 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of the impact of expert knowledge: How decision support scores impact the effectiveness of automatic knowledge-driven feature engineering (aKDFE)
Apr 08, 2025



Adverse Drug Events (ADEs), harmful medication effects, pose significant healthcare challenges, impacting patient safety and costs. This study evaluates automatic Knowledge-Driven Feature Engineering (aKDFE) for improved ADE prediction from Electronic Health Record (EHR) data, comparing it with automated event-based Knowledge Discovery in Databases (KDD). We investigated how incorporating domain-specific ADE risk scores for prolonged heart QT interval, extracted from the Janusmed Riskprofile (Janusmed) Clinical Decision Support System (CDSS), affects prediction performance using EHR data and medication handling events. Results indicate that, while aKDFE step 1 (event-based feature generation) alone did not significantly improve ADE prediction performance, aKDFE step 2 (patient-centric transformation) enhances the prediction performance. High Area Under the Receiver Operating Characteristic curve (AUROC) values suggest strong feature correlations to the outcome, aligning with the predictive power of patients' prior healthcare history for ADEs. Statistical analysis did not confirm that incorporating the Janusmed information (i) risk scores and (ii) medication route of administration into the model's feature set enhanced predictive performance. However, the patient-centric transformation applied by aKDFE proved to be a highly effective feature engineering approach. Limitations include a single-project focus, potential bias from machine learning pipeline methods, and reliance on AUROC. In conclusion, aKDFE, particularly with patient-centric transformation, improves ADE prediction from EHR data. Future work will explore attention-based models, event feature sequences, and automatic methods for incorporating domain knowledge into the aKDFE framework.
Examination of Code generated by Large Language Models
Aug 29, 2024



Large language models (LLMs), such as ChatGPT and Copilot, are transforming software development by automating code generation and, arguably, enable rapid prototyping, support education, and boost productivity. Therefore, correctness and quality of the generated code should be on par with manually written code. To assess the current state of LLMs in generating correct code of high quality, we conducted controlled experiments with ChatGPT and Copilot: we let the LLMs generate simple algorithms in Java and Python along with the corresponding unit tests and assessed the correctness and the quality (coverage) of the generated (test) codes. We observed significant differences between the LLMs, between the languages, between algorithm and test codes, and over time. The present paper reports these results together with the experimental methods allowing repeated and comparable assessments for more algorithms, languages, and LLMs over time.
Data-Driven Ground-Fault Location Method in Distribution Power System With Distributed Generation
Feb 22, 2024The recent increase in renewable energy penetration at the distribution level introduces a multi-directional power flow that outdated traditional fault location techniques. To this extent, the development of new methods is needed to ensure fast and accurate fault localization and, hence, strengthen power system reliability. This paper proposes a data-driven ground fault location method for the power distribution system. An 11-bus 20 kV power system is modeled in Matlab/Simulink to simulate ground faults. The faults are generated at different locations and under various system operational states. Time-domain faulted three-phase voltages at the system substation are then analyzed with discrete wavelet transform. Statistical quantities of the processed data are eventually used to train an Artificial Neural Network (ANN) to find a mapping between computed voltage features and faults. Specifically, three ANNs allow the prediction of faulted phase, faulted branch, and fault distance from the system substation separately. According to the results, the method shows good potential, with a total relative error of 0,4% for fault distance prediction. The method is applied to datasets with unknown system states to test robustness.
An Approach to Ordering Objectives and Pareto Efficient Solutions
May 30, 2022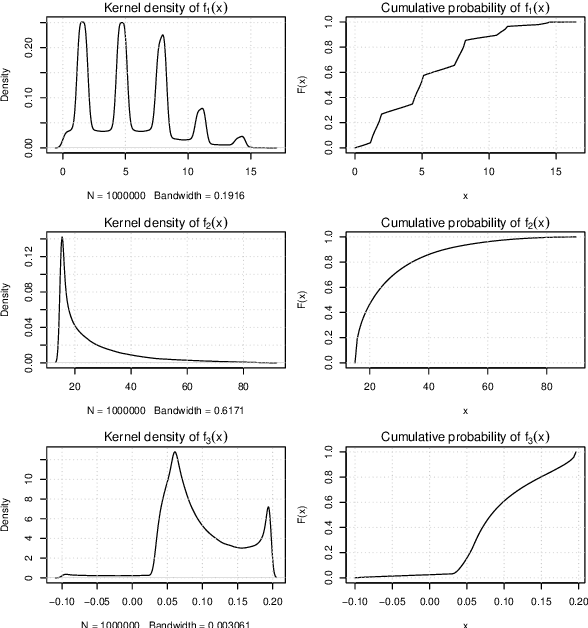
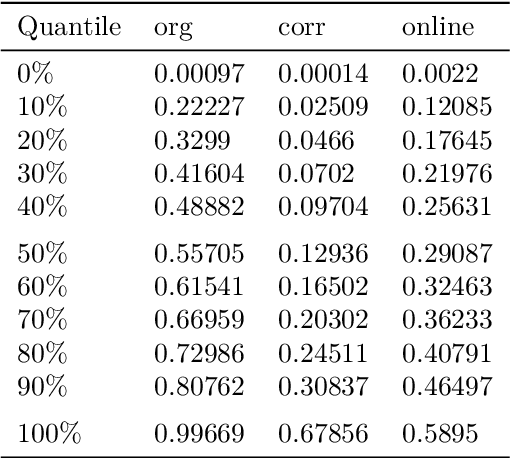
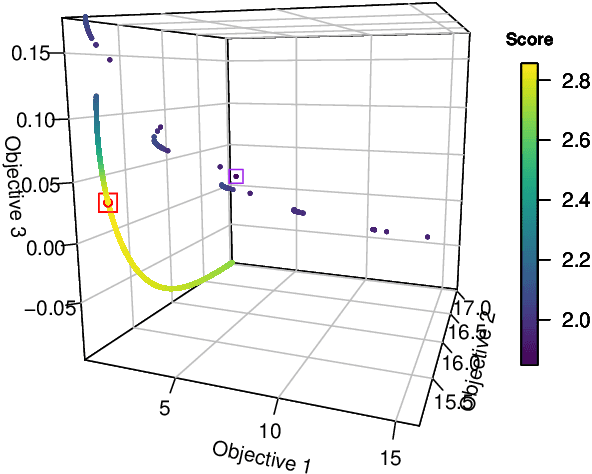
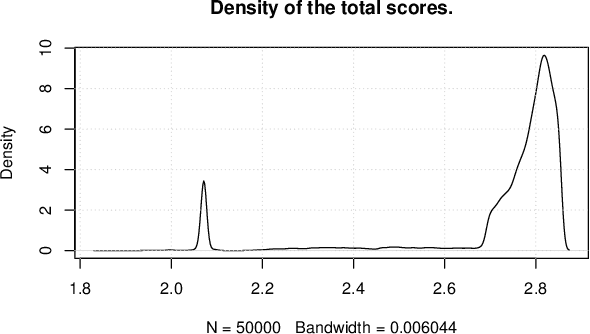
Solutions to multi-objective optimization problems can generally not be compared or ordered, due to the lack of orderability of the single objectives. Furthermore, decision-makers are often made to believe that scaled objectives can be compared. This is a fallacy, as the space of solutions is in practice inhomogeneous without linear trade-offs. We present a method that uses the probability integral transform in order to map the objectives of a problem into scores that all share the same range. In the score space, we can learn which trade-offs are actually possible and develop methods for mapping the desired trade-off back into the preference space. Our results demonstrate that Pareto efficient solutions can be ordered using a low- or no-preference aggregation of the single objectives. When using scores instead of raw objectives during optimization, the process allows for obtaining trade-offs significantly closer to the expressed preference. Using a non-linear mapping for transforming a desired solution in the score space to the required preference for optimization improves this even more drastically.
Aggregation as Unsupervised Learning and its Evaluation
Oct 28, 2021
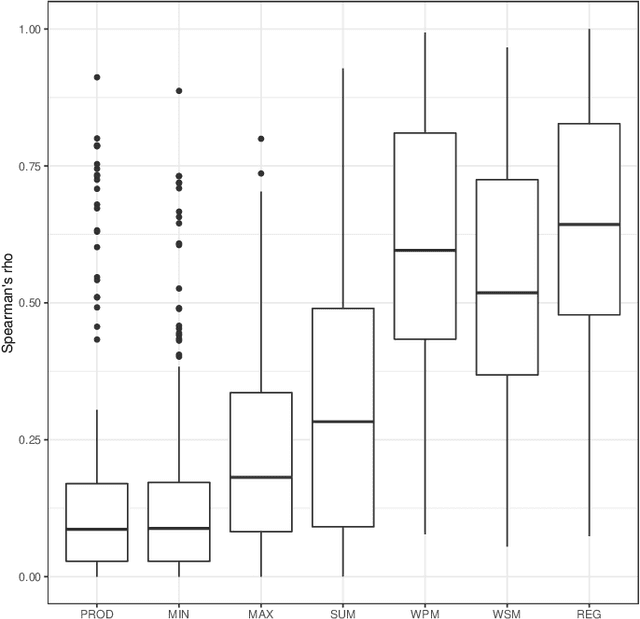
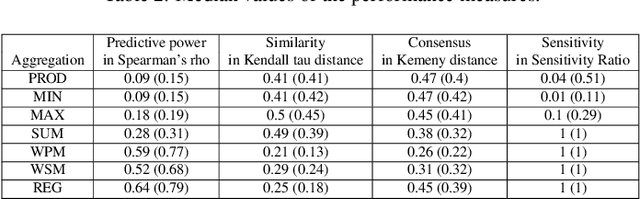
Regression uses supervised machine learning to find a model that combines several independent variables to predict a dependent variable based on ground truth (labeled) data, i.e., tuples of independent and dependent variables (labels). Similarly, aggregation also combines several independent variables to a dependent variable. The dependent variable should preserve properties of the independent variables, e.g., the ranking or relative distance of the independent variable tuples, and/or represent a latent ground truth that is a function of these independent variables. However, ground truth data is not available for finding the aggregation model. Consequently, aggregation models are data agnostic or can only be derived with unsupervised machine learning approaches. We introduce a novel unsupervised aggregation approach based on intrinsic properties of unlabeled training data, such as the cumulative probability distributions of the single independent variables and their mutual dependencies. We present an empirical evaluation framework that allows assessing the proposed approach against other aggregation approaches from two perspectives: (i) how well the aggregation output represents properties of the input tuples, and (ii) how well can aggregated output predict a latent ground truth. To this end, we use data sets for assessing supervised regression approaches that contain explicit ground truth labels. However, the ground truth is not used for deriving the aggregation models, but it allows for the assessment from a perspective (ii). More specifically, we use regression data sets from the UCI machine learning repository and benchmark several data-agnostic and unsupervised approaches for aggregation against ours. The benchmark results indicate that our approach outperforms the other data-agnostic and unsupervised aggregation approaches. It is almost on par with linear regression.
Using Source Code Density to Improve the Accuracy of Automatic Commit Classification into Maintenance Activities
May 28, 2020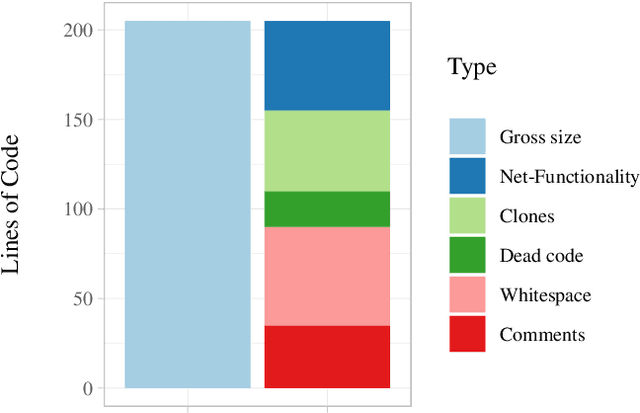

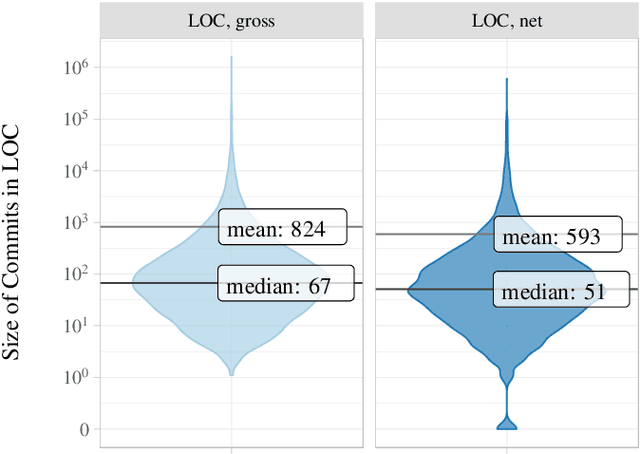
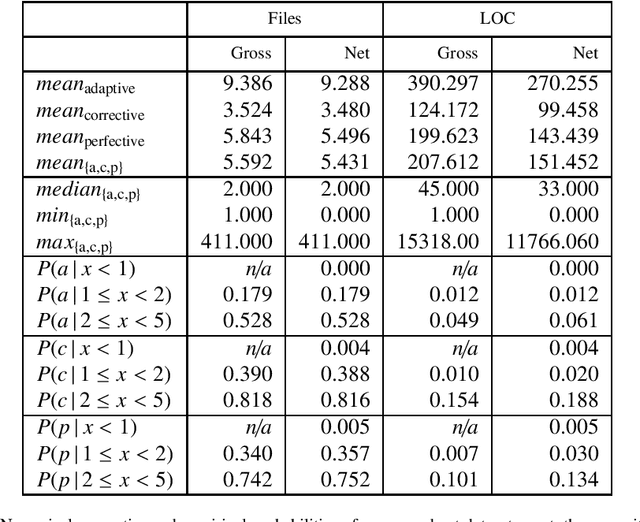
Source code is changed for a reason, e.g., to adapt, correct, or adapt it. This reason can provide valuable insight into the development process but is rarely explicitly documented when the change is committed to a source code repository. Automatic commit classification uses features extracted from commits to estimate this reason. We introduce source code density, a measure of the net size of a commit, and show how it improves the accuracy of automatic commit classification compared to previous size-based classifications. We also investigate how preceding generations of commits affect the class of a commit, and whether taking the code density of previous commits into account can improve the accuracy further. We achieve up to 89% accuracy and a Kappa of 0.82 for the cross-project commit classification where the model is trained on one project and applied to other projects. Models trained on single projects yield accuracies of up to 93% with a Kappa approaching 0.90. The accuracy of the automatic commit classification has a direct impact on software (process) quality analyses that exploit the classification, so our improvements to the accuracy will also improve the confidence in such analyses.