 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Bias Formation in Deep Neural Networks Through the Geometric Mechanisms of Human Visual Decoupling
Feb 17, 2025Deep neural networks (DNNs) often exhibit biases toward certain categories during object recognition, even under balanced training data conditions. The intrinsic mechanisms underlying these biases remain unclear. Inspired by the human visual system, which decouples object manifolds through hierarchical processing to achieve object recognition, we propose a geometric analysis framework linking the geometric complexity of class-specific perceptual manifolds in DNNs to model bias. Our findings reveal that differences in geometric complexity can lead to varying recognition capabilities across categories, introducing biases. To support this analysis, we present the Perceptual-Manifold-Geometry library, designed for calculating the geometric properties of perceptual manifolds.
HI-GVF: Shared Control based on Human-Influenced Guiding Vector Fields for Human-multi-robot Cooperation
Feb 17, 2025



Human-multi-robot shared control leverages human decision-making and robotic autonomy to enhance human-robot collaboration. While widely studied, existing systems often adopt a leader-follower model, limiting robot autonomy to some extent. Besides, a human is required to directly participate in the motion control of robots through teleoperation, which significantly burdens the operator. To alleviate these two issues, we propose a layered shared control computing framework using human-influenced guiding vector fields (HI-GVF) for human-robot collaboration. HI-GVF guides the multi-robot system along a desired path specified by the human. Then, an intention field is designed to merge the human and robot intentions, accelerating the propagation of the human intention within the multi-robot system. Moreover, we give the stability analysis of the proposed model and use collision avoidance based on safety barrier certificates to fine-tune the velocity. Eventually, considering the firefighting task as an example scenario, we conduct simulations and experiments using multiple human-robot interfaces (brain-computer interface, myoelectric wristband, eye-tracking), and the results demonstrate that our proposed approach boosts the effectiveness and performance of the task.
A Novel Approach to for Multimodal Emotion Recognition : Multimodal semantic information fusion
Feb 12, 2025With the advancement of artificial intelligence and computer vision technologies, multimodal emotion recognition has become a prominent research topic. However, existing methods face challenges such as heterogeneous data fusion and the effective utilization of modality correlations. This paper proposes a novel multimodal emotion recognition approach, DeepMSI-MER, based on the integration of contrastive learning and visual sequence compression. The proposed method enhances cross-modal feature fusion through contrastive learning and reduces redundancy in the visual modality by leveraging visual sequence compression. Experimental results on two public datasets, IEMOCAP and MELD, demonstrate that DeepMSI-MER significantly improves the accuracy and robustness of emotion recognition, validating the effectiveness of multimodal feature fusion and the proposed approach.
Bayesian Beamforming for Integrated Sensing and Communication Systems
Feb 10, 2025The uncertainty of the sensing target brings great challenge to the beamforming design of the integrated sensing and communication (ISAC) system. To address this issue, we model the scattering coefficient and azimuth angle of the target as random variables and introduce a novel metric, expected detection probability (EPd), to quantify the average detection performance from a Bayesian perspective. Furthermore, we design a Bayesian beamforming scheme to optimize the expected detection probability under the limited power budget and communication performance constraints. A successive convex approximation and semidefinite relaxation-based (SCA-SDR) algorithm is developed for the complicated non-convex optimization problem corresponding to the beamforming scheme. Simulation results show that the proposed scheme outperforms other benchmarks and exhibits robust detection performance when parameters of the target are unknown and random.
Pursuing Better Decision Boundaries for Long-Tailed Object Detection via Category Information Amount
Feb 06, 2025In object detection, the instance count is typically used to define whether a dataset exhibits a long-tail distribution, implicitly assuming that models will underperform on categories with fewer instances. This assumption has led to extensive research on category bias in datasets with imbalanced instance counts. However, models still exhibit category bias even in datasets where instance counts are relatively balanced, clearly indicating that instance count alone cannot explain this phenomenon. In this work, we first introduce the concept and measurement of category information amount. We observe a significant negative correlation between category information amount and accuracy, suggesting that category information amount more accurately reflects the learning difficulty of a category. Based on this observation, we propose Information Amount-Guided Angular Margin (IGAM) Loss. The core idea of IGAM is to dynamically adjust the decision space of each category based on its information amount, thereby reducing category bias in long-tail datasets. IGAM Loss not only performs well on long-tailed benchmark datasets such as LVIS v1.0 and COCO-LT but also shows significant improvement for underrepresented categories in the non-long-tailed dataset Pascal VOC. Comprehensive experiments demonstrate the potential of category information amount as a tool and the generality of our proposed method.
Uncertainty Awareness in Wireless Communications, Sensing, and Learning
Dec 18, 2024Wireless communications and sensing (WCS) establish the backbone of modern information exchange and environment perception. Typical applications range from mobile networks and the Internet of Things to radar and sensor grids. The incorporation of machine learning further expands WCS's boundaries, unlocking automated and high-quality data analytics, together with advisable and efficient decision-making. Despite transformative capabilities, wireless systems often face numerous uncertainties in design and operation, such as modeling errors due to incomplete physical knowledge, statistical errors arising from data scarcity, measurement errors caused by sensor imperfections, computational errors owing to resource limitation, and unpredictability of environmental evolution. Once ignored, these uncertainties can lead to severe outcomes, e.g., performance degradation, system untrustworthiness, inefficient resource utilization, and security vulnerabilities. As such, this article reviews mature and emerging architectural, computational, and operational countermeasures, encompassing uncertainty-aware designs of signals and systems (e.g., diversity, adaptivity, modularity), as well as uncertainty-aware modeling and computational frameworks (e.g., risk-informed optimization, robust signal processing, and trustworthy machine learning). Trade-offs to employ these methods, e.g., robustness vs optimality, are also highlighted.
Unsupervised Anomaly Detection for Tabular Data Using Noise Evaluation
Dec 16, 2024Unsupervised anomaly detection (UAD) plays an important role in modern data analytics and it is crucial to provide simple yet effective and guaranteed UAD algorithms for real applications. In this paper, we present a novel UAD method for tabular data by evaluating how much noise is in the data. Specifically, we propose to learn a deep neural network from the clean (normal) training dataset and a noisy dataset, where the latter is generated by adding highly diverse noises to the clean data. The neural network can learn a reliable decision boundary between normal data and anomalous data when the diversity of the generated noisy data is sufficiently high so that the hard abnormal samples lie in the noisy region. Importantly, we provide theoretical guarantees, proving that the proposed method can detect anomalous data successfully, although the method does not utilize any real anomalous data in the training stage. Extensive experiments through more than 60 benchmark datasets demonstrate the effectiveness of the proposed method in comparison to 12 baselines of UAD. Our method obtains a 92.27\% AUC score and a 1.68 ranking score on average. Moreover, compared to the state-of-the-art UAD methods, our method is easier to implement.
MPPO: Multi Pair-wise Preference Optimization for LLMs with Arbitrary Negative Samples
Dec 13, 2024

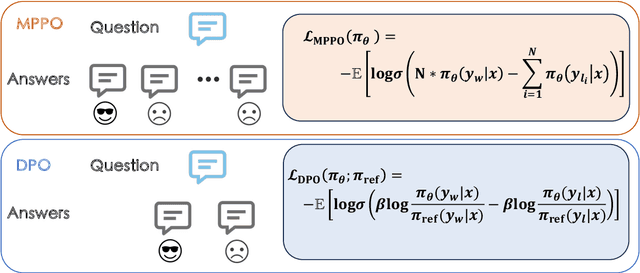

Aligning Large Language Models (LLMs) with human feedback is crucial for their development. Existing preference optimization methods such as DPO and KTO, while improved based on Reinforcement Learning from Human Feedback (RLHF), are inherently derived from PPO, requiring a reference model that adds GPU memory resources and relies heavily on abundant preference data. Meanwhile, current preference optimization research mainly targets single-question scenarios with two replies, neglecting optimization with multiple replies, which leads to a waste of data in the application. This study introduces the MPPO algorithm, which leverages the average likelihood of model responses to fit the reward function and maximizes the utilization of preference data. Through a comparison of Point-wise, Pair-wise, and List-wise implementations, we found that the Pair-wise approach achieves the best performance, significantly enhancing the quality of model responses. Experimental results demonstrate MPPO's outstanding performance across various benchmarks. On MT-Bench, MPPO outperforms DPO, ORPO, and SimPO. Notably, on Arena-Hard, MPPO surpasses DPO and ORPO by substantial margins. These achievements underscore the remarkable advantages of MPPO in preference optimization tasks.
Robust Beamforming with Application in High-Resolution Sensing
Nov 10, 2024


As a fundamental technique in array signal processing, beamforming plays a crucial role in amplifying signals of interest while mitigating interference and noise. When uncertainties exist in the signal model or the data size of snapshots is limited, the performance of beamformers significantly degrades. In this article, we comprehensively study the conceptual system, theoretical analysis, and algorithmic design for robust beamforming. Particularly, four technical approaches for robust beamforming are discussed, including locally robust beamforming, globally robust beamforming, regularized beamforming, and Bayesian-nonparametric beamforming. In addition, we investigate the equivalence among the methods and suggest a unified robust beamforming framework. As an application example, we show that the resolution of robust beamformers for direction-of-arrival (DoA) estimation can be greatly refined by incorporating the characteristics of subspace methods.
EEG-DIF: Early Warning of Epileptic Seizures through Generative Diffusion Model-based Multi-channel EEG Signals Forecasting
Oct 22, 2024



Multi-channel EEG signals are commonly used for the diagnosis and assessment of diseases such as epilepsy. Currently, various EEG diagnostic algorithms based on deep learning have been developed. However, most research efforts focus solely on diagnosing and classifying current signal data but do not consider the prediction of future trends for early warning. Additionally, since multi-channel EEG can be essentially regarded as the spatio-temporal signal data received by detectors at different locations in the brain, how to construct spatio-temporal information representations of EEG signals to facilitate future trend prediction for multi-channel EEG becomes an important problem. This study proposes a multi-signal prediction algorithm based on generative diffusion models (EEG-DIF), which transforms the multi-signal forecasting task into an image completion task, allowing for comprehensive representation and learning of the spatio-temporal correlations and future developmental patterns of multi-channel EEG signals. Here, we employ a publicly available epilepsy EEG dataset to construct and validate the EEG-DIF. The results demonstrate that our method can accurately predict future trends for multi-channel EEG signals simultaneously. Furthermore, the early warning accuracy for epilepsy seizures based on the generated EEG data reaches 0.89. In general, EEG-DIF provides a novel approach for characterizing multi-channel EEG signals and an innovative early warning algorithm for epilepsy seizures, aiding in optimizing and enhancing the clinical diagnosis process. The code is available at https://github.com/JZK00/EEG-DIF.