 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreferRec: Learning and Transferring Pareto Preferences for Multi-objective Re-ranking
Mar 23, 2026Multi-objective re-ranking has become a critical component of modern multi-stage recommender systems, as it tasked to balance multiple conflicting objectives such as accuracy, diversity, and fairness. Existing multi-objective re-ranking methods typically optimize aggregate objectives at the item level using static or handcrafted preference weights. This design overlooks that users inherently exhibit Pareto-optimal preferences at the intent level, reflecting personalized trade-offs among objectives rather than fixed weight combinations. Moreover, most approaches treat re-ranking task for each user as an isolated problem, and repeatedly learn the preferences from scratch. Such a paradigm not only incurs high computational cost, but also ignores the fact that users often share similar preference trade-off structures across objectives. Inspired by the existence of homogeneous multi-objective optimization spaces where Pareto-optimal patterns are transferable, we propose PreferRec, a novel framework that explicitly models and transfers Pareto preferences across users. Specifically, PreferRec is built upon three tightly coupled components: Preference-Aware Pareto Learning aims to capture user intrinsic trade-offs among multiple conflicting objectives at the intent level. By learning Pareto preference representations from re-ranking populations, this component explicitly models how users prioritize different objectives under diverse contexts. Knowledge-Guided Transfer facilitates efficient cross-user knowledge transfer by distilling shared optimization patterns across homogeneous optimization spaces. The transferred knowledge is then used to guide solution selection and personalized re-ranking, biasing the optimization process toward high-quality regions of the Pareto front while preserving user-specific preference characteristics.
Evolving Jailbreaks: Automated Multi-Objective Long-Tail Attacks on Large Language Models
Mar 20, 2026Large Language Models (LLMs) have been widely deployed, especially through free Web-based applications that expose them to diverse user-generated inputs, including those from long-tail distributions such as low-resource languages and encrypted private data. This open-ended exposure increases the risk of jailbreak attacks that undermine model safety alignment. While recent studies have shown that leveraging long-tail distributions can facilitate such jailbreaks, existing approaches largely rely on handcrafted rules, limiting the systematic evaluation of these security and privacy vulnerabilities. In this work, we present EvoJail, an automated framework for discovering long-tail distribution attacks via multi-objective evolutionary search. EvoJail formulates long-tail attack prompt generation as a multi-objective optimization problem that jointly maximizes attack effectiveness and minimizes output perplexity, and introduces a semantic-algorithmic solution representation to capture both high-level semantic intent and low-level structural transformations of encryption-decryption logic. Building upon this representation, EvoJail integrates LLM-assisted operators into a multi-objective evolutionary framework, enabling adaptive and semantically informed mutation and crossover for efficiently exploring a highly structured and open-ended search space. Extensive experiments demonstrate that EvoJail consistently discovers diverse and effective long-tail jailbreak strategies, achieving competitive performance with existing methods in both individual and ensemble level.
Evolutionary Reinforcement Learning based AI tutor for Socratic Interdisciplinary Instruction
Dec 12, 2025



Cultivating higher-order cognitive abilities -- such as knowledge integration, critical thinking, and creativity -- in modern STEM education necessitates a pedagogical shift from passive knowledge transmission to active Socratic construction. Although Large Language Models (LLMs) hold promise for STEM Interdisciplinary education, current methodologies employing Prompt Engineering (PE), Supervised Fine-tuning (SFT), or standard Reinforcement Learning (RL) often fall short of supporting this paradigm. Existing methods are hindered by three fundamental challenges: the inability to dynamically model latent student cognitive states; severe reward sparsity and delay inherent in long-term educational goals; and a tendency toward policy collapse lacking strategic diversity due to reliance on behavioral cloning. Recognizing the unobservability and dynamic complexity of these interactions, we formalize the Socratic Interdisciplinary Instructional Problem (SIIP) as a structured Partially Observable Markov Decision Process (POMDP), demanding simultaneous global exploration and fine-grained policy refinement. To this end, we propose ERL4SIIP, a novel Evolutionary Reinforcement Learning (ERL) framework specifically tailored for this domain. ERL4SIIP integrates: (1) a dynamic student simulator grounded in a STEM knowledge graph for latent state modeling; (2) a Hierarchical Reward Mechanism that decomposes long-horizon goals into dense signals; and (3) a LoRA-Division based optimization strategy coupling evolutionary algorithms for population-level global search with PPO for local gradient ascent.
Surrogate-Assisted Evolutionary Reinforcement Learning Based on Autoencoder and Hyperbolic Neural Network
May 26, 2025Evolutionary Reinforcement Learning (ERL), training the Reinforcement Learning (RL) policies with Evolutionary Algorithms (EAs), have demonstrated enhanced exploration capabilities and greater robustness than using traditional policy gradient. However, ERL suffers from the high computational costs and low search efficiency, as EAs require evaluating numerous candidate policies with expensive simulations, many of which are ineffective and do not contribute meaningfully to the training. One intuitive way to reduce the ineffective evaluations is to adopt the surrogates. Unfortunately, existing ERL policies are often modeled as deep neural networks (DNNs) and thus naturally represented as high-dimensional vectors containing millions of weights, which makes the building of effective surrogates for ERL policies extremely challenging. This paper proposes a novel surrogate-assisted ERL that integrates Autoencoders (AE) and Hyperbolic Neural Networks (HNN). Specifically, AE compresses high-dimensional policies into low-dimensional representations while extracting key features as the inputs for the surrogate. HNN, functioning as a classification-based surrogate model, can learn complex nonlinear relationships from sampled data and enable more accurate pre-selection of the sampled policies without real evaluations. The experiments on 10 Atari and 4 Mujoco games have verified that the proposed method outperforms previous approaches significantly. The search trajectories guided by AE and HNN are also visually demonstrated to be more effective, in terms of both exploration and convergence. This paper not only presents the first learnable policy embedding and surrogate-modeling modules for high-dimensional ERL policies, but also empirically reveals when and why they can be successful.
Automatic Construction of Parallel Algorithm Portfolios for Multi-objective Optimization
Nov 17, 2022



It has been widely observed that there exists no universal best Multi-objective Evolutionary Algorithm (MOEA) dominating all other MOEAs on all possible Multi-objective Optimization Problems (MOPs). In this work, we advocate using the Parallel Algorithm Portfolio (PAP), which runs multiple MOEAs independently in parallel and gets the best out of them, to combine the advantages of different MOEAs. Since the manual construction of PAPs is non-trivial and tedious, we propose to automatically construct high-performance PAPs for solving MOPs. Specifically, we first propose a variant of PAPs, namely MOEAs/PAP, which can better determine the output solution set for MOPs than conventional PAPs. Then, we present an automatic construction approach for MOEAs/PAP with a novel performance metric for evaluating the performance of MOEAs across multiple MOPs. Finally, we use the proposed approach to construct a MOEAs/PAP based on a training set of MOPs and an algorithm configuration space defined by several variants of NSGA-II. Experimental results show that the automatically constructed MOEAs/PAP can even rival the state-of-the-art multi-operator-based MOEAs designed by human experts, demonstrating the huge potential of automatic construction of PAPs in multi-objective optimization.
Neural Network Pruning by Cooperative Coevolution
Apr 12, 2022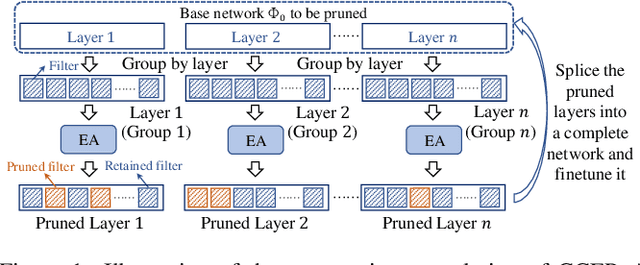
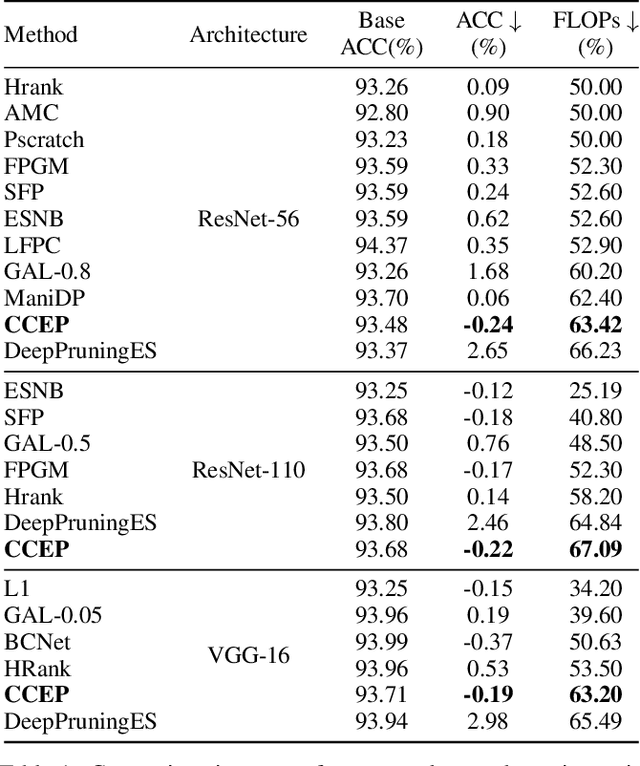

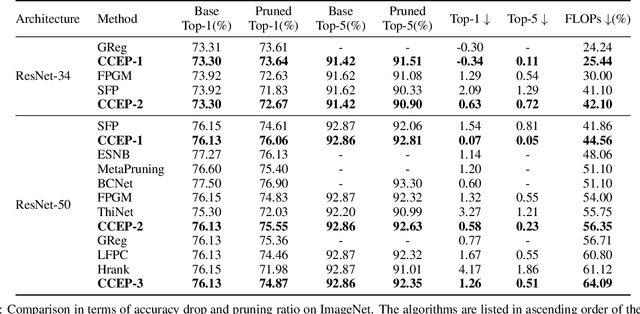
Neural network pruning is a popular model compression method which can significantly reduce the computing cost with negligible loss of accuracy. Recently, filters are often pruned directly by designing proper criteria or using auxiliary modules to measure their importance, which, however, requires expertise and trial-and-error. Due to the advantage of automation, pruning by evolutionary algorithms (EAs) has attracted much attention, but the performance is limited for deep neural networks as the search space can be quite large. In this paper, we propose a new filter pruning algorithm CCEP by cooperative coevolution, which prunes the filters in each layer by EAs separately. That is, CCEP reduces the pruning space by a divide-and-conquer strategy. The experiments show that CCEP can achieve a competitive performance with the state-of-the-art pruning methods, e.g., prune ResNet56 for $63.42\%$ FLOPs on CIFAR10 with $-0.24\%$ accuracy drop, and ResNet50 for $44.56\%$ FLOPs on ImageNet with $0.07\%$ accuracy drop.