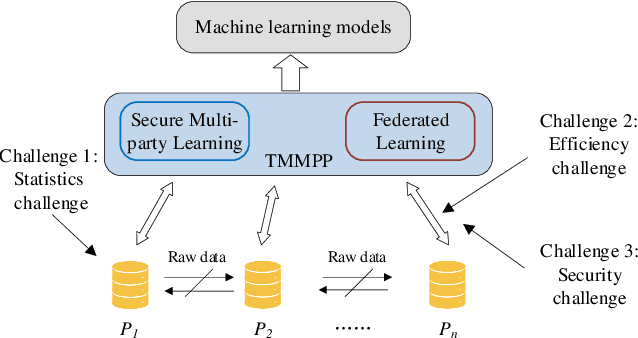
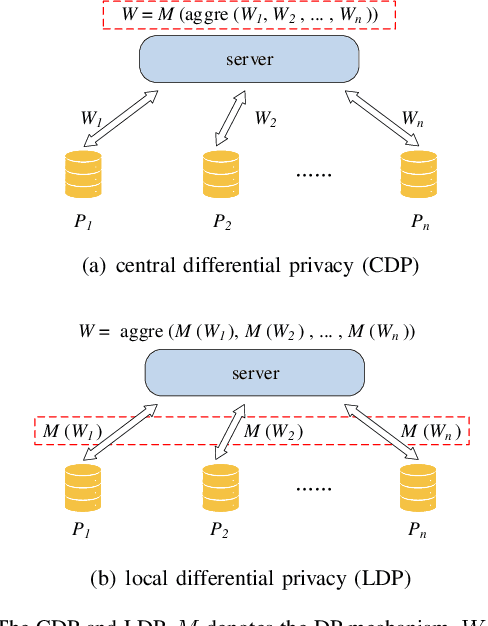
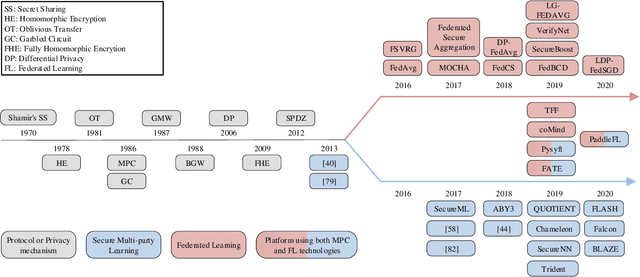
Nowadays, gathering high-quality training data from multiple data controllers with privacy preservation is a key challenge to train high-quality machine learning models. The potential solutions could dramatically break the barriers among isolated data corpus, and consequently enlarge the range of data available for processing. To this end, both academia researchers and industrial vendors are recently strongly motivated to propose two main-stream folders of solutions: 1) Secure Multi-party Learning (MPL for short); and 2) Federated Learning (FL for short). These two solutions have their advantages and limitations when we evaluate them from privacy preservation, ways of communication, communication overhead, format of data, the accuracy of trained models, and application scenarios. Motivated to demonstrate the research progress and discuss the insights on the future directions, we thoroughly investigate these protocols and frameworks of both MPL and FL. At first, we define the problem of training machine learning models over multiple data sources with privacy-preserving (TMMPP for short). Then, we compare the recent studies of TMMPP from the aspects of the technical routes, parties supported, data partitioning, threat model, and supported machine learning models, to show the advantages and limitations. Next, we introduce the state-of-the-art platforms which support online training over multiple data sources. Finally, we discuss the potential directions to resolve the problem of TMMPP.