 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtifact Disentanglement Network for Unsupervised Metal Artifact Reduction
Jun 29, 2019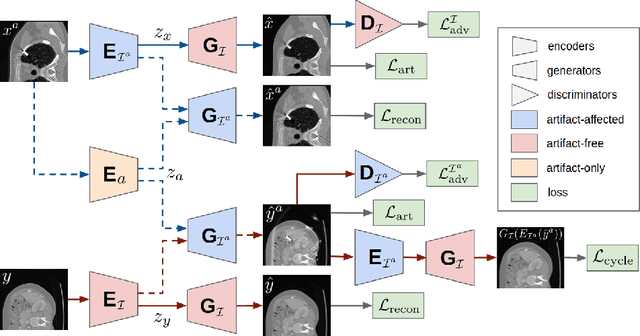
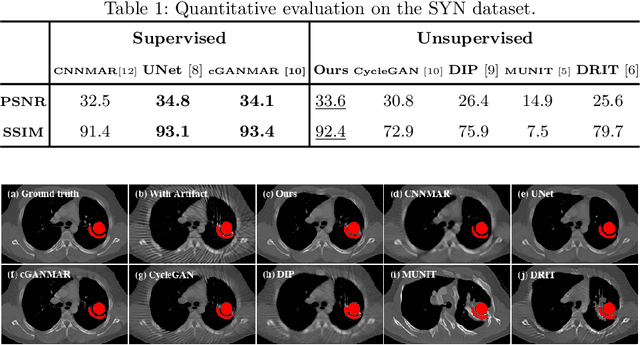
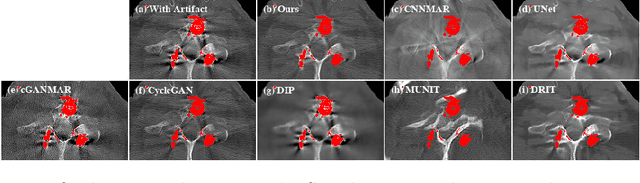
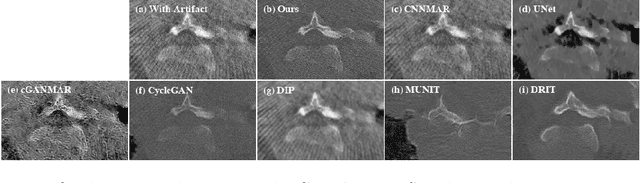
Current deep neural network based approaches to computed tomography (CT) metal artifact reduction (MAR) are supervised methods which rely heavily on synthesized data for training. However, as synthesized data may not perfectly simulate the underlying physical mechanisms of CT imaging, the supervised methods often generalize poorly to clinical applications. To address this problem, we propose, to the best of our knowledge, the first unsupervised learning approach to MAR. Specifically, we introduce a novel artifact disentanglement network that enables different forms of generations and regularizations between the artifact-affected and artifact-free image domains to support unsupervised learning. Extensive experiments show that our method significantly outperforms the existing unsupervised models for image-to-image translation problems, and achieves comparable performance to existing supervised models on a synthesized dataset. When applied to clinical datasets, our method achieves considerable improvements over the supervised models. The source code of this paper is publicly available at https://github.com/liaohaofu/adn.
DuDoNet: Dual Domain Network for CT Metal Artifact Reduction
Jun 29, 2019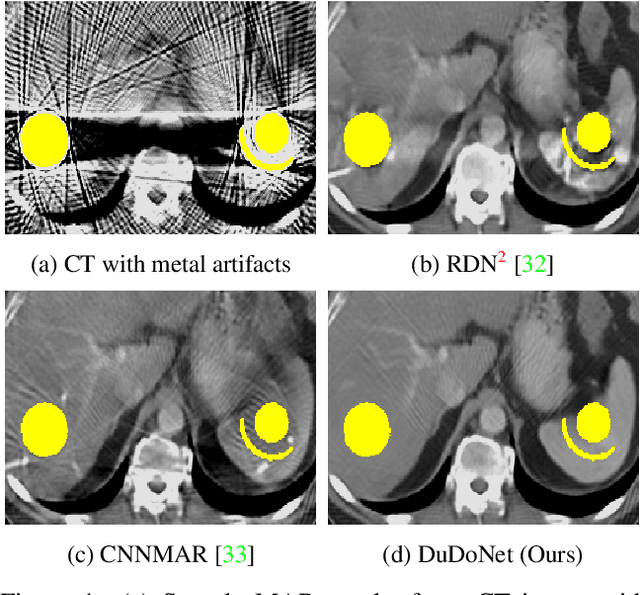
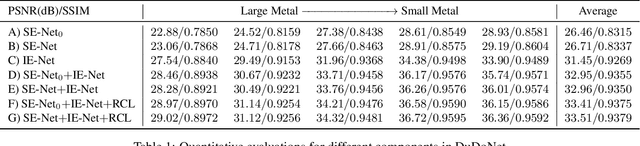
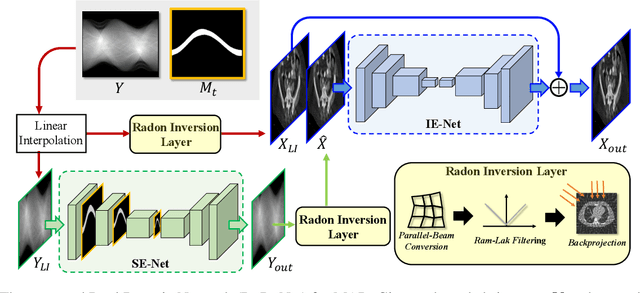
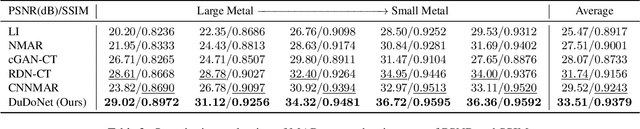
Computed tomography (CT) is an imaging modality widely used for medical diagnosis and treatment. CT images are often corrupted by undesirable artifacts when metallic implants are carried by patients, which creates the problem of metal artifact reduction (MAR). Existing methods for reducing the artifacts due to metallic implants are inadequate for two main reasons. First, metal artifacts are structured and non-local so that simple image domain enhancement approaches would not suffice. Second, the MAR approaches which attempt to reduce metal artifacts in the X-ray projection (sinogram) domain inevitably lead to severe secondary artifact due to sinogram inconsistency. To overcome these difficulties, we propose an end-to-end trainable Dual Domain Network (DuDoNet) to simultaneously restore sinogram consistency and enhance CT images. The linkage between the sigogram and image domains is a novel Radon inversion layer that allows the gradients to back-propagate from the image domain to the sinogram domain during training. Extensive experiments show that our method achieves significant improvements over other single domain MAR approaches. To the best of our knowledge, it is the first end-to-end dual-domain network for MAR.
Multiview 2D/3D Rigid Registration via a Point-Of-Interest Network for Tracking and Triangulation
Apr 08, 2019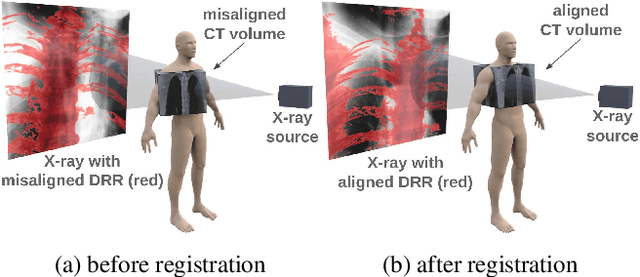

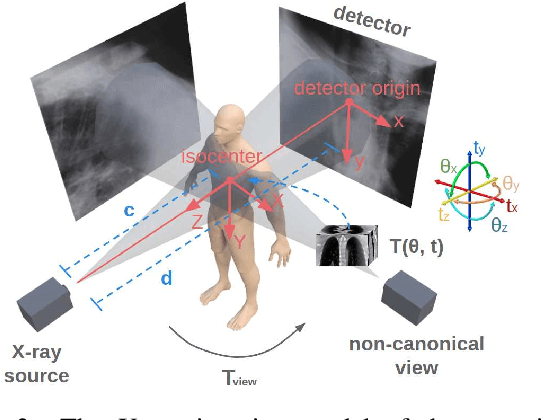
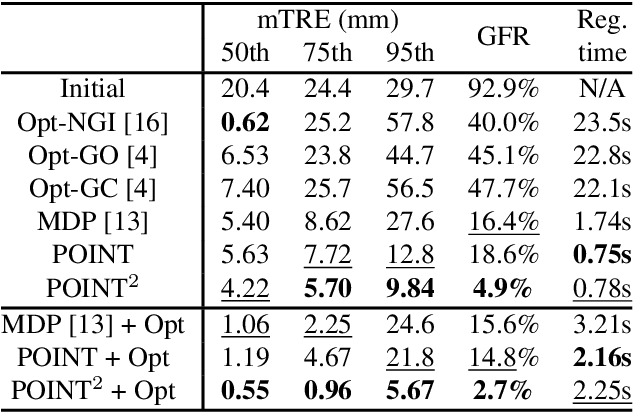
We propose to tackle the problem of multiview 2D/3D rigid registration for intervention via a Point-Of-Interest Network for Tracking and Triangulation (POINT^2). POINT^2 learns to establish 2D point-to-point correspondences between the pre- and intra-intervention images by tracking a set of random POIs. The 3D pose of the pre-intervention volume is then estimated through a triangulation layer. In POINT^2, the unified framework of the POI tracker and the triangulation layer enables learning informative 2D features and estimating 3D pose jointly. In contrast to existing approaches, POINT^2 only requires a single forward-pass to achieve a reliable 2D/3D registration. As the POI tracker is shift-invariant, POINT^2 is more robust to the initial pose of the 3D pre-intervention image. Extensive experiments on a large-scale clinical cone-beam CT (CBCT) dataset show that the proposed POINT^2 method outperforms the existing learning-based method in terms of accuracy, robustness and running time. Furthermore, when used as an initial pose estimator, our method also improves the robustness and speed of the state-of-the-art optimization-based approaches by ten folds.
A Proximity-Aware Hierarchical Clustering of Faces
Mar 14, 2017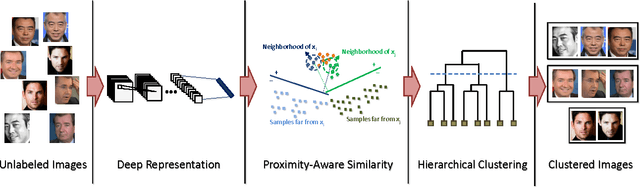
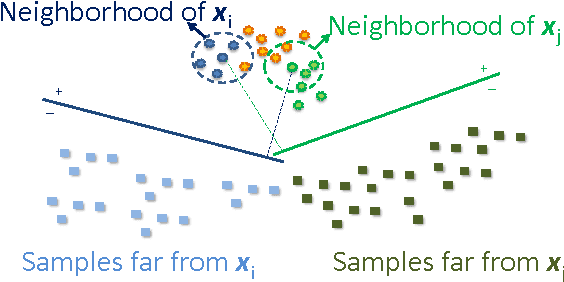


In this paper, we propose an unsupervised face clustering algorithm called "Proximity-Aware Hierarchical Clustering" (PAHC) that exploits the local structure of deep representations. In the proposed method, a similarity measure between deep features is computed by evaluating linear SVM margins. SVMs are trained using nearest neighbors of sample data, and thus do not require any external training data. Clusters are then formed by thresholding the similarity scores. We evaluate the clustering performance using three challenging unconstrained face datasets, including Celebrity in Frontal-Profile (CFP), IARPA JANUS Benchmark A (IJB-A), and JANUS Challenge Set 3 (JANUS CS3) datasets. Experimental results demonstrate that the proposed approach can achieve significant improvements over state-of-the-art methods. Moreover, we also show that the proposed clustering algorithm can be applied to curate a set of large-scale and noisy training dataset while maintaining sufficient amount of images and their variations due to nuisance factors. The face verification performance on JANUS CS3 improves significantly by finetuning a DCNN model with the curated MS-Celeb-1M dataset which contains over three million face images.