 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Evolutionary Changes for Software Process Quality
Jun 15, 2023Real-world software applications must constantly evolve to remain relevant. This evolution occurs when developing new applications or adapting existing ones to meet new requirements, make corrections, or incorporate future functionality. Traditional methods of software quality control involve software quality models and continuous code inspection tools. These measures focus on directly assessing the quality of the software. However, there is a strong correlation and causation between the quality of the development process and the resulting software product. Therefore, improving the development process indirectly improves the software product, too. To achieve this, effective learning from past processes is necessary, often embraced through post mortem organizational learning. While qualitative evaluation of large artifacts is common, smaller quantitative changes captured by application lifecycle management are often overlooked. In addition to software metrics, these smaller changes can reveal complex phenomena related to project culture and management. Leveraging these changes can help detect and address such complex issues. Software evolution was previously measured by the size of changes, but the lack of consensus on a reliable and versatile quantification method prevents its use as a dependable metric. Different size classifications fail to reliably describe the nature of evolution. While application lifecycle management data is rich, identifying which artifacts can model detrimental managerial practices remains uncertain. Approaches such as simulation modeling, discrete events simulation, or Bayesian networks have only limited ability to exploit continuous-time process models of such phenomena. Even worse, the accessibility and mechanistic insight into such gray- or black-box models are typically very low. To address these challenges, we suggest leveraging objectively [...]
An Approach to Ordering Objectives and Pareto Efficient Solutions
May 30, 2022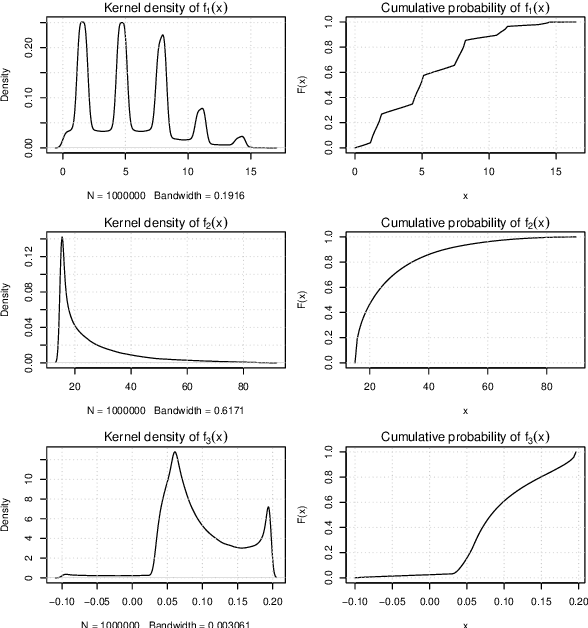
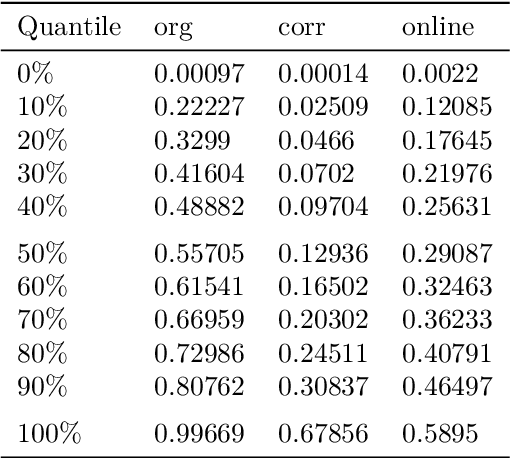
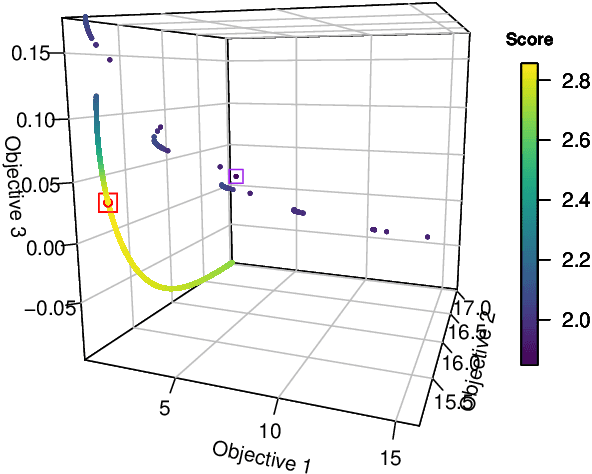
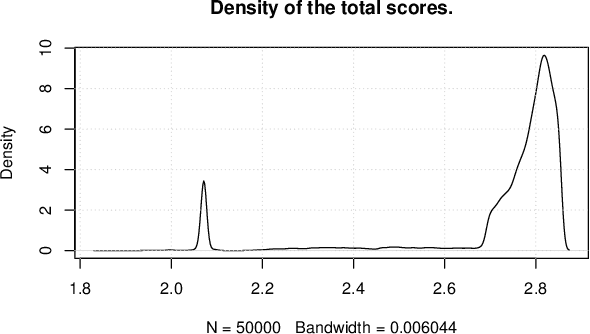
Solutions to multi-objective optimization problems can generally not be compared or ordered, due to the lack of orderability of the single objectives. Furthermore, decision-makers are often made to believe that scaled objectives can be compared. This is a fallacy, as the space of solutions is in practice inhomogeneous without linear trade-offs. We present a method that uses the probability integral transform in order to map the objectives of a problem into scores that all share the same range. In the score space, we can learn which trade-offs are actually possible and develop methods for mapping the desired trade-off back into the preference space. Our results demonstrate that Pareto efficient solutions can be ordered using a low- or no-preference aggregation of the single objectives. When using scores instead of raw objectives during optimization, the process allows for obtaining trade-offs significantly closer to the expressed preference. Using a non-linear mapping for transforming a desired solution in the score space to the required preference for optimization improves this even more drastically.
Technical Reports Compilation: Detecting the Fire Drill anti-pattern using Source Code
May 03, 2021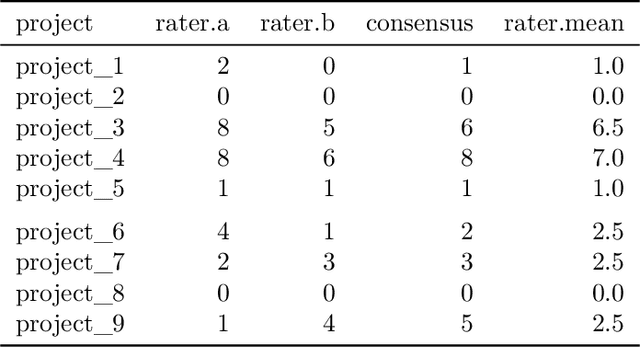
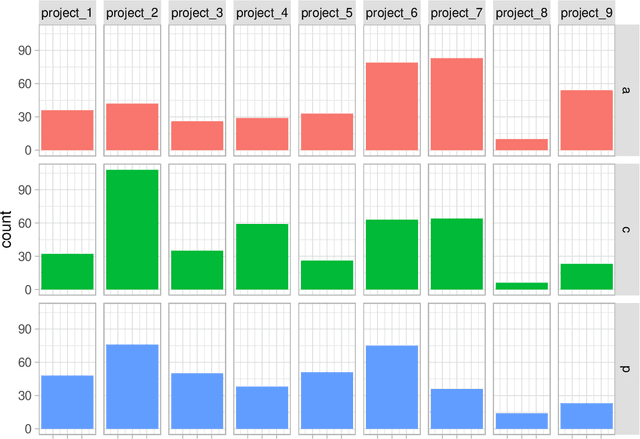
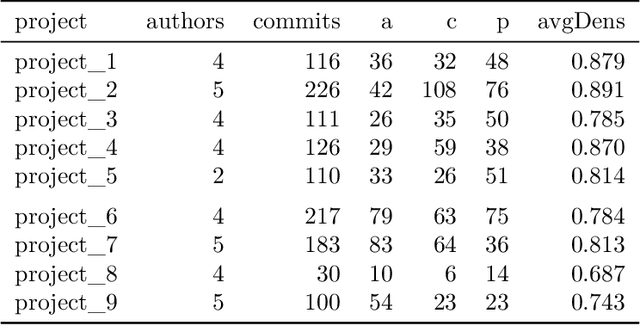
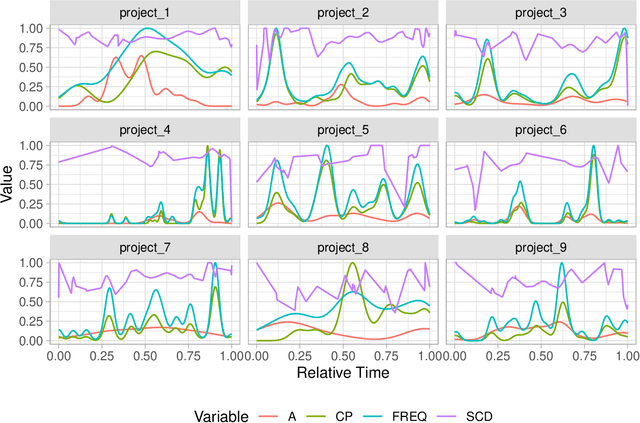
Detecting the presence of project management anti-patterns (AP) currently requires experts on the matter and is an expensive endeavor. Worse, experts may introduce their individual subjectivity or bias. Using the Fire Drill AP, we first introduce a novel way to translate descriptions into detectable AP that are comprised of arbitrary metrics and events such as maintenance activities, which are mined from the underlying source code, thus making the description objective as it becomes data-based. Secondly, we demonstrate a novel method to quantify and score the deviations of real-world projects to data-based AP descriptions. Using nine real-world projects that exhibit a Fire Drill to some degree, we show how to further enhance the translated AP. The ground truth in these projects was extracted from two individual experts and consensus was found between them. Our evaluation spans three kinds of pattern, where the first is purely derived from description, the second type is enhanced by data, and the third kind is derived from data only. The Fire Drill AP as translated from description only shows weak potential of confidently detecting the presence of the anti-pattern in a project. Enriching the AP with data from real-world projects significantly improves the detection. Using patterns derived from data only leads to almost perfect correlations of the scores with the ground truth. Some APs share symptoms with the Fire Drill AP, and we conclude that the presence of similar patterns is most certainly detectable. Furthermore, any pattern that can be characteristically modelled using the proposed approach is potentially well detectable.
Using Source Code Density to Improve the Accuracy of Automatic Commit Classification into Maintenance Activities
May 28, 2020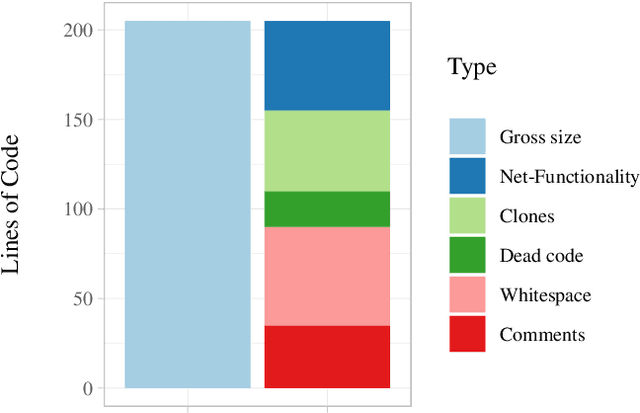

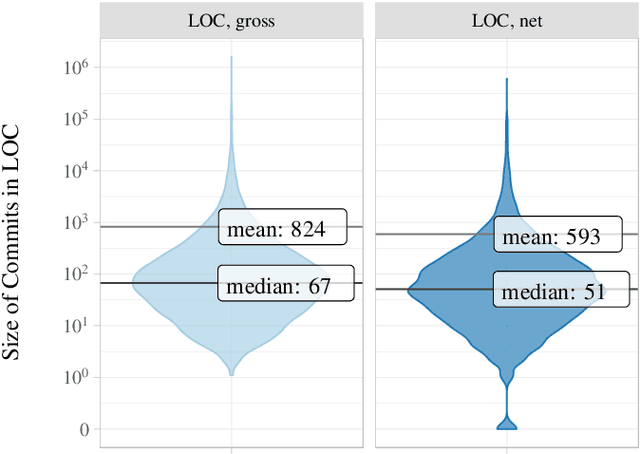
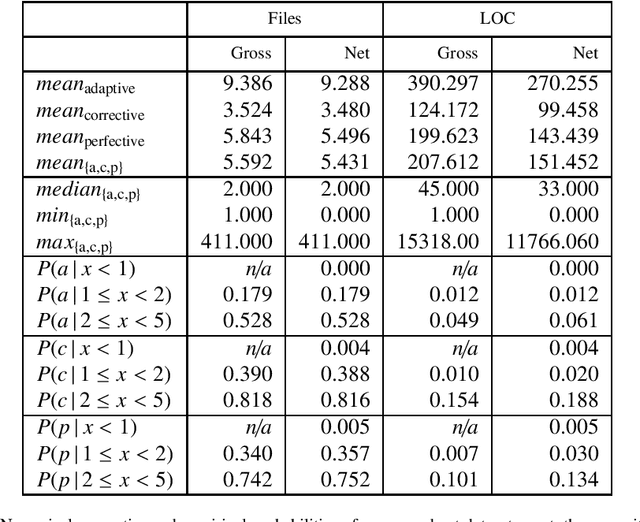
Source code is changed for a reason, e.g., to adapt, correct, or adapt it. This reason can provide valuable insight into the development process but is rarely explicitly documented when the change is committed to a source code repository. Automatic commit classification uses features extracted from commits to estimate this reason. We introduce source code density, a measure of the net size of a commit, and show how it improves the accuracy of automatic commit classification compared to previous size-based classifications. We also investigate how preceding generations of commits affect the class of a commit, and whether taking the code density of previous commits into account can improve the accuracy further. We achieve up to 89% accuracy and a Kappa of 0.82 for the cross-project commit classification where the model is trained on one project and applied to other projects. Models trained on single projects yield accuracies of up to 93% with a Kappa approaching 0.90. The accuracy of the automatic commit classification has a direct impact on software (process) quality analyses that exploit the classification, so our improvements to the accuracy will also improve the confidence in such analyses.