 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Generative Models Ensemble for Knowledge-Driven Proactive Human-Computer Dialogue Agent
Jul 08, 2019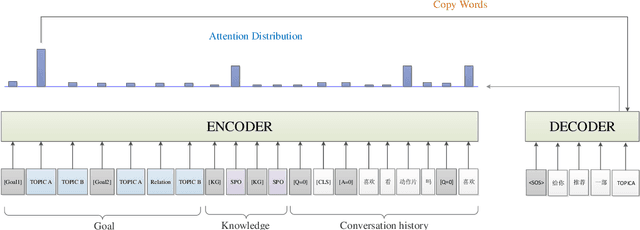


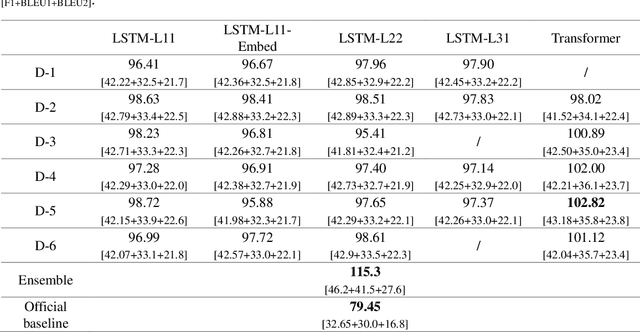
Multiple sequence to sequence models were used to establish an end-to-end multi-turns proactive dialogue generation agent, with the aid of data augmentation techniques and variant encoder-decoder structure designs. A rank-based ensemble approach was developed for boosting performance. Results indicate that our single model, in average, makes an obvious improvement in the terms of F1-score and BLEU over the baseline by 18.67% on the DuConv dataset. In particular, the ensemble methods further significantly outperform the baseline by 35.85%.
Sample-Efficient Deep RL with Generative Adversarial Tree Search
Jun 15, 2018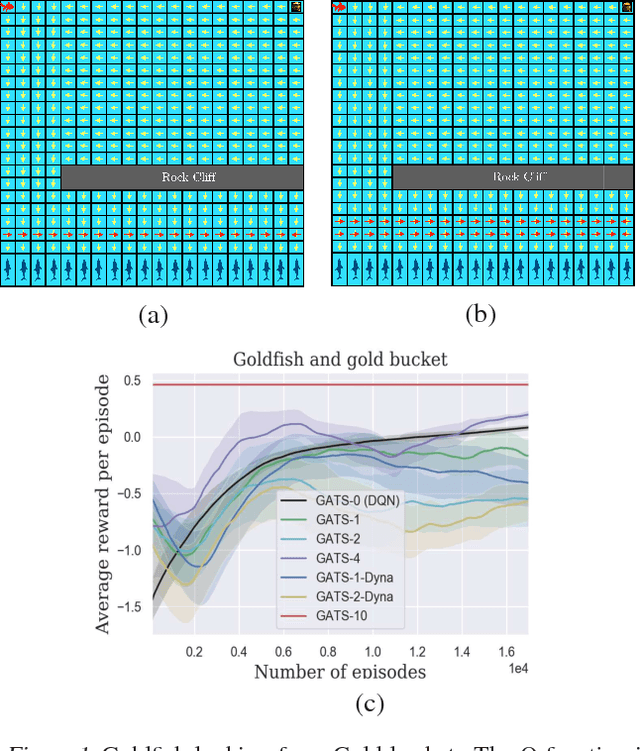



We propose Generative Adversarial Tree Search (GATS), a sample-efficient Deep Reinforcement Learning (DRL) algorithm. While Monte Carlo Tree Search (MCTS) is known to be effective for search and planning in RL, it is often sample-inefficient and therefore expensive to apply in practice. In this work, we develop a Generative Adversarial Network (GAN) architecture to model an environment's dynamics and a predictor model for the reward function. We exploit collected data from interaction with the environment to learn these models, which we then use for model-based planning. During planning, we deploy a finite depth MCTS, using the learned model for tree search and a learned Q-value for the leaves, to find the best action. We theoretically show that GATS improves the bias-variance trade-off in value-based DRL. Moreover, we show that the generative model learns the model dynamics using orders of magnitude fewer samples than the Q-learner. In non-stationary settings where the environment model changes, we find the generative model adapts significantly faster than the Q-learner to the new environment.
Object Localization and Motion Transfer learning with Capsules
May 20, 2018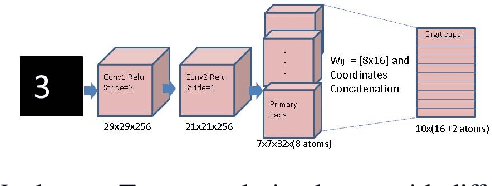
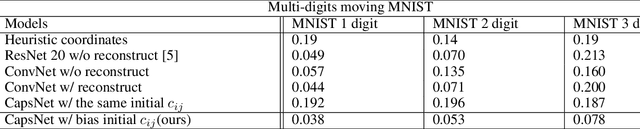
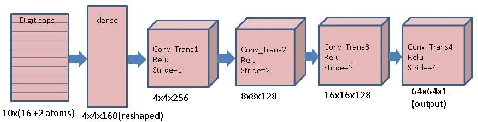

Inspired by CapsNet's routing-by-agreement mechanism, with its ability to learn object properties, and by center-of-mass calculations from physics, we propose a CapsNet architecture with object coordinate atoms and an LSTM network for evaluation. The first is based on CapsNet but uses a new routing algorithm to find the objects' approximate positions in the image coordinate system, and the second is a parameterized affine transformation network that can predict future positions from past positions by learning the translation transformation from 2D object coordinates generated from the first network. We demonstrate the learned translation transformation is transferable to another dataset without the need to train the transformation network again. Only the CapsNet needs training on the new dataset. As a result, our work shows that object recognition and motion prediction can be separated, and that motion prediction can be transferred to another dataset with different object types.