 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Optimal Decision Making with Multiple Data Sources and Limited Outcome
Apr 21, 2021
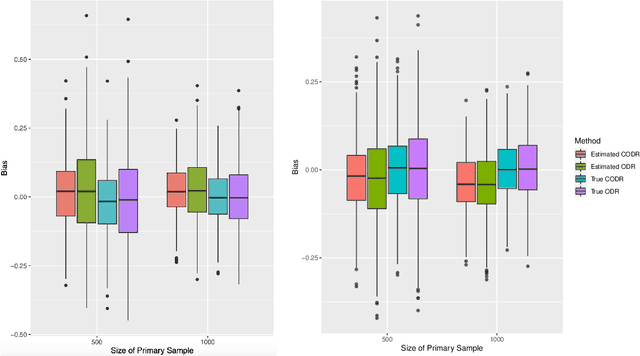
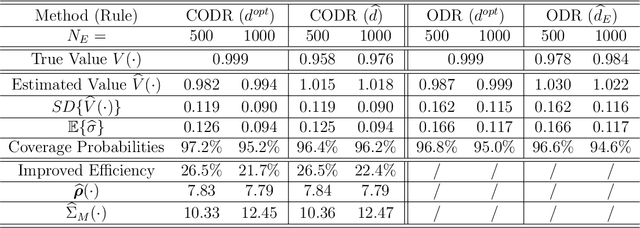
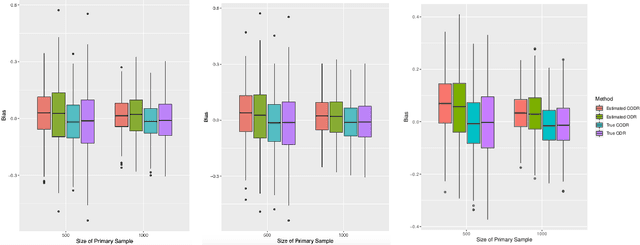
We consider the optimal decision-making problem in a primary sample of interest with multiple auxiliary sources available. The outcome of interest is limited in the sense that it is only observed in the primary sample. In reality, such multiple data sources may belong to different populations and thus cannot be combined directly. This paper proposes a novel calibrated optimal decision rule (CODR) to address the limited outcome, by leveraging the shared pattern in multiple data sources. Under a mild and testable assumption that the conditional means of intermediate outcomes in different samples are equal given baseline covariates and the treatment information, we can show that the calibrated mean outcome of interest under the CODR is unbiased and more efficient than using the primary sample solely. Extensive experiments on simulated datasets demonstrate empirical validity and improvement of the proposed CODR, followed by a real application on the MIMIC-III as the primary sample with auxiliary data from eICU.
Deep Jump Q-Evaluation for Offline Policy Evaluation in Continuous Action Space
Oct 29, 2020

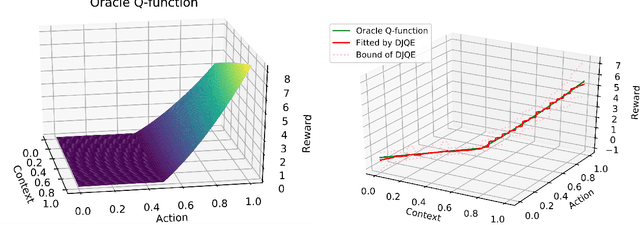
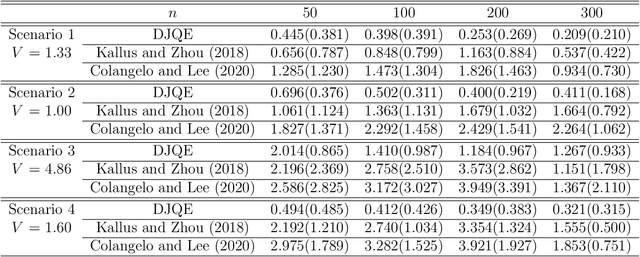
We consider off-policy evaluation (OPE) in continuous action domains, such as dynamic pricing and personalized dose finding. In OPE, one aims to learn the value under a new policy using historical data generated by a different behavior policy. Most existing works on OPE focus on discrete action domains. To handle continuous action space, we develop a brand-new deep jump Q-evaluation method for OPE. The key ingredient of our method lies in adaptively discretizing the action space using deep jump Q-learning. This allows us to apply existing OPE methods in discrete domains to handle continuous actions. Our method is further justified by theoretical results, synthetic and real datasets.
Statistical Inference for Online Decision Making via Stochastic Gradient Descent
Oct 14, 2020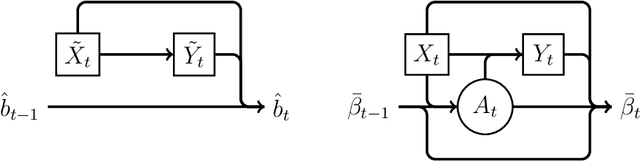
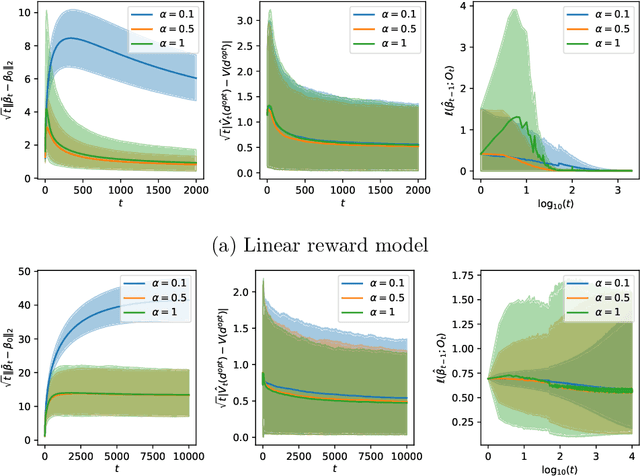
Online decision making aims to learn the optimal decision rule by making personalized decisions and updating the decision rule recursively. It has become easier than before with the help of big data, but new challenges also come along. Since the decision rule should be updated once per step, an offline update which uses all the historical data is inefficient in computation and storage. To this end, we propose a completely online algorithm that can make decisions and update the decision rule online via stochastic gradient descent. It is not only efficient but also supports all kinds of parametric reward models. Focusing on the statistical inference of online decision making, we establish the asymptotic normality of the parameter estimator produced by our algorithm and the online inverse probability weighted value estimator we used to estimate the optimal value. Online plugin estimators for the variance of the parameter and value estimators are also provided and shown to be consistent, so that interval estimation and hypothesis test are possible using our method. The proposed algorithm and theoretical results are tested by simulations and a real data application to news article recommendation.
Statistical Inference for Online Decision-Making: In a Contextual Bandit Setting
Oct 14, 2020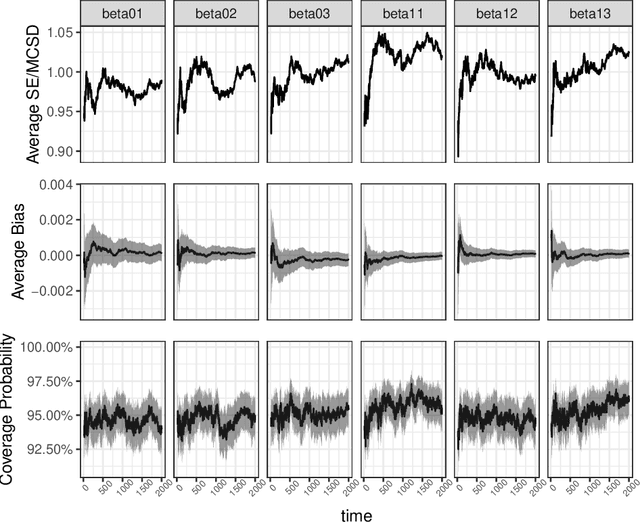
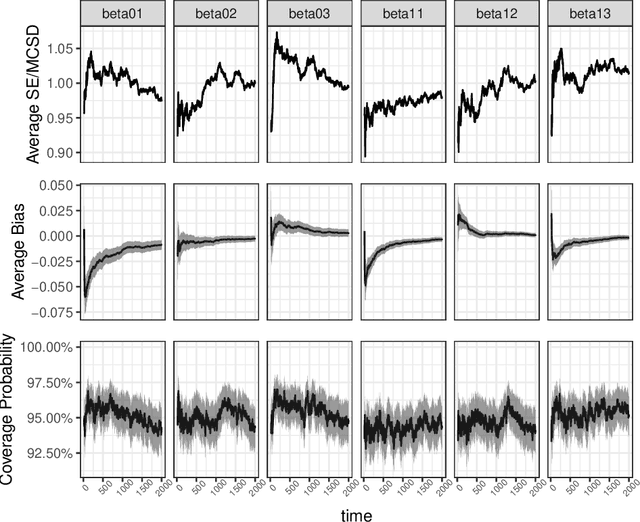
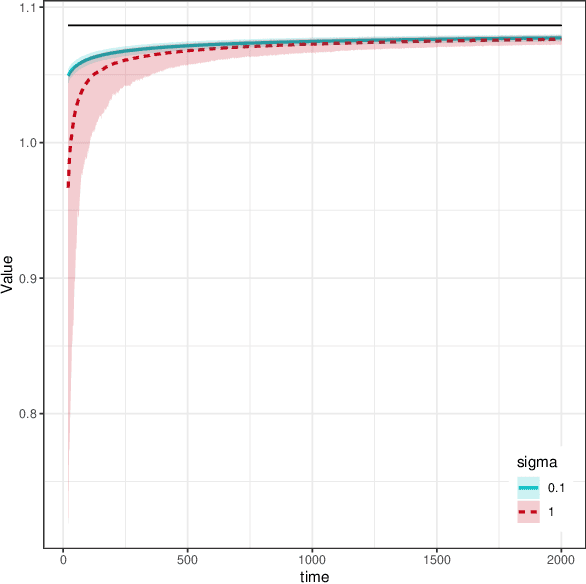
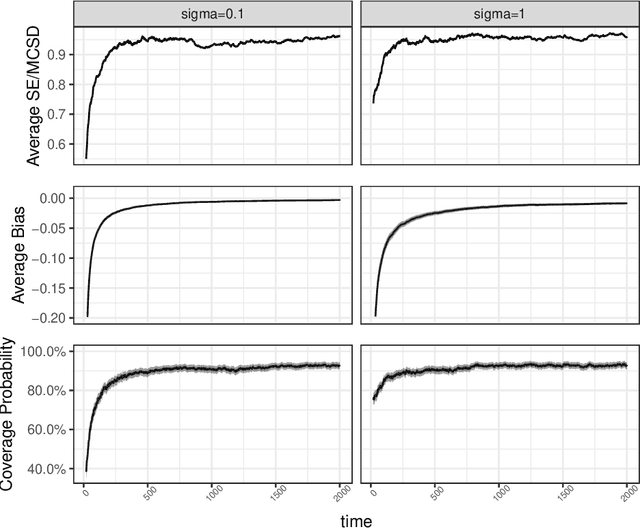
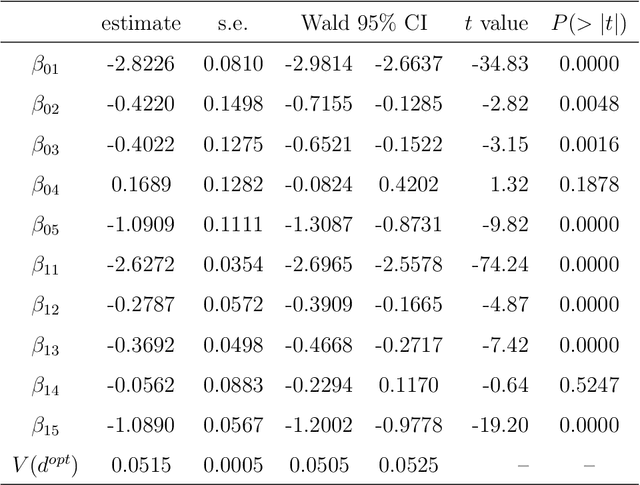
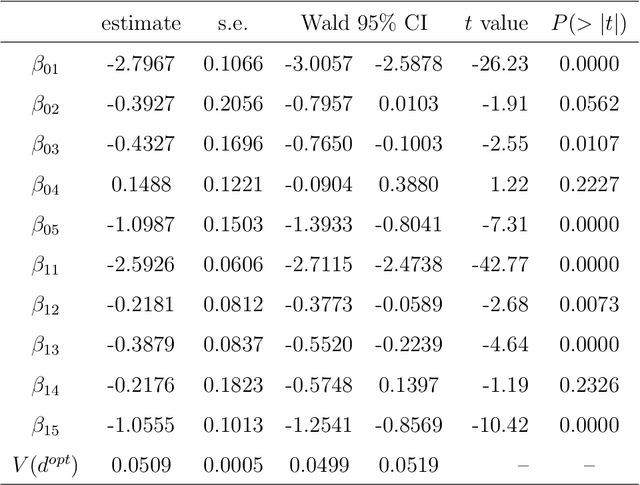
Online decision-making problem requires us to make a sequence of decisions based on incremental information. Common solutions often need to learn a reward model of different actions given the contextual information and then maximize the long-term reward. It is meaningful to know if the posited model is reasonable and how the model performs in the asymptotic sense. We study this problem under the setup of the contextual bandit framework with a linear reward model. The $\varepsilon$-greedy policy is adopted to address the classic exploration-and-exploitation dilemma. Using the martingale central limit theorem, we show that the online ordinary least squares estimator of model parameters is asymptotically normal. When the linear model is misspecified, we propose the online weighted least squares estimator using the inverse propensity score weighting and also establish its asymptotic normality. Based on the properties of the parameter estimators, we further show that the in-sample inverse propensity weighted value estimator is asymptotically normal. We illustrate our results using simulations and an application to a news article recommendation dataset from Yahoo!.
Kernel Assisted Learning for Personalized Dose Finding
Jul 19, 2020
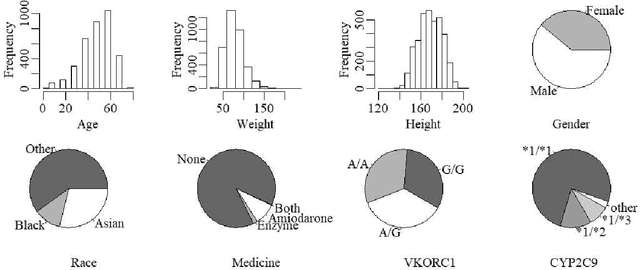
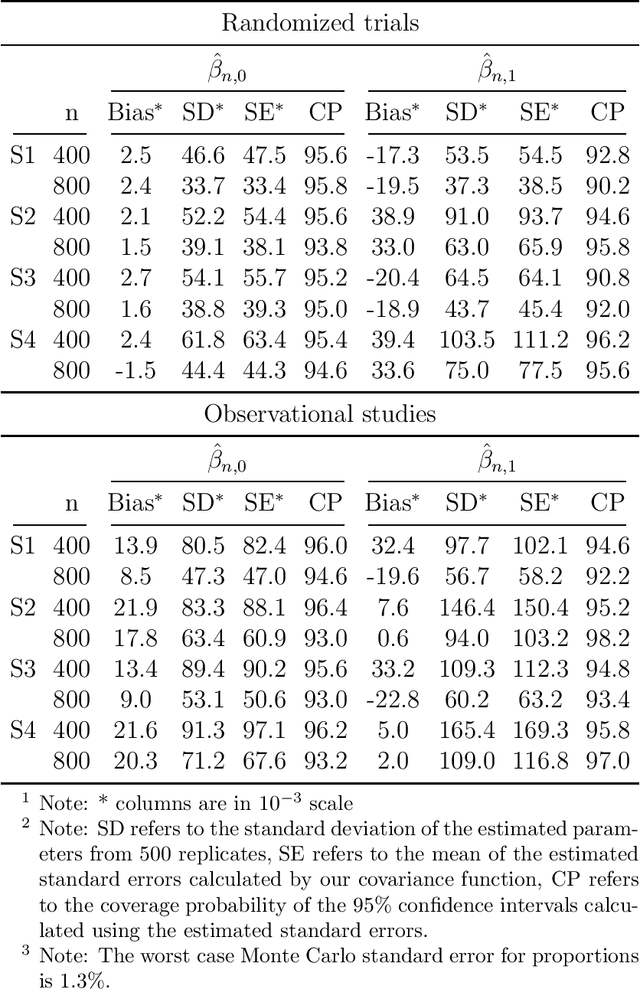
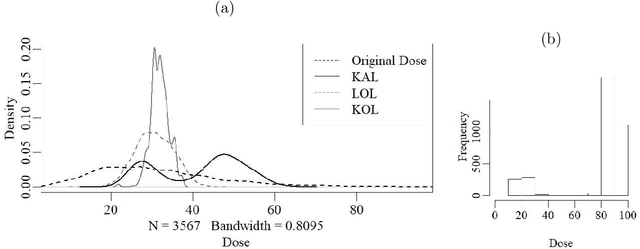
An individualized dose rule recommends a dose level within a continuous safe dose range based on patient level information such as physical conditions, genetic factors and medication histories. Traditionally, personalized dose finding process requires repeating clinical visits of the patient and frequent adjustments of the dosage. Thus the patient is constantly exposed to the risk of underdosing and overdosing during the process. Statistical methods for finding an optimal individualized dose rule can lower the costs and risks for patients. In this article, we propose a kernel assisted learning method for estimating the optimal individualized dose rule. The proposed methodology can also be applied to all other continuous decision-making problems. Advantages of the proposed method include robustness to model misspecification and capability of providing statistical inference for the estimated parameters. In the simulation studies, we show that this method is capable of identifying the optimal individualized dose rule and produces favorable expected outcomes in the population. Finally, we illustrate our approach using data from a warfarin dosing study for thrombosis patients.
Does the Markov Decision Process Fit the Data: Testing for the Markov Property in Sequential Decision Making
Feb 05, 2020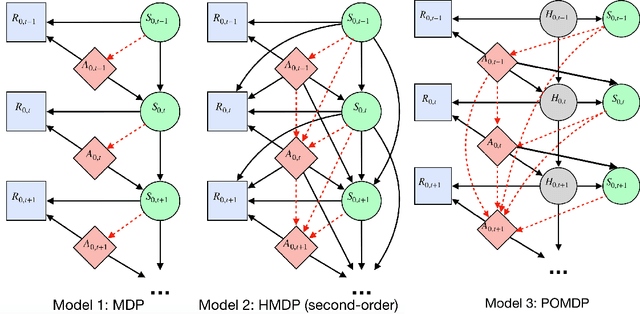

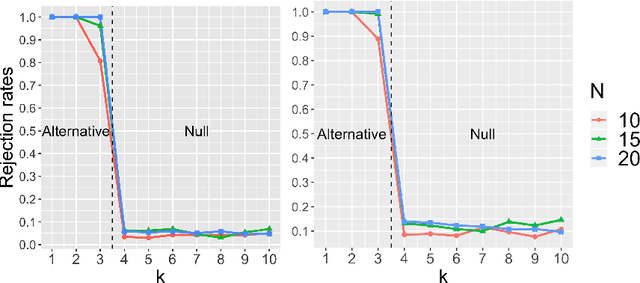
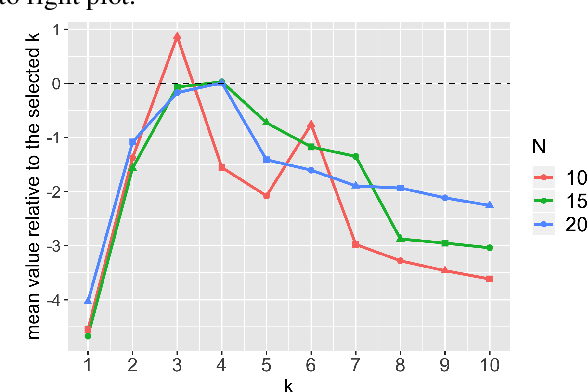
The Markov assumption (MA) is fundamental to the empirical validity of reinforcement learning. In this paper, we propose a novel Forward-Backward Learning procedure to test MA in sequential decision making. The proposed test does not assume any parametric form on the joint distribution of the observed data and plays an important role for identifying the optimal policy in high-order Markov decision processes and partially observable MDPs. We apply our test to both synthetic datasets and a real data example from mobile health studies to illustrate its usefulness.
Robust Learning for Optimal Treatment Decision with NP-Dimensionality
Oct 15, 2015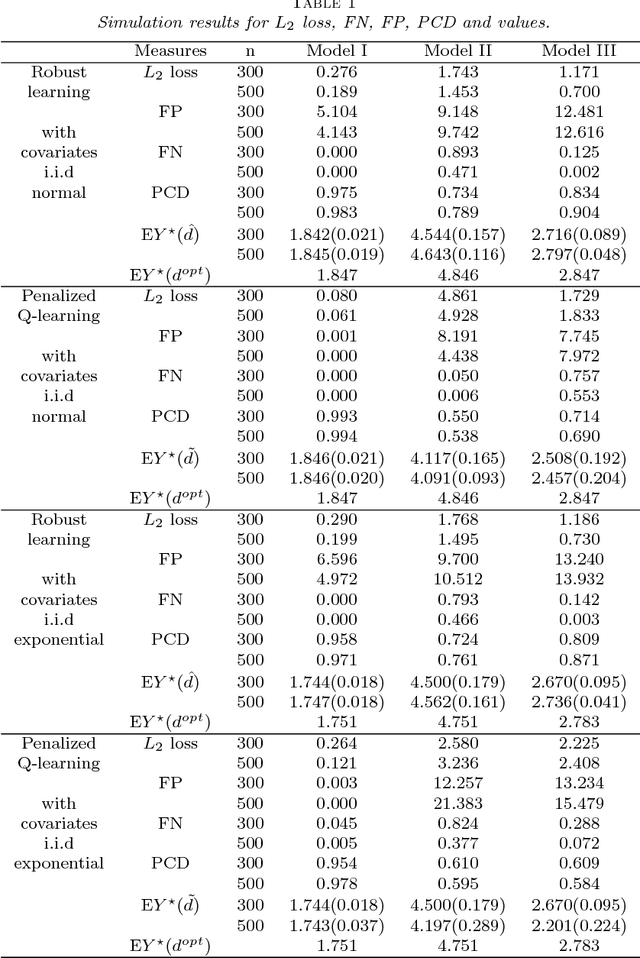


In order to identify important variables that are involved in making optimal treatment decision, Lu et al. (2013) proposed a penalized least squared regression framework for a fixed number of predictors, which is robust against the misspecification of the conditional mean model. Two problems arise: (i) in a world of explosively big data, effective methods are needed to handle ultra-high dimensional data set, for example, with the dimension of predictors is of the non-polynomial (NP) order of the sample size; (ii) both the propensity score and conditional mean models need to be estimated from data under NP dimensionality. In this paper, we propose a two-step estimation procedure for deriving the optimal treatment regime under NP dimensionality. In both steps, penalized regressions are employed with the non-concave penalty function, where the conditional mean model of the response given predictors may be misspecified. The asymptotic properties, such as weak oracle properties, selection consistency and oracle distributions, of the proposed estimators are investigated. In addition, we study the limiting distribution of the estimated value function for the obtained optimal treatment regime. The empirical performance of the proposed estimation method is evaluated by simulations and an application to a depression dataset from the STAR*D study.
Sequential Advantage Selection for Optimal Treatment Regimes
May 20, 2014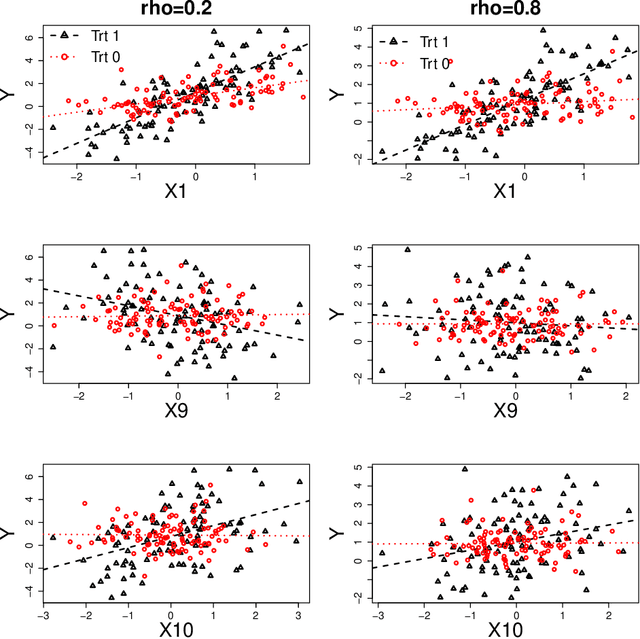
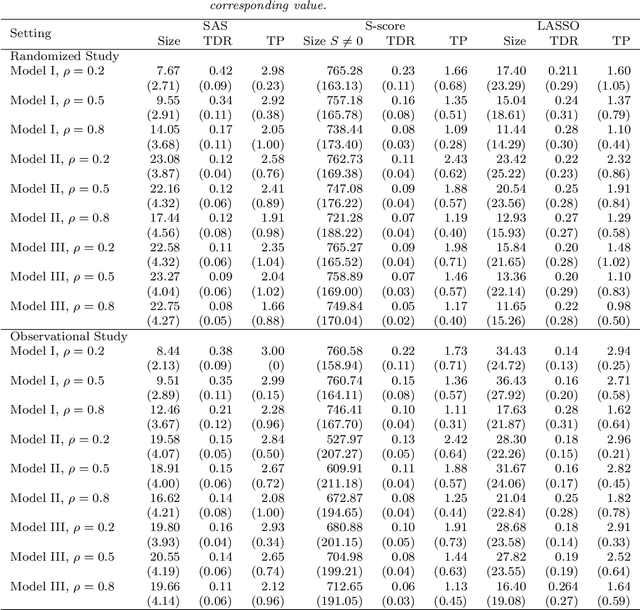
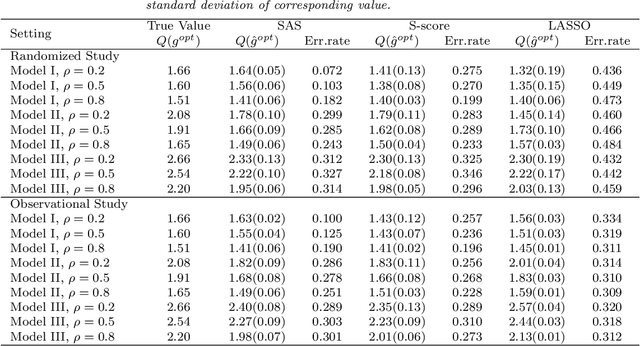
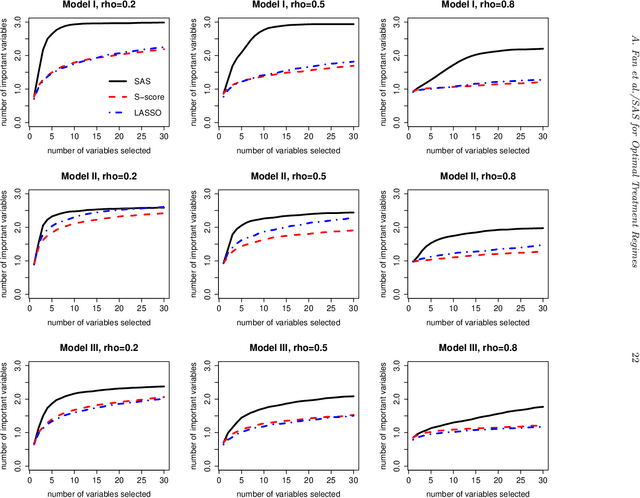
Variable selection for optimal treatment regime in a clinical trial or an observational study is getting more attention. Most existing variable selection techniques focused on selecting variables that are important for prediction, therefore some variables that are poor in prediction but are critical for decision-making may be ignored. A qualitative interaction of a variable with treatment arises when treatment effect changes direction as the value of this variable varies. The qualitative interaction indicates the importance of this variable for decision-making. Gunter et al. (2011) proposed S-score which characterizes the magnitude of qualitative interaction of each variable with treatment individually. In this article, we developed a sequential advantage selection method based on the modified S-score. Our method selects qualitatively interacted variables sequentially, and hence excludes marginally important but jointly unimportant variables {or vice versa}. The optimal treatment regime based on variables selected via joint model is more comprehensive and reliable. With the proposed stopping criteria, our method can handle a large amount of covariates even if sample size is small. Simulation results show our method performs well in practical settings. We further applied our method to data from a clinical trial for depression.