 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment
May 13, 2021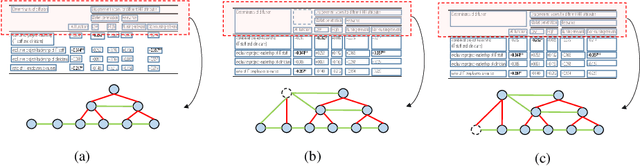
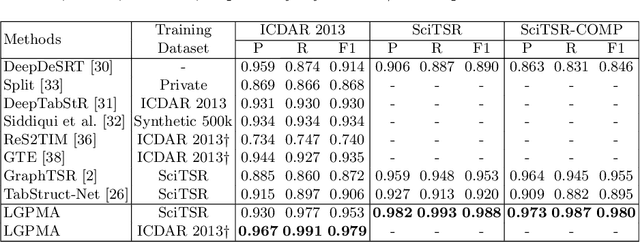
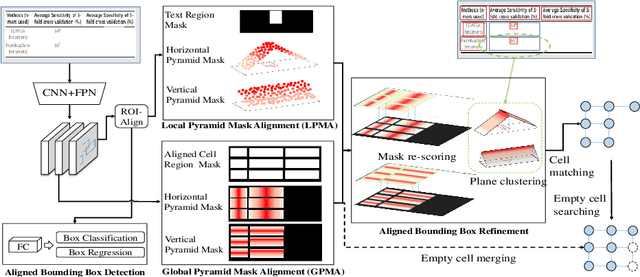
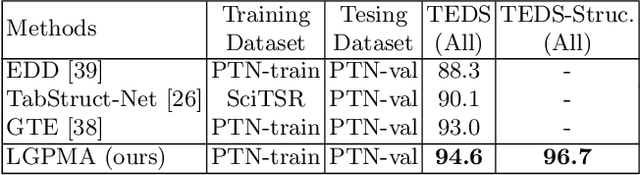
Table structure recognition is a challenging task due to the various structures and complicated cell spanning relations. Previous methods handled the problem starting from elements in different granularities (rows/columns, text regions), which somehow fell into the issues like lossy heuristic rules or neglect of empty cell division. Based on table structure characteristics, we find that obtaining the aligned bounding boxes of text region can effectively maintain the entire relevant range of different cells. However, the aligned bounding boxes are hard to be accurately predicted due to the visual ambiguities. In this paper, we aim to obtain more reliable aligned bounding boxes by fully utilizing the visual information from both text regions in proposed local features and cell relations in global features. Specifically, we propose the framework of Local and Global Pyramid Mask Alignment, which adopts the soft pyramid mask learning mechanism in both the local and global feature maps. It allows the predicted boundaries of bounding boxes to break through the limitation of original proposals. A pyramid mask re-scoring module is then integrated to compromise the local and global information and refine the predicted boundaries. Finally, we propose a robust table structure recovery pipeline to obtain the final structure, in which we also effectively solve the problems of empty cells locating and division. Experimental results show that the proposed method achieves competitive and even new state-of-the-art performance on several public benchmarks.
PolarDet: A Fast, More Precise Detector for Rotated Target in Aerial Images
Oct 17, 2020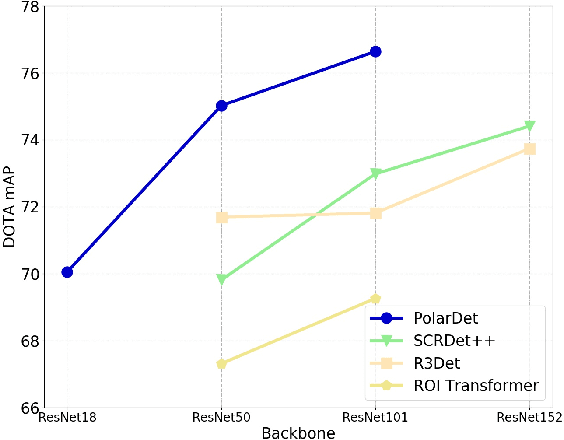

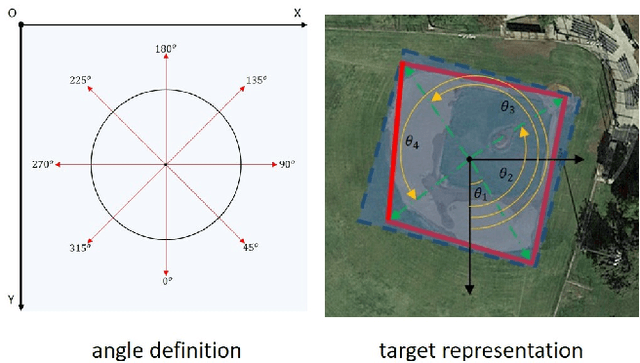

Fast and precise object detection for high-resolution aerial images has been a challenging task over the years. Due to the sharp variations on object scale, rotation, and aspect ratio, most existing methods are inefficient and imprecise. In this paper, we represent the oriented objects by polar method in polar coordinate and propose PolarDet, a fast and accurate one-stage object detector based on that representation. Our detector introduces a sub-pixel center semantic structure to further improve classifying veracity. PolarDet achieves nearly all SOTA performance in aerial object detection tasks with faster inference speed. In detail, our approach obtains the SOTA results on DOTA, UCAS-AOD, HRSC with 76.64\% mAP, 97.01\% mAP, and 90.46\% mAP respectively. Most noticeably, our PolarDet gets the best performance and reaches the fastest speed(32fps) at the UCAS-AOD dataset.
MAFF-Net: Filter False Positive for 3D Vehicle Detection with Multi-modal Adaptive Feature Fusion
Sep 23, 2020

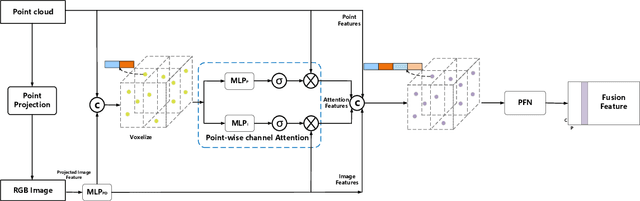
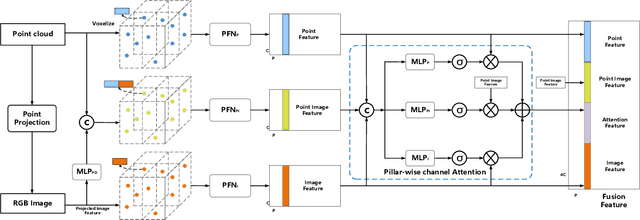
3D vehicle detection based on multi-modal fusion is an important task of many applications such as autonomous driving. Although significant progress has been made, we still observe two aspects that need to be further improvement: First, the specific gain that camera images can bring to 3D detection is seldom explored by previous works. Second, many fusion algorithms run slowly, which is essential for applications with high real-time requirements(autonomous driving). To this end, we propose an end-to-end trainable single-stage multi-modal feature adaptive network in this paper, which uses image information to effectively reduce false positive of 3D detection and has a fast detection speed. A multi-modal adaptive feature fusion module based on channel attention mechanism is proposed to enable the network to adaptively use the feature of each modal. Based on the above mechanism, two fusion technologies are proposed to adapt to different usage scenarios: PointAttentionFusion is suitable for filtering simple false positive and faster; DenseAttentionFusion is suitable for filtering more difficult false positive and has better overall performance. Experimental results on the KITTI dataset demonstrate significant improvement in filtering false positive over the approach using only point cloud data. Furthermore, the proposed method can provide competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark.
Extreme Network Compression via Filter Group Approximation
Jul 31, 2018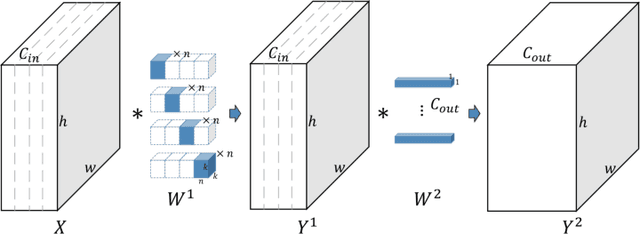

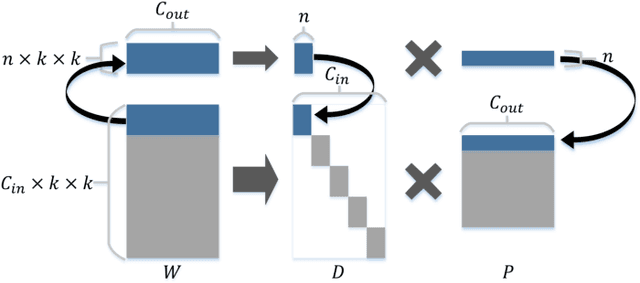
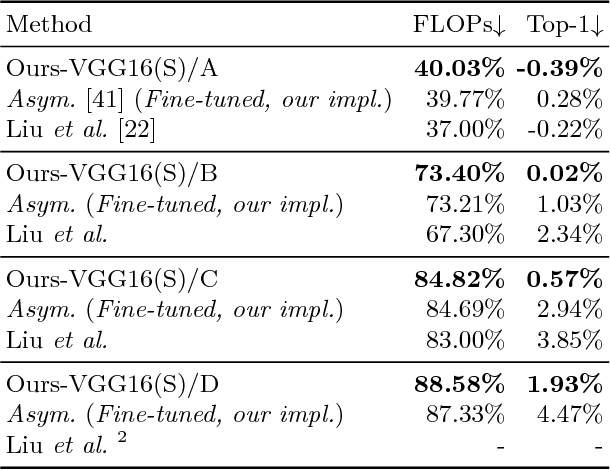
In this paper we propose a novel decomposition method based on filter group approximation, which can significantly reduce the redundancy of deep convolutional neural networks (CNNs) while maintaining the majority of feature representation. Unlike other low-rank decomposition algorithms which operate on spatial or channel dimension of filters, our proposed method mainly focuses on exploiting the filter group structure for each layer. For several commonly used CNN models, including VGG and ResNet, our method can reduce over 80% floating-point operations (FLOPs) with less accuracy drop than state-of-the-art methods on various image classification datasets. Besides, experiments demonstrate that our method is conducive to alleviating degeneracy of the compressed network, which hurts the convergence and performance of the network.