 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation as Unsupervised Learning and its Evaluation
Oct 28, 2021
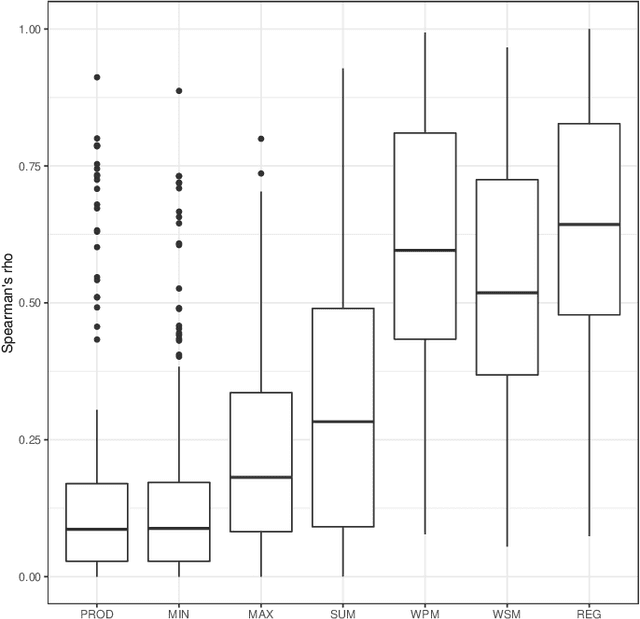
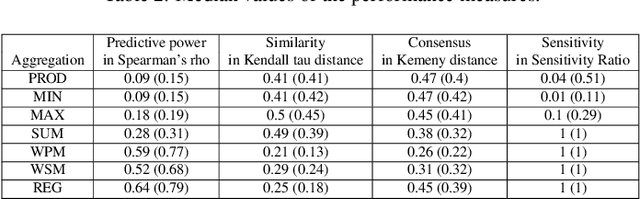
Regression uses supervised machine learning to find a model that combines several independent variables to predict a dependent variable based on ground truth (labeled) data, i.e., tuples of independent and dependent variables (labels). Similarly, aggregation also combines several independent variables to a dependent variable. The dependent variable should preserve properties of the independent variables, e.g., the ranking or relative distance of the independent variable tuples, and/or represent a latent ground truth that is a function of these independent variables. However, ground truth data is not available for finding the aggregation model. Consequently, aggregation models are data agnostic or can only be derived with unsupervised machine learning approaches. We introduce a novel unsupervised aggregation approach based on intrinsic properties of unlabeled training data, such as the cumulative probability distributions of the single independent variables and their mutual dependencies. We present an empirical evaluation framework that allows assessing the proposed approach against other aggregation approaches from two perspectives: (i) how well the aggregation output represents properties of the input tuples, and (ii) how well can aggregated output predict a latent ground truth. To this end, we use data sets for assessing supervised regression approaches that contain explicit ground truth labels. However, the ground truth is not used for deriving the aggregation models, but it allows for the assessment from a perspective (ii). More specifically, we use regression data sets from the UCI machine learning repository and benchmark several data-agnostic and unsupervised approaches for aggregation against ours. The benchmark results indicate that our approach outperforms the other data-agnostic and unsupervised aggregation approaches. It is almost on par with linear regression.
Using Source Code Density to Improve the Accuracy of Automatic Commit Classification into Maintenance Activities
May 28, 2020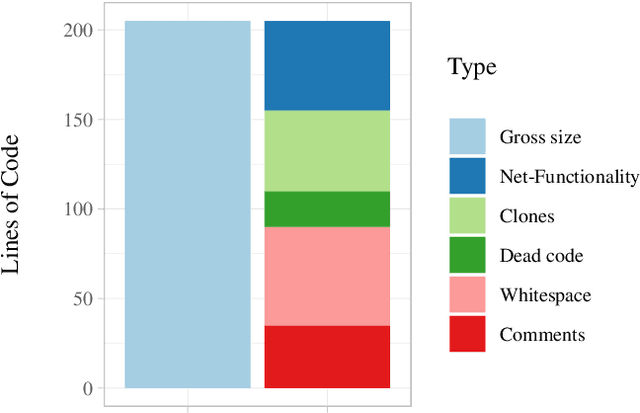

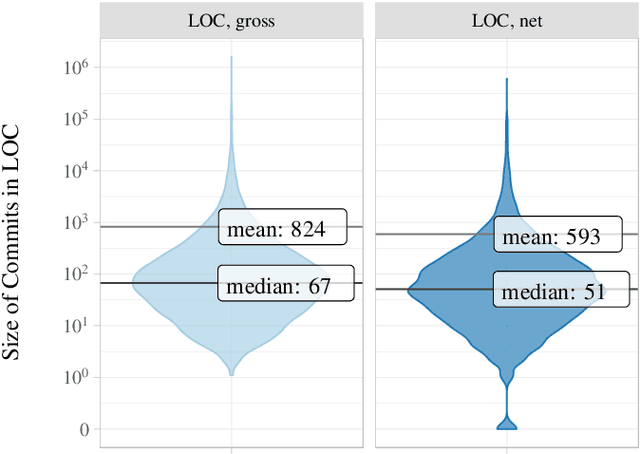
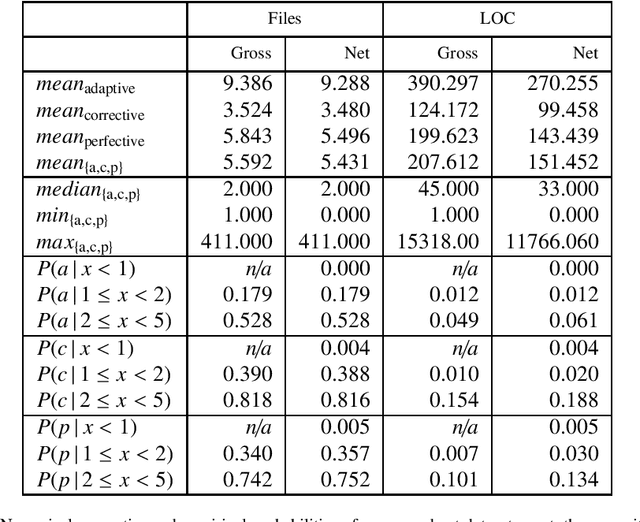
Source code is changed for a reason, e.g., to adapt, correct, or adapt it. This reason can provide valuable insight into the development process but is rarely explicitly documented when the change is committed to a source code repository. Automatic commit classification uses features extracted from commits to estimate this reason. We introduce source code density, a measure of the net size of a commit, and show how it improves the accuracy of automatic commit classification compared to previous size-based classifications. We also investigate how preceding generations of commits affect the class of a commit, and whether taking the code density of previous commits into account can improve the accuracy further. We achieve up to 89% accuracy and a Kappa of 0.82 for the cross-project commit classification where the model is trained on one project and applied to other projects. Models trained on single projects yield accuracies of up to 93% with a Kappa approaching 0.90. The accuracy of the automatic commit classification has a direct impact on software (process) quality analyses that exploit the classification, so our improvements to the accuracy will also improve the confidence in such analyses.