 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Compositional Neural Language Model
Feb 26, 2018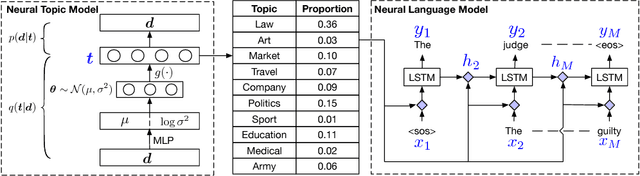


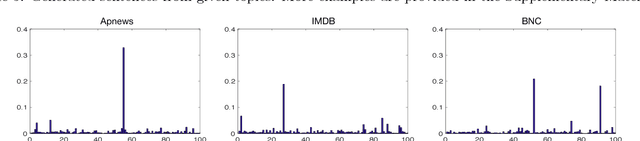
We propose a Topic Compositional Neural Language Model (TCNLM), a novel method designed to simultaneously capture both the global semantic meaning and the local word ordering structure in a document. The TCNLM learns the global semantic coherence of a document via a neural topic model, and the probability of each learned latent topic is further used to build a Mixture-of-Experts (MoE) language model, where each expert (corresponding to one topic) is a recurrent neural network (RNN) that accounts for learning the local structure of a word sequence. In order to train the MoE model efficiently, a matrix factorization method is applied, by extending each weight matrix of the RNN to be an ensemble of topic-dependent weight matrices. The degree to which each member of the ensemble is used is tied to the document-dependent probability of the corresponding topics. Experimental results on several corpora show that the proposed approach outperforms both a pure RNN-based model and other topic-guided language models. Further, our model yields sensible topics, and also has the capacity to generate meaningful sentences conditioned on given topics.
Wide Compression: Tensor Ring Nets
Feb 25, 2018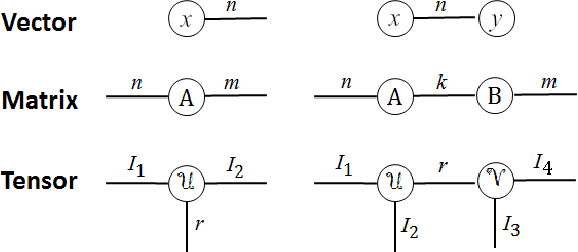

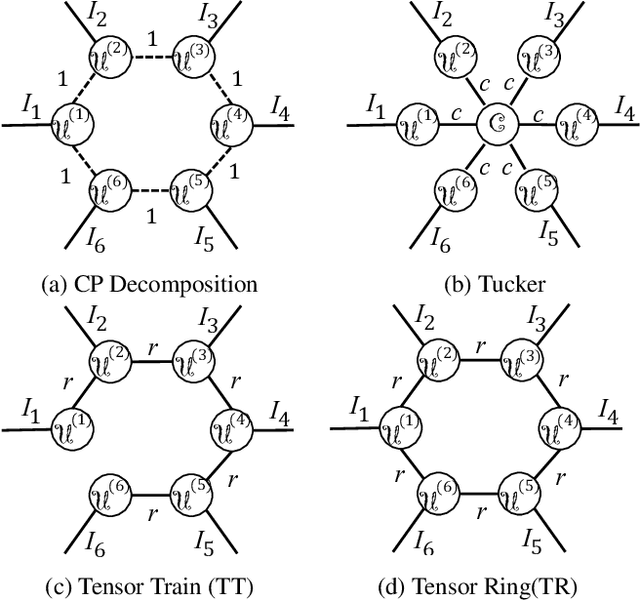
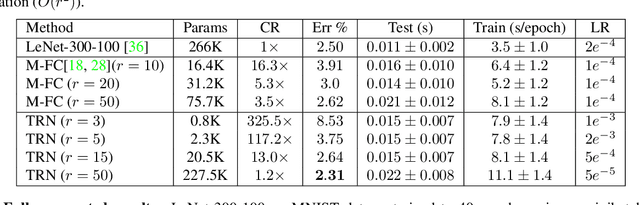
Deep neural networks have demonstrated state-of-the-art performance in a variety of real-world applications. In order to obtain performance gains, these networks have grown larger and deeper, containing millions or even billions of parameters and over a thousand layers. The trade-off is that these large architectures require an enormous amount of memory, storage, and computation, thus limiting their usability. Inspired by the recent tensor ring factorization, we introduce Tensor Ring Networks (TR-Nets), which significantly compress both the fully connected layers and the convolutional layers of deep neural networks. Our results show that our TR-Nets approach {is able to compress LeNet-5 by $11\times$ without losing accuracy}, and can compress the state-of-the-art Wide ResNet by $243\times$ with only 2.3\% degradation in {Cifar10 image classification}. Overall, this compression scheme shows promise in scientific computing and deep learning, especially for emerging resource-constrained devices such as smartphones, wearables, and IoT devices.
InverseNet: Solving Inverse Problems with Splitting Networks
Dec 01, 2017
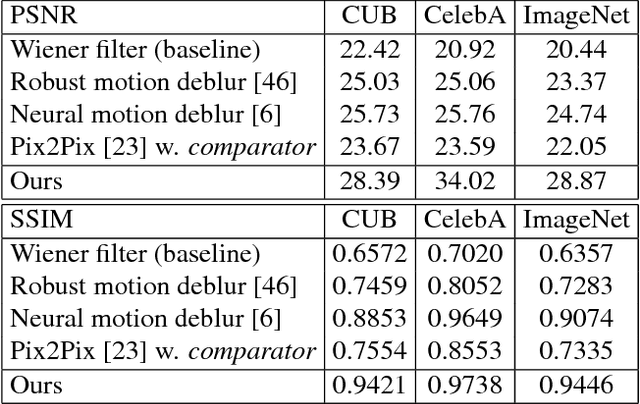
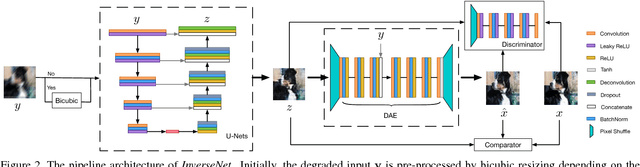
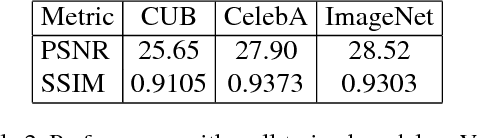
We propose a new method that uses deep learning techniques to solve the inverse problems. The inverse problem is cast in the form of learning an end-to-end mapping from observed data to the ground-truth. Inspired by the splitting strategy widely used in regularized iterative algorithm to tackle inverse problems, the mapping is decomposed into two networks, with one handling the inversion of the physical forward model associated with the data term and one handling the denoising of the output from the former network, i.e., the inverted version, associated with the prior/regularization term. The two networks are trained jointly to learn the end-to-end mapping, getting rid of a two-step training. The training is annealing as the intermediate variable between these two networks bridges the gap between the input (the degraded version of output) and output and progressively approaches to the ground-truth. The proposed network, referred to as InverseNet, is flexible in the sense that most of the existing end-to-end network structure can be leveraged in the first network and most of the existing denoising network structure can be used in the second one. Extensive experiments on both synthetic data and real datasets on the tasks, motion deblurring, super-resolution, and colorization, demonstrate the efficiency and accuracy of the proposed method compared with other image processing algorithms.
Zero-Shot Learning via Class-Conditioned Deep Generative Models
Nov 19, 2017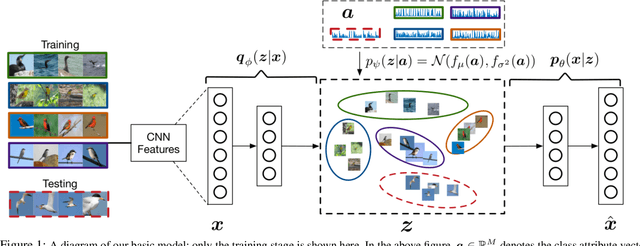
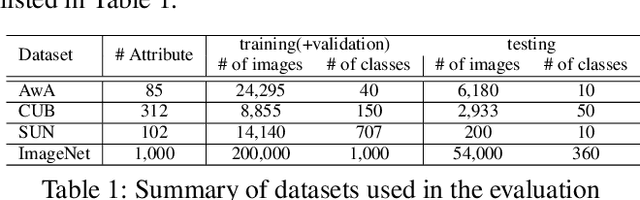
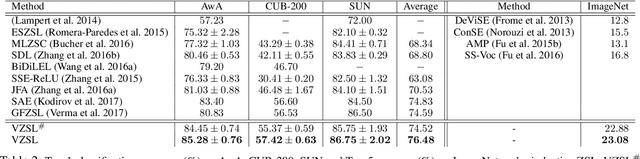
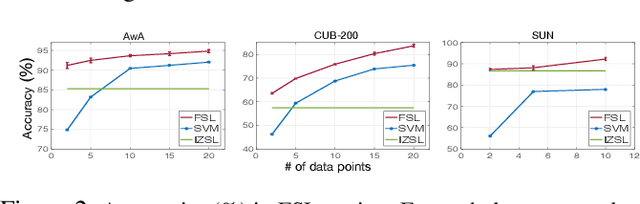
We present a deep generative model for learning to predict classes not seen at training time. Unlike most existing methods for this problem, that represent each class as a point (via a semantic embedding), we represent each seen/unseen class using a class-specific latent-space distribution, conditioned on class attributes. We use these latent-space distributions as a prior for a supervised variational autoencoder (VAE), which also facilitates learning highly discriminative feature representations for the inputs. The entire framework is learned end-to-end using only the seen-class training data. The model infers corresponding attributes of a test image by maximizing the VAE lower bound; the inferred attributes may be linked to labels not seen when training. We further extend our model to a (1) semi-supervised/transductive setting by leveraging unlabeled unseen-class data via an unsupervised learning module, and (2) few-shot learning where we also have a small number of labeled inputs from the unseen classes. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of benchmark data sets.
A Convergence Analysis for A Class of Practical Variance-Reduction Stochastic Gradient MCMC
Sep 04, 2017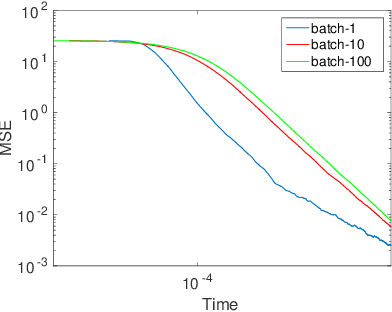
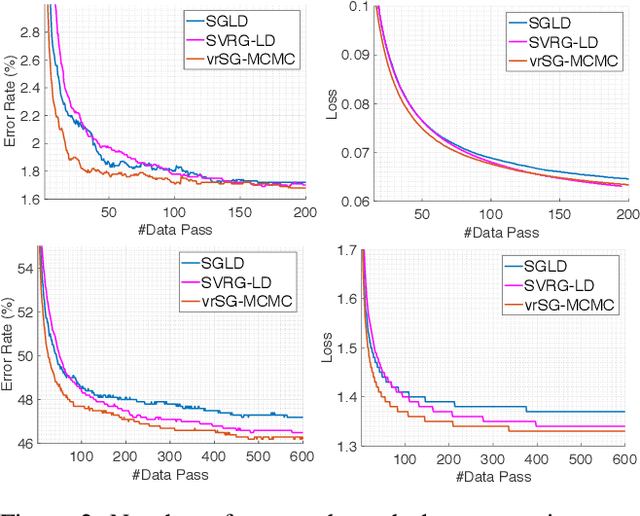
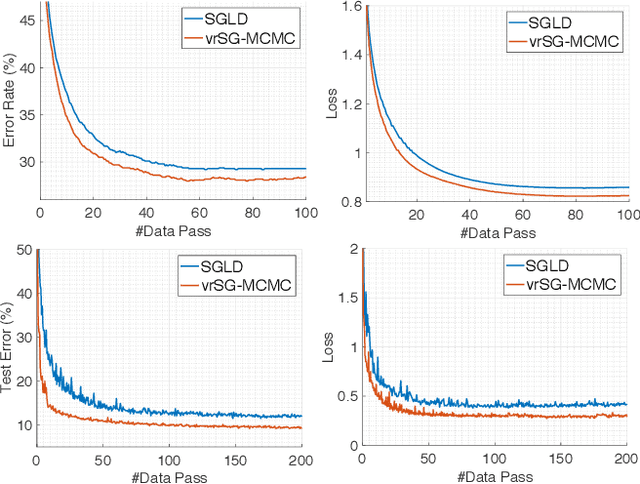
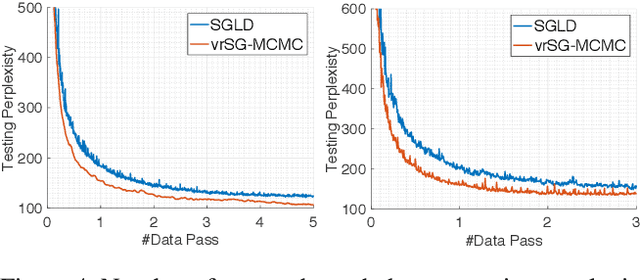
Stochastic gradient Markov Chain Monte Carlo (SG-MCMC) has been developed as a flexible family of scalable Bayesian sampling algorithms. However, there has been little theoretical analysis of the impact of minibatch size to the algorithm's convergence rate. In this paper, we prove that under a limited computational budget/time, a larger minibatch size leads to a faster decrease of the mean squared error bound (thus the fastest one corresponds to using full gradients), which motivates the necessity of variance reduction in SG-MCMC. Consequently, by borrowing ideas from stochastic optimization, we propose a practical variance-reduction technique for SG-MCMC, that is efficient in both computation and storage. We develop theory to prove that our algorithm induces a faster convergence rate than standard SG-MCMC. A number of large-scale experiments, ranging from Bayesian learning of logistic regression to deep neural networks, validate the theory and demonstrate the superiority of the proposed variance-reduction SG-MCMC framework.
Earliness-Aware Deep Convolutional Networks for Early Time Series Classification
Nov 14, 2016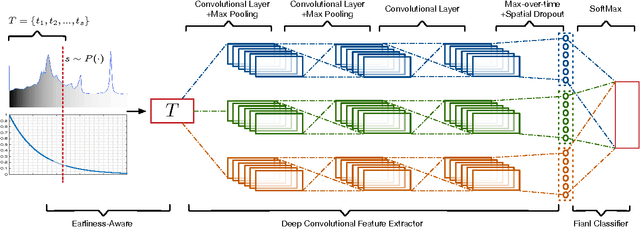
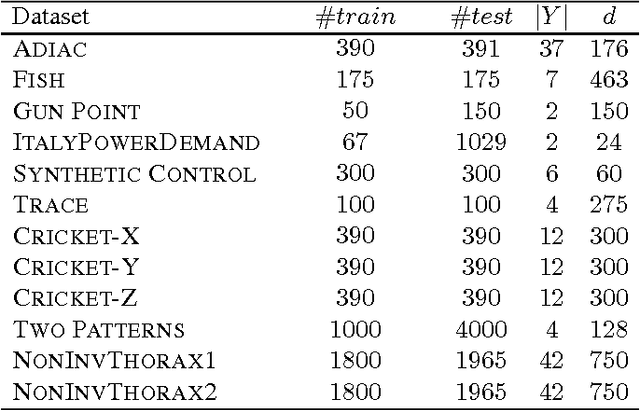
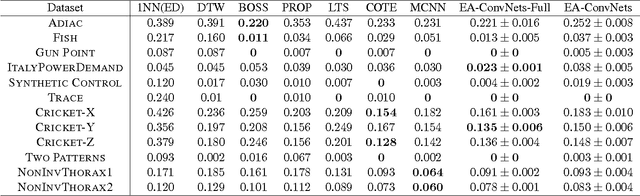
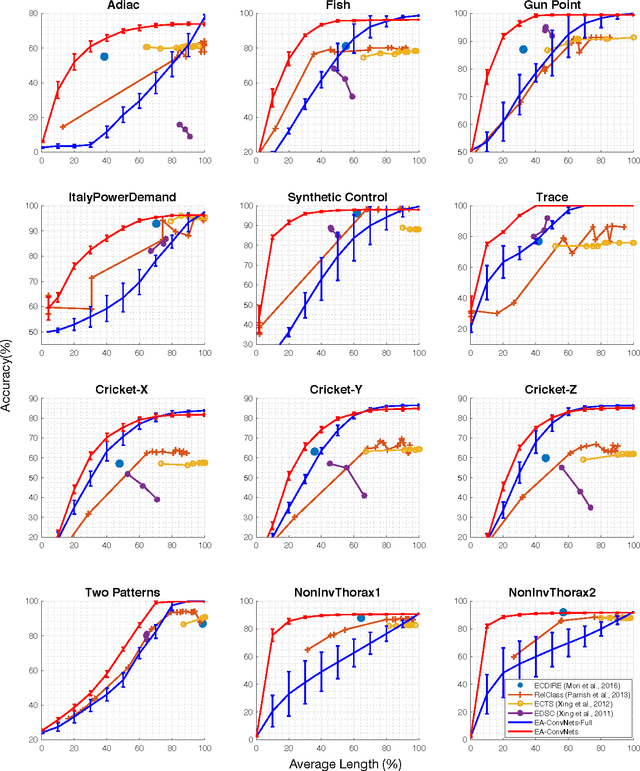
We present Earliness-Aware Deep Convolutional Networks (EA-ConvNets), an end-to-end deep learning framework, for early classification of time series data. Unlike most existing methods for early classification of time series data, that are designed to solve this problem under the assumption of the availability of a good set of pre-defined (often hand-crafted) features, our framework can jointly perform feature learning (by learning a deep hierarchy of \emph{shapelets} capturing the salient characteristics in each time series), along with a dynamic truncation model to help our deep feature learning architecture focus on the early parts of each time series. Consequently, our framework is able to make highly reliable early predictions, outperforming various state-of-the-art methods for early time series classification, while also being competitive when compared to the state-of-the-art time series classification algorithms that work with \emph{fully observed} time series data. To the best of our knowledge, the proposed framework is the first to perform data-driven (deep) feature learning in the context of early classification of time series data. We perform a comprehensive set of experiments, on several benchmark data sets, which demonstrate that our method yields significantly better predictions than various state-of-the-art methods designed for early time series classification. In addition to obtaining high accuracies, our experiments also show that the learned deep shapelets based features are also highly interpretable and can help gain better understanding of the underlying characteristics of time series data.