 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Quantum Satellite Communications: Challenges and Future Directions
May 04, 2026Quantum satellite communication (QSC) is emerging as a strategic technology for secure global networking and long-distance quantum connectivity. This review prioritizes the major challenges that still hinder large-scale deployment, including atmospheric loss, beam pointing and tracking, payload constraints, synchronization, scalability, and integration with terrestrial infrastructure. To contextualize these issues, we provide only a concise overview of the core concepts and enabling technologies behind QSC, together with representative milestones such as the Micius mission. Building on this background, the paper surveys recent advances in protocols, hybrid space--terrestrial architectures, turbulence mitigation, and AI-assisted optimization. It then examines future directions, including quantum Internet integration, daylight operation, satellite-supported repeaters, and space-based quantum computing. By centering the discussion on open technical bottlenecks and emerging research trajectories, this review aims to support researchers and engineers working toward practical and resilient QSC systems.
Interpretable Deep Transfer Learning for Breast Ultrasound Cancer Detection: A Multi-Dataset Study
Sep 05, 2025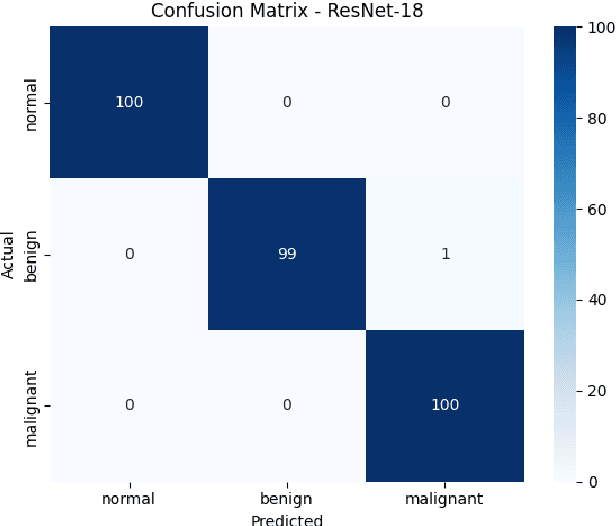
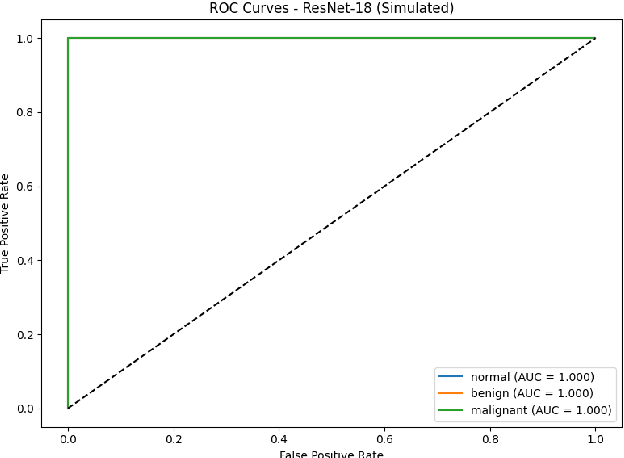
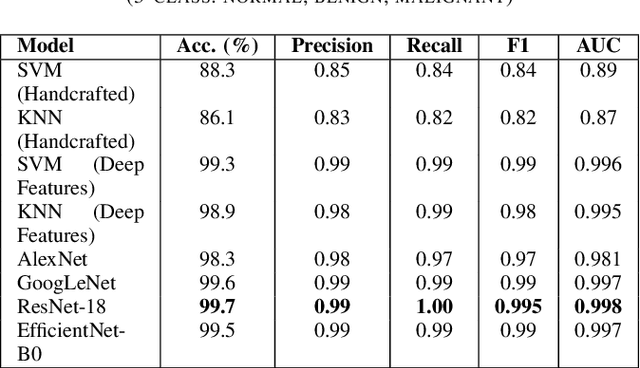
Breast cancer remains a leading cause of cancer-related mortality among women worldwide. Ultrasound imaging, widely used due to its safety and cost-effectiveness, plays a key role in early detection, especially in patients with dense breast tissue. This paper presents a comprehensive study on the application of machine learning and deep learning techniques for breast cancer classification using ultrasound images. Using datasets such as BUSI, BUS-BRA, and BrEaST-Lesions USG, we evaluate classical machine learning models (SVM, KNN) and deep convolutional neural networks (ResNet-18, EfficientNet-B0, GoogLeNet). Experimental results show that ResNet-18 achieves the highest accuracy (99.7%) and perfect sensitivity for malignant lesions. Classical ML models, though outperformed by CNNs, achieve competitive performance when enhanced with deep feature extraction. Grad-CAM visualizations further improve model transparency by highlighting diagnostically relevant image regions. These findings support the integration of AI-based diagnostic tools into clinical workflows and demonstrate the feasibility of deploying high-performing, interpretable systems for ultrasound-based breast cancer detection.
Leveraging Transfer Learning and Mobile-enabled Convolutional Neural Networks for Improved Arabic Handwritten Character Recognition
Sep 05, 2025The study explores the integration of transfer learning (TL) with mobile-enabled convolutional neural networks (MbNets) to enhance Arabic Handwritten Character Recognition (AHCR). Addressing challenges like extensive computational requirements and dataset scarcity, this research evaluates three TL strategies--full fine-tuning, partial fine-tuning, and training from scratch--using four lightweight MbNets: MobileNet, SqueezeNet, MnasNet, and ShuffleNet. Experiments were conducted on three benchmark datasets: AHCD, HIJJA, and IFHCDB. MobileNet emerged as the top-performing model, consistently achieving superior accuracy, robustness, and efficiency, with ShuffleNet excelling in generalization, particularly under full fine-tuning. The IFHCDB dataset yielded the highest results, with 99% accuracy using MnasNet under full fine-tuning, highlighting its suitability for robust character recognition. The AHCD dataset achieved competitive accuracy (97%) with ShuffleNet, while HIJJA posed significant challenges due to its variability, achieving a peak accuracy of 92% with ShuffleNet. Notably, full fine-tuning demonstrated the best overall performance, balancing accuracy and convergence speed, while partial fine-tuning underperformed across metrics. These findings underscore the potential of combining TL and MbNets for resource-efficient AHCR, paving the way for further optimizations and broader applications. Future work will explore architectural modifications, in-depth dataset feature analysis, data augmentation, and advanced sensitivity analysis to enhance model robustness and generalizability.
Hybrid Vision Transformer-Mamba Framework for Autism Diagnosis via Eye-Tracking Analysis
Jun 07, 2025



Accurate Autism Spectrum Disorder (ASD) diagnosis is vital for early intervention. This study presents a hybrid deep learning framework combining Vision Transformers (ViT) and Vision Mamba to detect ASD using eye-tracking data. The model uses attention-based fusion to integrate visual, speech, and facial cues, capturing both spatial and temporal dynamics. Unlike traditional handcrafted methods, it applies state-of-the-art deep learning and explainable AI techniques to enhance diagnostic accuracy and transparency. Tested on the Saliency4ASD dataset, the proposed ViT-Mamba model outperformed existing methods, achieving 0.96 accuracy, 0.95 F1-score, 0.97 sensitivity, and 0.94 specificity. These findings show the model's promise for scalable, interpretable ASD screening, especially in resource-constrained or remote clinical settings where access to expert diagnosis is limited.
Exploring Image Transforms derived from Eye Gaze Variables for Progressive Autism Diagnosis
Jun 07, 2025The prevalence of Autism Spectrum Disorder (ASD) has surged rapidly over the past decade, posing significant challenges in communication, behavior, and focus for affected individuals. Current diagnostic techniques, though effective, are time-intensive, leading to high social and economic costs. This work introduces an AI-powered assistive technology designed to streamline ASD diagnosis and management, enhancing convenience for individuals with ASD and efficiency for caregivers and therapists. The system integrates transfer learning with image transforms derived from eye gaze variables to diagnose ASD. This facilitates and opens opportunities for in-home periodical diagnosis, reducing stress for individuals and caregivers, while also preserving user privacy through the use of image transforms. The accessibility of the proposed method also offers opportunities for improved communication between guardians and therapists, ensuring regular updates on progress and evolving support needs. Overall, the approach proposed in this work ensures timely, accessible diagnosis while protecting the subjects' privacy, improving outcomes for individuals with ASD.
Enhanced Hybrid Deep Learning Approach for Botnet Attacks Detection in IoT Environment
Feb 10, 2025



Cyberattacks in an Internet of Things (IoT) environment can have significant impacts because of the interconnected nature of devices and systems. An attacker uses a network of compromised IoT devices in a botnet attack to carry out various harmful activities. Detecting botnet attacks poses several challenges because of the intricate and evolving nature of these threats. Botnet attacks erode trust in IoT devices and systems, undermining confidence in their security, reliability, and integrity. Deep learning techniques have significantly enhanced the detection of botnet attacks due to their ability to analyze and learn from complex patterns in data. This research proposed the stacking of Deep convolutional neural networks, Bi-Directional Long Short-Term Memory (Bi-LSTM), Bi-Directional Gated Recurrent Unit (Bi-GRU), and Recurrent Neural Networks (RNN) for botnet attacks detection. The UNSW-NB15 dataset is utilized for botnet attacks detection. According to experimental results, the proposed model accurately provides for the intricate patterns and features of botnet attacks, with a testing accuracy of 99.76%. The proposed model also identifies botnets with a high ROC-AUC curve value of 99.18%. A performance comparison of the proposed method with existing state-of-the-art models confirms its higher performance. The outcomes of this research could strengthen cyber security procedures and safeguard against new attacks.
Analysing Osteoporosis Detection: A Comparative Study of CNN and FNN
Oct 11, 2024



Osteoporosis causes progressive loss of bone density and strength, causing a more elevated risk of fracture than in normal healthy bones. It is estimated that some 1 in 3 women and 1 in 5 men over the age of 50 will experience osteoporotic fractures, which poses osteoporosis as an important public health problem worldwide. The basis of diagnosis is based on Bone Mineral Density (BMD) tests, with Dual-energy X-ray Absorptiometry (DEXA) being the most common. A T-score of -2.5 or lower defines osteoporosis. This paper focuses on the application of medical imaging analytics towards the detection of osteoporosis by conducting a comparative study of the efficiency of CNN and FNN in DEXA image analytics. Both models are very promising, although, at 95%, the FNN marginally outperformed the CNN at 93%. Hence, this research underlines the probable capability of deep learning techniques in improving the detection of osteoporosis and optimizing diagnostic tools in order to achieve better patient outcomes.
Applications of Knowledge Distillation in Remote Sensing: A Survey
Sep 18, 2024



With the ever-growing complexity of models in the field of remote sensing (RS), there is an increasing demand for solutions that balance model accuracy with computational efficiency. Knowledge distillation (KD) has emerged as a powerful tool to meet this need, enabling the transfer of knowledge from large, complex models to smaller, more efficient ones without significant loss in performance. This review article provides an extensive examination of KD and its innovative applications in RS. KD, a technique developed to transfer knowledge from a complex, often cumbersome model (teacher) to a more compact and efficient model (student), has seen significant evolution and application across various domains. Initially, we introduce the fundamental concepts and historical progression of KD methods. The advantages of employing KD are highlighted, particularly in terms of model compression, enhanced computational efficiency, and improved performance, which are pivotal for practical deployments in RS scenarios. The article provides a comprehensive taxonomy of KD techniques, where each category is critically analyzed to demonstrate the breadth and depth of the alternative options, and illustrates specific case studies that showcase the practical implementation of KD methods in RS tasks, such as instance segmentation and object detection. Further, the review discusses the challenges and limitations of KD in RS, including practical constraints and prospective future directions, providing a comprehensive overview for researchers and practitioners in the field of RS. Through this organization, the paper not only elucidates the current state of research in KD but also sets the stage for future research opportunities, thereby contributing significantly to both academic research and real-world applications.
Deep Transfer Learning for Kidney Cancer Diagnosis
Aug 08, 2024



Many incurable diseases prevalent across global societies stem from various influences, including lifestyle choices, economic conditions, social factors, and genetics. Research predominantly focuses on these diseases due to their widespread nature, aiming to decrease mortality, enhance treatment options, and improve healthcare standards. Among these, kidney disease stands out as a particularly severe condition affecting men and women worldwide. Nonetheless, there is a pressing need for continued research into innovative, early diagnostic methods to develop more effective treatments for such diseases. Recently, automatic diagnosis of Kidney Cancer has become an important challenge especially when using deep learning (DL) due to the importance of training medical datasets, which in most cases are difficult and expensive to obtain. Furthermore, in most cases, algorithms require data from the same domain and a powerful computer with efficient storage capacity. To overcome this issue, a new type of learning known as transfer learning (TL) has been proposed that can produce impressive results based on other different pre-trained data. This paper presents, to the best of the authors' knowledge, the first comprehensive survey of DL-based TL frameworks for kidney cancer diagnosis. This is a strong contribution to help researchers understand the current challenges and perspectives of this topic. Hence, the main limitations and advantages of each framework are identified and detailed critical analyses are provided. Looking ahead, the article identifies promising directions for future research. Moving on, the discussion is concluded by reflecting on the pivotal role of TL in the development of precision medicine and its effects on clinical practice and research in oncology.
Advancing 3D Point Cloud Understanding through Deep Transfer Learning: A Comprehensive Survey
Jul 25, 2024



The 3D point cloud (3DPC) has significantly evolved and benefited from the advance of deep learning (DL). However, the latter faces various issues, including the lack of data or annotated data, the existence of a significant gap between training data and test data, and the requirement for high computational resources. To that end, deep transfer learning (DTL), which decreases dependency and costs by utilizing knowledge gained from a source data/task in training a target data/task, has been widely investigated. Numerous DTL frameworks have been suggested for aligning point clouds obtained from several scans of the same scene. Additionally, DA, which is a subset of DTL, has been modified to enhance the point cloud data's quality by dealing with noise and missing points. Ultimately, fine-tuning and DA approaches have demonstrated their effectiveness in addressing the distinct difficulties inherent in point cloud data. This paper presents the first review shedding light on this aspect. it provides a comprehensive overview of the latest techniques for understanding 3DPC using DTL and domain adaptation (DA). Accordingly, DTL's background is first presented along with the datasets and evaluation metrics. A well-defined taxonomy is introduced, and detailed comparisons are presented, considering different aspects such as different knowledge transfer strategies, and performance. The paper covers various applications, such as 3DPC object detection, semantic labeling, segmentation, classification, registration, downsampling/upsampling, and denoising. Furthermore, the article discusses the advantages and limitations of the presented frameworks, identifies open challenges, and suggests potential research directions.