 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Source Code Density to Improve the Accuracy of Automatic Commit Classification into Maintenance Activities
Paper and Code
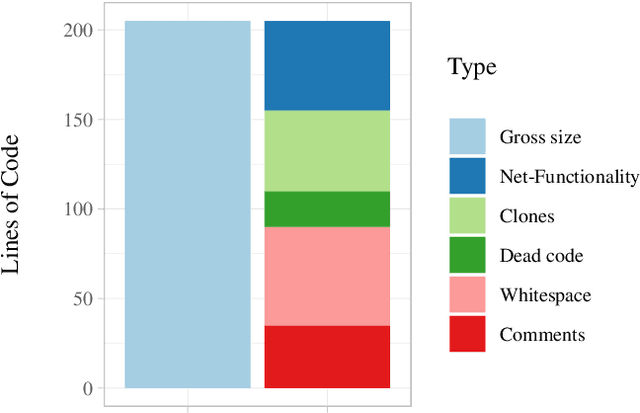

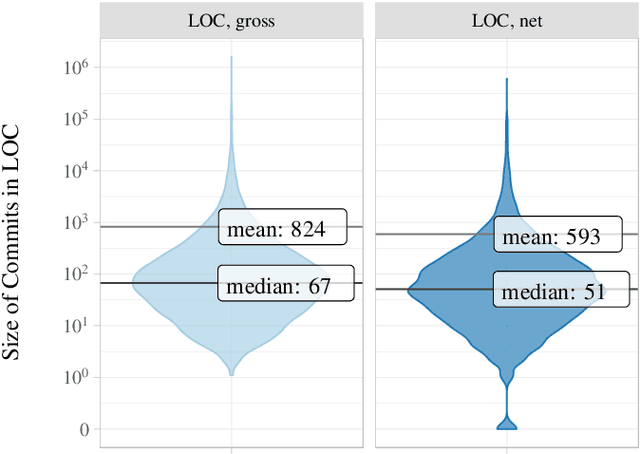
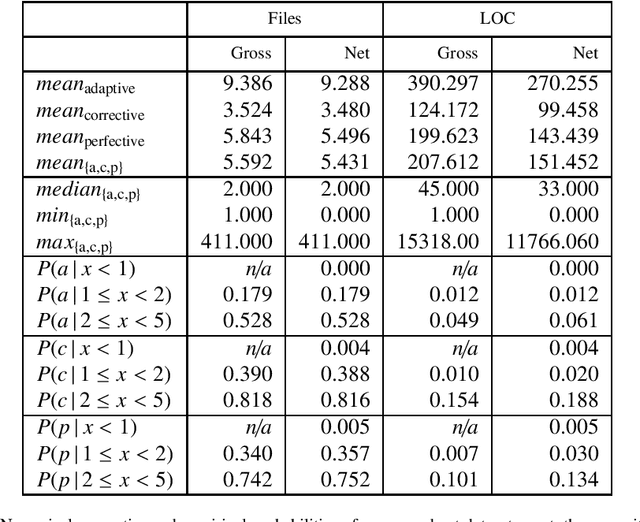
Source code is changed for a reason, e.g., to adapt, correct, or adapt it. This reason can provide valuable insight into the development process but is rarely explicitly documented when the change is committed to a source code repository. Automatic commit classification uses features extracted from commits to estimate this reason. We introduce source code density, a measure of the net size of a commit, and show how it improves the accuracy of automatic commit classification compared to previous size-based classifications. We also investigate how preceding generations of commits affect the class of a commit, and whether taking the code density of previous commits into account can improve the accuracy further. We achieve up to 89% accuracy and a Kappa of 0.82 for the cross-project commit classification where the model is trained on one project and applied to other projects. Models trained on single projects yield accuracies of up to 93% with a Kappa approaching 0.90. The accuracy of the automatic commit classification has a direct impact on software (process) quality analyses that exploit the classification, so our improvements to the accuracy will also improve the confidence in such analyses.