 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything old is new again: A multi-view learning approach to learning using privileged information and distillation
Mar 08, 2019We adopt a multi-view approach for analyzing two knowledge transfer settings---learning using privileged information (LUPI) and distillation---in a common framework. Under reasonable assumptions about the complexities of hypothesis spaces, and being optimistic about the expected loss achievable by the student (in distillation) and a transformed teacher predictor (in LUPI), we show that encouraging agreement between the teacher and the student leads to reduced search space. As a result, improved convergence rate can be obtained with regularized empirical risk minimization.
Acoustic feature learning using cross-domain articulatory measurements
Mar 20, 2018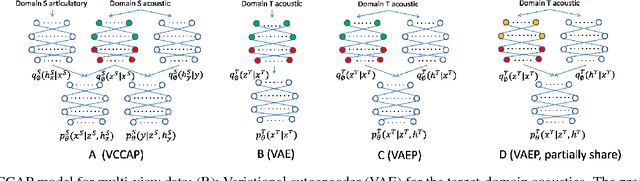

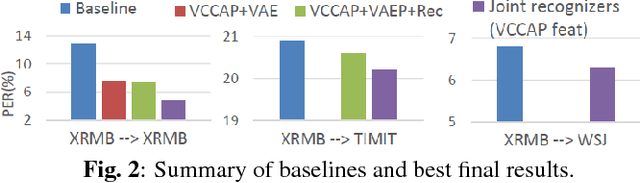
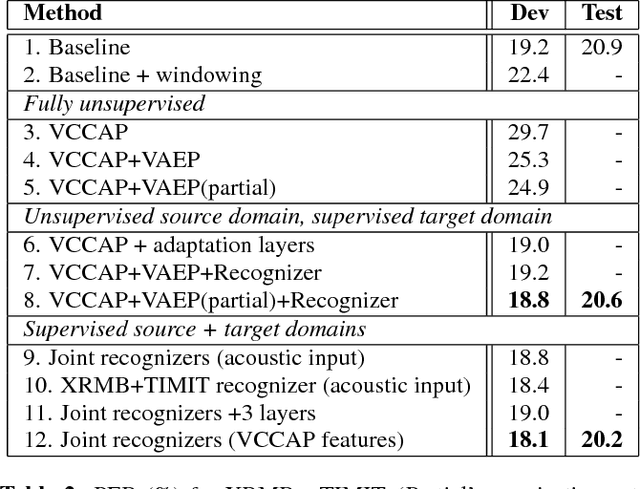
Previous work has shown that it is possible to improve speech recognition by learning acoustic features from paired acoustic-articulatory data, for example by using canonical correlation analysis (CCA) or its deep extensions. One limitation of this prior work is that the learned feature models are difficult to port to new datasets or domains, and articulatory data is not available for most speech corpora. In this work we study the problem of acoustic feature learning in the setting where we have access to an external, domain-mismatched dataset of paired speech and articulatory measurements, either with or without labels. We develop methods for acoustic feature learning in these settings, based on deep variational CCA and extensions that use both source and target domain data and labels. Using this approach, we improve phonetic recognition accuracies on both TIMIT and Wall Street Journal and analyze a number of design choices.
Distributed Stochastic Multi-Task Learning with Graph Regularization
Feb 11, 2018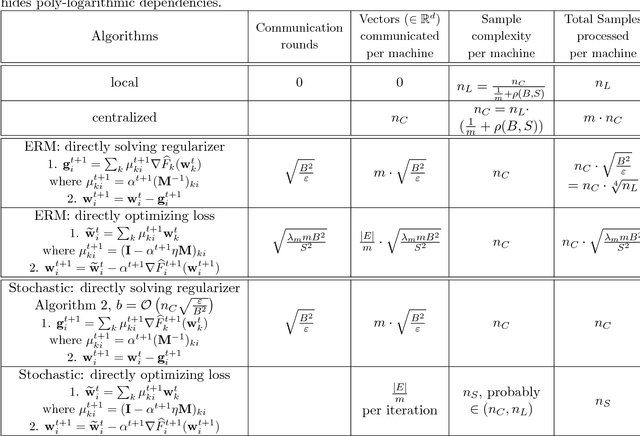
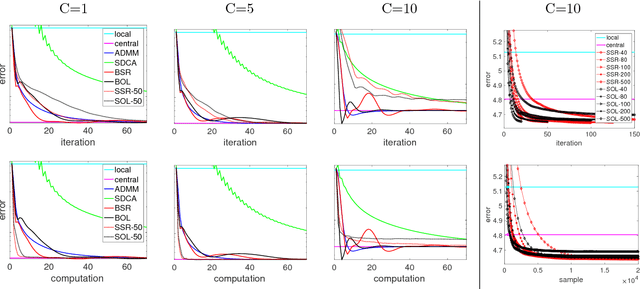
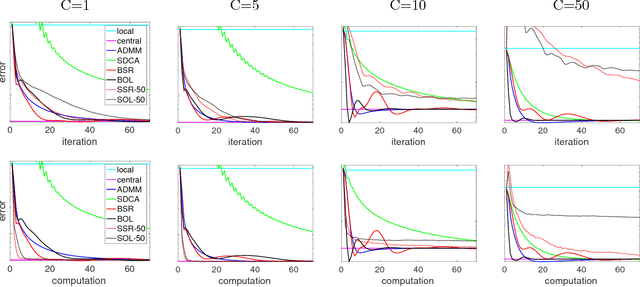
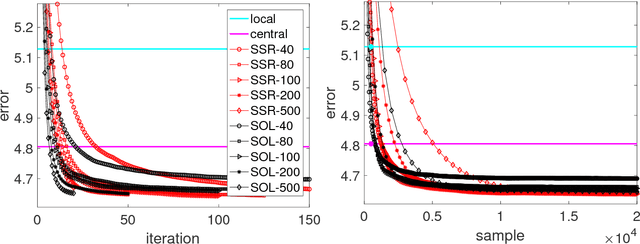
We propose methods for distributed graph-based multi-task learning that are based on weighted averaging of messages from other machines. Uniform averaging or diminishing stepsize in these methods would yield consensus (single task) learning. We show how simply skewing the averaging weights or controlling the stepsize allows learning different, but related, tasks on the different machines.
Stochastic Nonconvex Optimization with Large Minibatches
Nov 12, 2017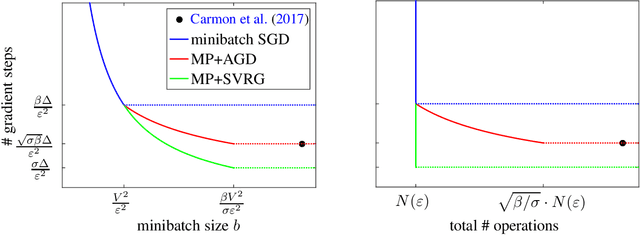
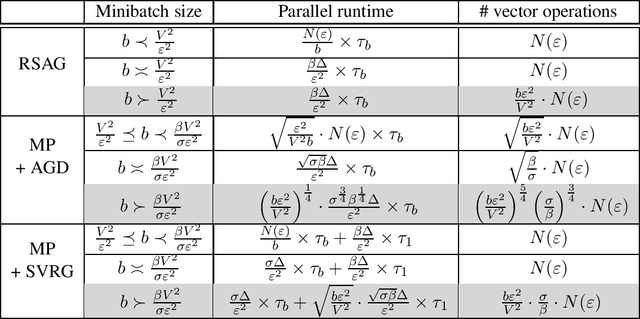
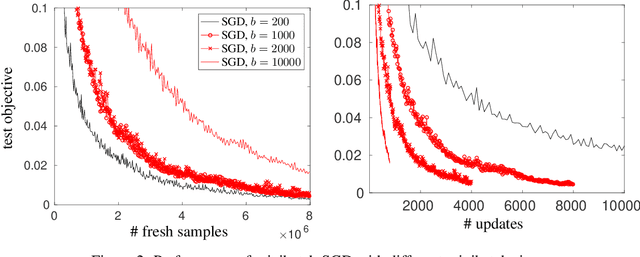
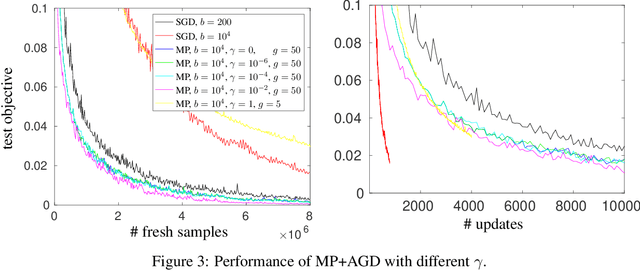
We study stochastic optimization of nonconvex loss functions, which are typical objectives for training neural networks. We propose stochastic approximation algorithms which optimize a series of regularized, nonlinearized losses on large minibatches of samples, using only first-order gradient information. Our algorithms provably converge to an approximate critical point of the expected objective with faster rates than minibatch stochastic gradient descent, and facilitate better parallelization by allowing larger minibatches.
Acoustic Feature Learning via Deep Variational Canonical Correlation Analysis
Aug 31, 2017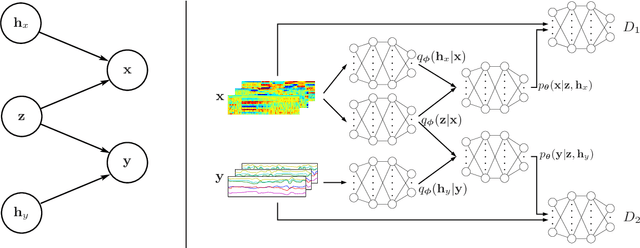

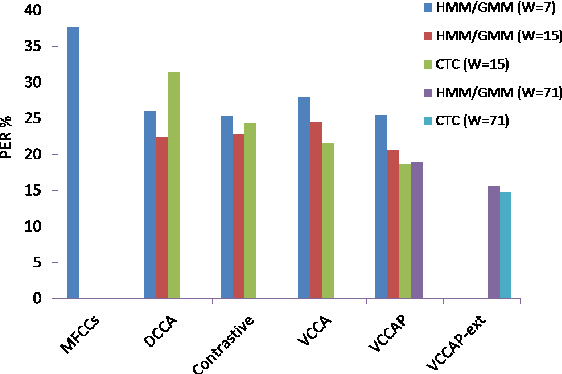
We study the problem of acoustic feature learning in the setting where we have access to another (non-acoustic) modality for feature learning but not at test time. We use deep variational canonical correlation analysis (VCCA), a recently proposed deep generative method for multi-view representation learning. We also extend VCCA with improved latent variable priors and with adversarial learning. Compared to other techniques for multi-view feature learning, VCCA's advantages include an intuitive latent variable interpretation and a variational lower bound objective that can be trained end-to-end efficiently. We compare VCCA and its extensions with previous feature learning methods on the University of Wisconsin X-ray Microbeam Database, and show that VCCA-based feature learning improves over previous methods for speaker-independent phonetic recognition.
Memory and Communication Efficient Distributed Stochastic Optimization with Minibatch-Prox
Jun 09, 2017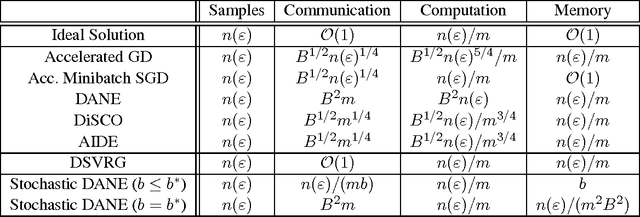
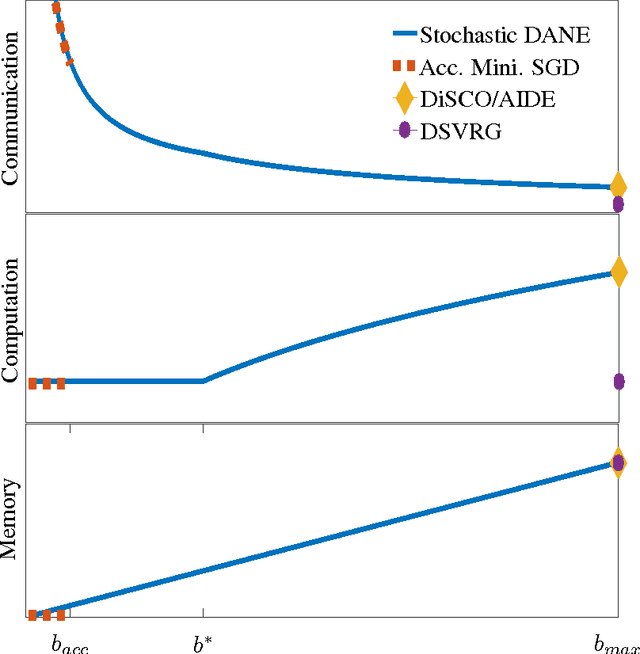

We present and analyze an approach for distributed stochastic optimization which is statistically optimal and achieves near-linear speedups (up to logarithmic factors). Our approach allows a communication-memory tradeoff, with either logarithmic communication but linear memory, or polynomial communication and a corresponding polynomial reduction in required memory. This communication-memory tradeoff is achieved through minibatch-prox iterations (minibatch passive-aggressive updates), where a subproblem on a minibatch is solved at each iteration. We provide a novel analysis for such a minibatch-prox procedure which achieves the statistical optimal rate regardless of minibatch size and smoothness, thus significantly improving on prior work.
Multi-view Recurrent Neural Acoustic Word Embeddings
Mar 10, 2017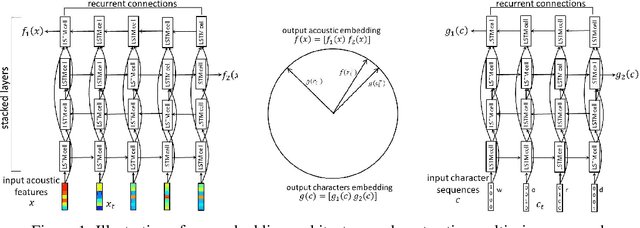


Recent work has begun exploring neural acoustic word embeddings---fixed-dimensional vector representations of arbitrary-length speech segments corresponding to words. Such embeddings are applicable to speech retrieval and recognition tasks, where reasoning about whole words may make it possible to avoid ambiguous sub-word representations. The main idea is to map acoustic sequences to fixed-dimensional vectors such that examples of the same word are mapped to similar vectors, while different-word examples are mapped to very different vectors. In this work we take a multi-view approach to learning acoustic word embeddings, in which we jointly learn to embed acoustic sequences and their corresponding character sequences. We use deep bidirectional LSTM embedding models and multi-view contrastive losses. We study the effect of different loss variants, including fixed-margin and cost-sensitive losses. Our acoustic word embeddings improve over previous approaches for the task of word discrimination. We also present results on other tasks that are enabled by the multi-view approach, including cross-view word discrimination and word similarity.
Efficient coordinate-wise leading eigenvector computation
Feb 25, 2017
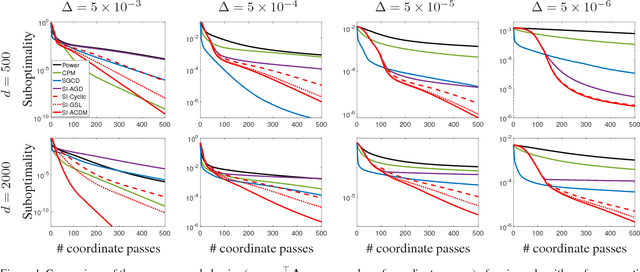

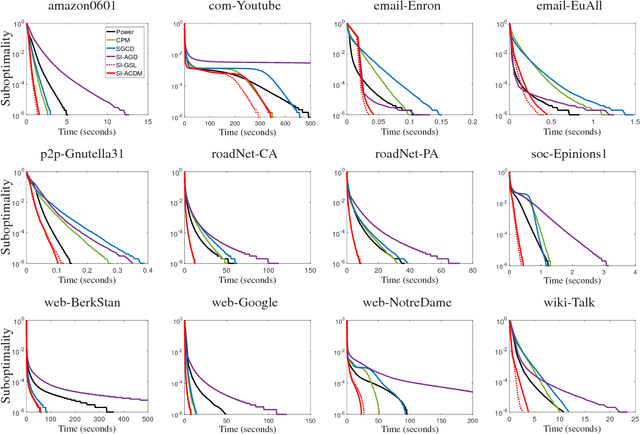
We develop and analyze efficient "coordinate-wise" methods for finding the leading eigenvector, where each step involves only a vector-vector product. We establish global convergence with overall runtime guarantees that are at least as good as Lanczos's method and dominate it for slowly decaying spectrum. Our methods are based on combining a shift-and-invert approach with coordinate-wise algorithms for linear regression.
Deep Variational Canonical Correlation Analysis
Feb 25, 2017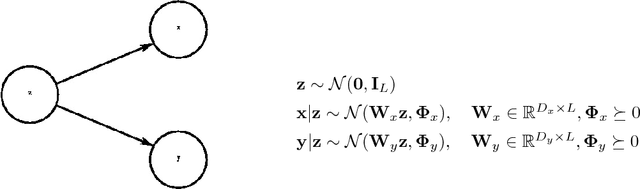

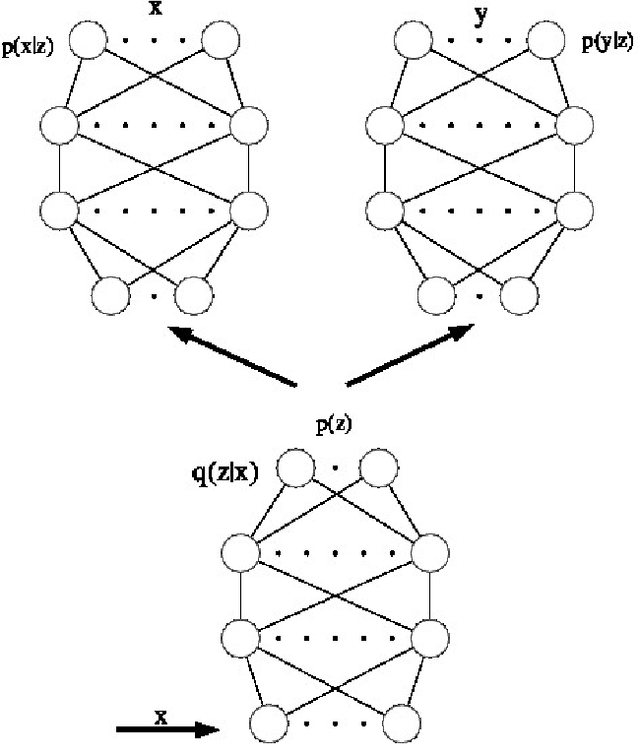
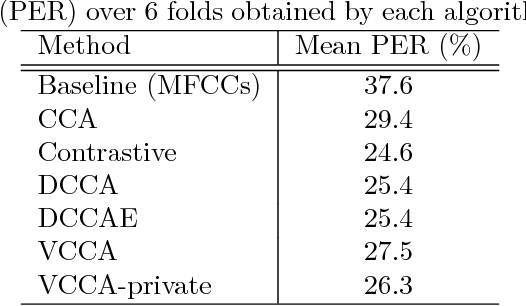
We present deep variational canonical correlation analysis (VCCA), a deep multi-view learning model that extends the latent variable model interpretation of linear CCA to nonlinear observation models parameterized by deep neural networks. We derive variational lower bounds of the data likelihood by parameterizing the posterior probability of the latent variables from the view that is available at test time. We also propose a variant of VCCA called VCCA-private that can, in addition to the "common variables" underlying both views, extract the "private variables" within each view, and disentangles the shared and private information for multi-view data without hard supervision. Experimental results on real-world datasets show that our methods are competitive across domains.
Stochastic Canonical Correlation Analysis
Feb 21, 2017We tightly analyze the sample complexity of CCA, provide a learning algorithm that achieves optimal statistical performance in time linear in the required number of samples (up to log factors), as well as a streaming algorithm with similar guarantees.