 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Flow to Action Map: A New Representation for RGB-D based Action Recognition with Convolutional Neural Networks
Mar 27, 2017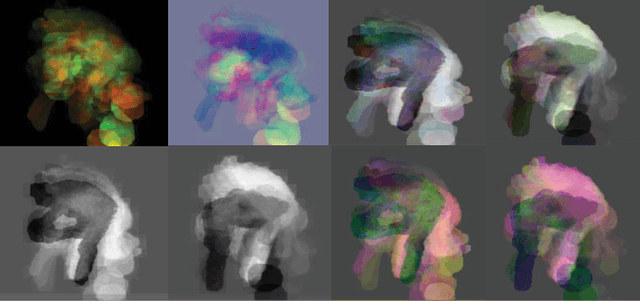
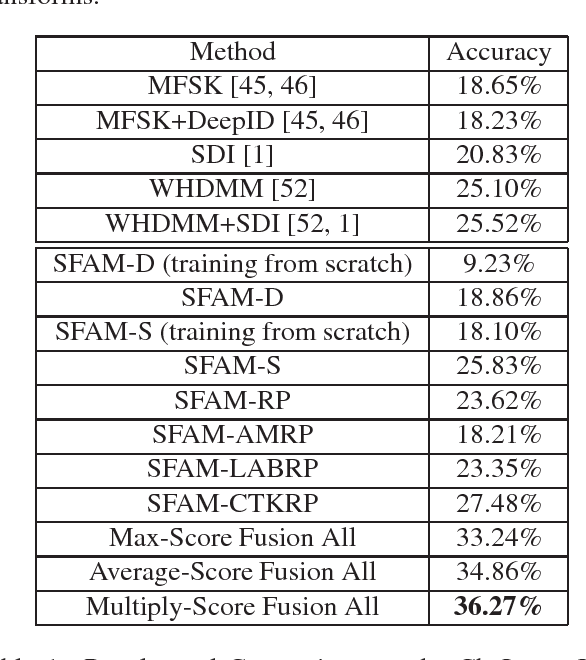

Scene flow describes the motion of 3D objects in real world and potentially could be the basis of a good feature for 3D action recognition. However, its use for action recognition, especially in the context of convolutional neural networks (ConvNets), has not been previously studied. In this paper, we propose the extraction and use of scene flow for action recognition from RGB-D data. Previous works have considered the depth and RGB modalities as separate channels and extract features for later fusion. We take a different approach and consider the modalities as one entity, thus allowing feature extraction for action recognition at the beginning. Two key questions about the use of scene flow for action recognition are addressed: how to organize the scene flow vectors and how to represent the long term dynamics of videos based on scene flow. In order to calculate the scene flow correctly on the available datasets, we propose an effective self-calibration method to align the RGB and depth data spatially without knowledge of the camera parameters. Based on the scene flow vectors, we propose a new representation, namely, Scene Flow to Action Map (SFAM), that describes several long term spatio-temporal dynamics for action recognition. We adopt a channel transform kernel to transform the scene flow vectors to an optimal color space analogous to RGB. This transformation takes better advantage of the trained ConvNets models over ImageNet. Experimental results indicate that this new representation can surpass the performance of state-of-the-art methods on two large public datasets.
Large-scale Isolated Gesture Recognition Using Convolutional Neural Networks
Jan 07, 2017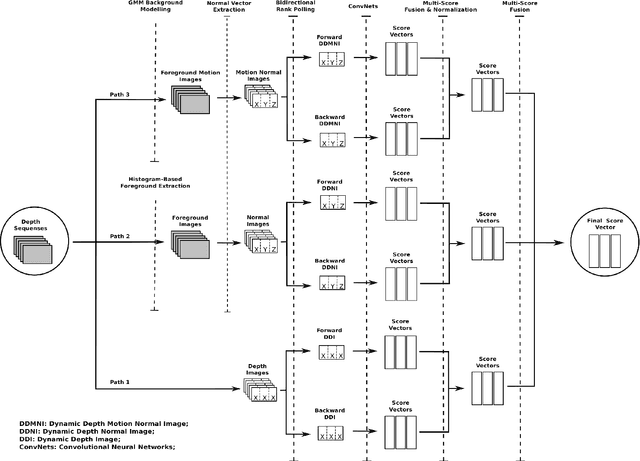


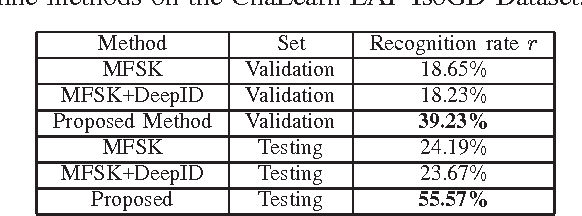
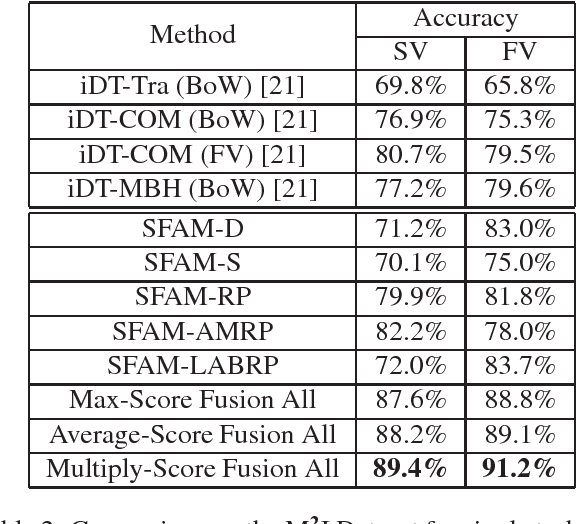
This paper proposes three simple, compact yet effective representations of depth sequences, referred to respectively as Dynamic Depth Images (DDI), Dynamic Depth Normal Images (DDNI) and Dynamic Depth Motion Normal Images (DDMNI). These dynamic images are constructed from a sequence of depth maps using bidirectional rank pooling to effectively capture the spatial-temporal information. Such image-based representations enable us to fine-tune the existing ConvNets models trained on image data for classification of depth sequences, without introducing large parameters to learn. Upon the proposed representations, a convolutional Neural networks (ConvNets) based method is developed for gesture recognition and evaluated on the Large-scale Isolated Gesture Recognition at the ChaLearn Looking at People (LAP) challenge 2016. The method achieved 55.57\% classification accuracy and ranked $2^{nd}$ place in this challenge but was very close to the best performance even though we only used depth data.
Action Recognition Based on Joint Trajectory Maps with Convolutional Neural Networks
Dec 30, 2016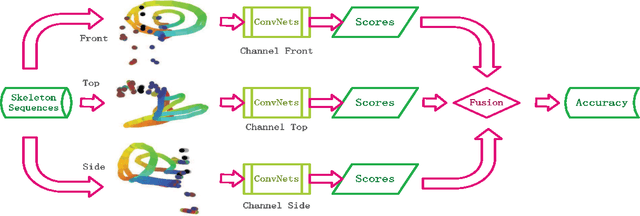
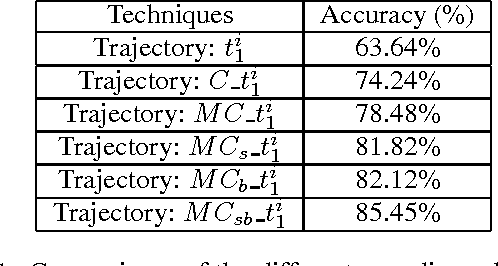


Convolutional Neural Networks (ConvNets) have recently shown promising performance in many computer vision tasks, especially image-based recognition. How to effectively apply ConvNets to sequence-based data is still an open problem. This paper proposes an effective yet simple method to represent spatio-temporal information carried in $3D$ skeleton sequences into three $2D$ images by encoding the joint trajectories and their dynamics into color distribution in the images, referred to as Joint Trajectory Maps (JTM), and adopts ConvNets to learn the discriminative features for human action recognition. Such an image-based representation enables us to fine-tune existing ConvNets models for the classification of skeleton sequences without training the networks afresh. The three JTMs are generated in three orthogonal planes and provide complimentary information to each other. The final recognition is further improved through multiply score fusion of the three JTMs. The proposed method was evaluated on four public benchmark datasets, the large NTU RGB+D Dataset, MSRC-12 Kinect Gesture Dataset (MSRC-12), G3D Dataset and UTD Multimodal Human Action Dataset (UTD-MHAD) and achieved the state-of-the-art results.
Exploiting Structure Sparsity for Covariance-based Visual Representation
Nov 27, 2016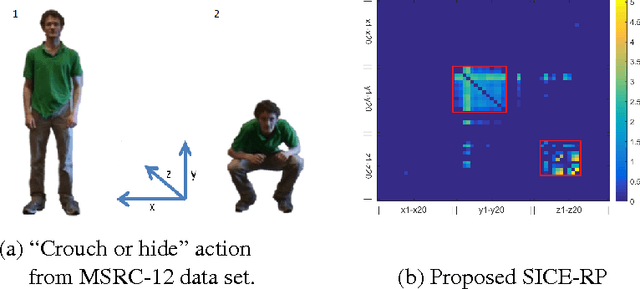
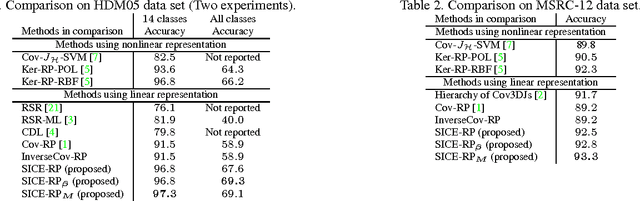
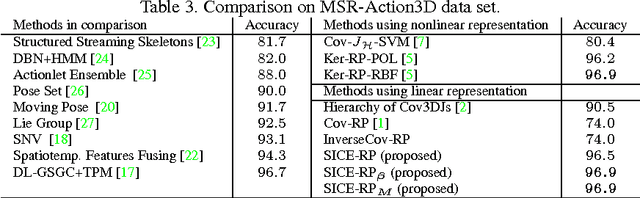

The past few years have witnessed increasing research interest on covariance-based feature representation. A variety of methods have been proposed to boost its efficacy, with some recent ones resorting to nonlinear kernel technique. Noting that the essence of this feature representation is to characterise the underlying structure of visual features, this paper argues that an equally, if not more, important approach to boosting its efficacy shall be to improve the quality of this characterisation. Following this idea, we propose to exploit the structure sparsity of visual features in skeletal human action recognition, and compute sparse inverse covariance estimate (SICE) as feature representation. We discuss the advantage of this new representation on dealing with small sample, high dimensionality, and modelling capability. Furthermore, utilising the monotonicity property of SICE, we efficiently generate a hierarchy of SICE matrices to characterise the structure of visual features at different sparsity levels, and two discriminative learning algorithms are then developed to adaptively integrate them to perform recognition. As demonstrated by extensive experiments, the proposed representation leads to significantly improved recognition performance over the state-of-the-art comparable methods. In particular, as a method fully based on linear technique, it is comparable or even better than those employing nonlinear kernel technique. This result well demonstrates the value of exploiting structure sparsity for covariance-based feature representation.
Action Recognition Based on Joint Trajectory Maps Using Convolutional Neural Networks
Nov 13, 2016Recently, Convolutional Neural Networks (ConvNets) have shown promising performances in many computer vision tasks, especially image-based recognition. How to effectively use ConvNets for video-based recognition is still an open problem. In this paper, we propose a compact, effective yet simple method to encode spatio-temporal information carried in $3D$ skeleton sequences into multiple $2D$ images, referred to as Joint Trajectory Maps (JTM), and ConvNets are adopted to exploit the discriminative features for real-time human action recognition. The proposed method has been evaluated on three public benchmarks, i.e., MSRC-12 Kinect gesture dataset (MSRC-12), G3D dataset and UTD multimodal human action dataset (UTD-MHAD) and achieved the state-of-the-art results.
Large-scale Continuous Gesture Recognition Using Convolutional Neural Networks
Sep 12, 2016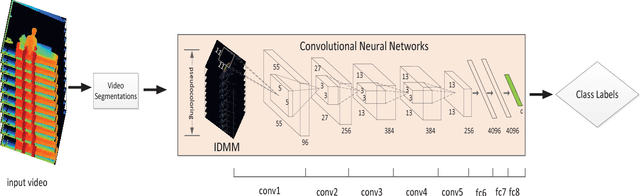


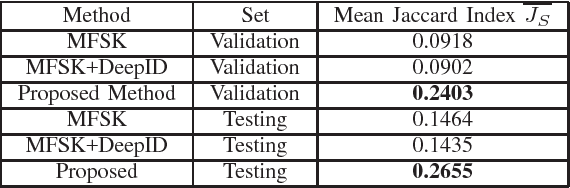
This paper addresses the problem of continuous gesture recognition from sequences of depth maps using convolutional neutral networks (ConvNets). The proposed method first segments individual gestures from a depth sequence based on quantity of movement (QOM). For each segmented gesture, an Improved Depth Motion Map (IDMM), which converts the depth sequence into one image, is constructed and fed to a ConvNet for recognition. The IDMM effectively encodes both spatial and temporal information and allows the fine-tuning with existing ConvNet models for classification without introducing millions of parameters to learn. The proposed method is evaluated on the Large-scale Continuous Gesture Recognition of the ChaLearn Looking at People (LAP) challenge 2016. It achieved the performance of 0.2655 (Mean Jaccard Index) and ranked $3^{rd}$ place in this challenge.
Learning a Pose Lexicon for Semantic Action Recognition
Apr 01, 2016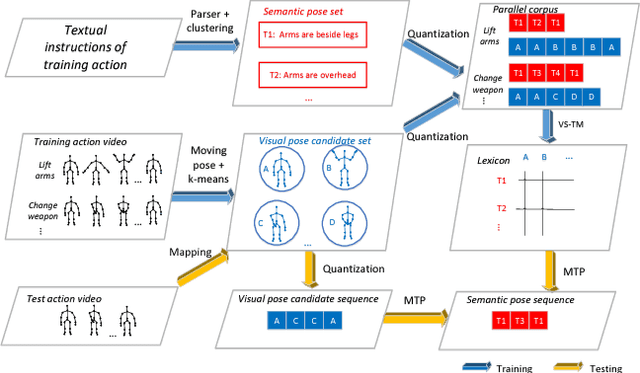
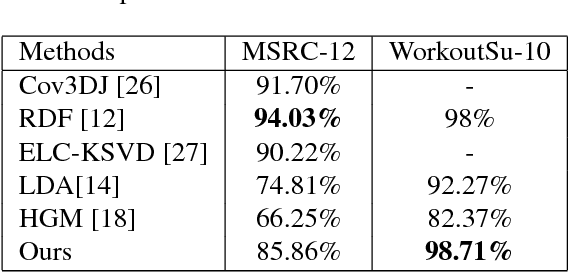
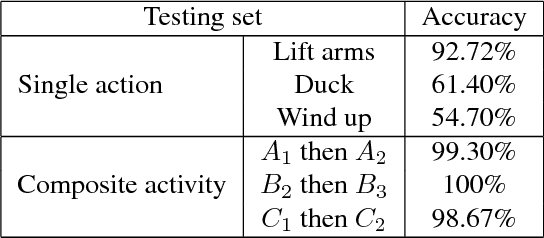
This paper presents a novel method for learning a pose lexicon comprising semantic poses defined by textual instructions and their associated visual poses defined by visual features. The proposed method simultaneously takes two input streams, semantic poses and visual pose candidates, and statistically learns a mapping between them to construct the lexicon. With the learned lexicon, action recognition can be cast as the problem of finding the maximum translation probability of a sequence of semantic poses given a stream of visual pose candidates. Experiments evaluating pre-trained and zero-shot action recognition conducted on MSRC-12 gesture and WorkoutSu-10 exercise datasets were used to verify the efficacy of the proposed method.
Planogram Compliance Checking Based on Detection of Recurring Patterns
Feb 22, 2016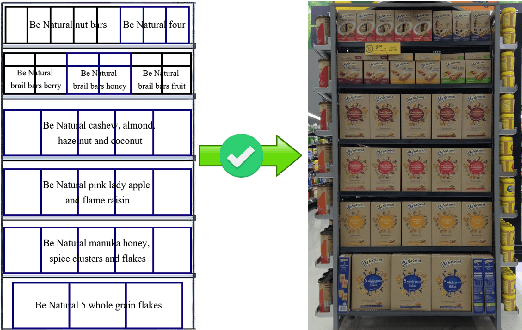
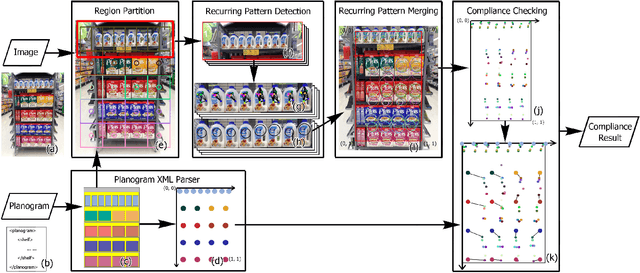
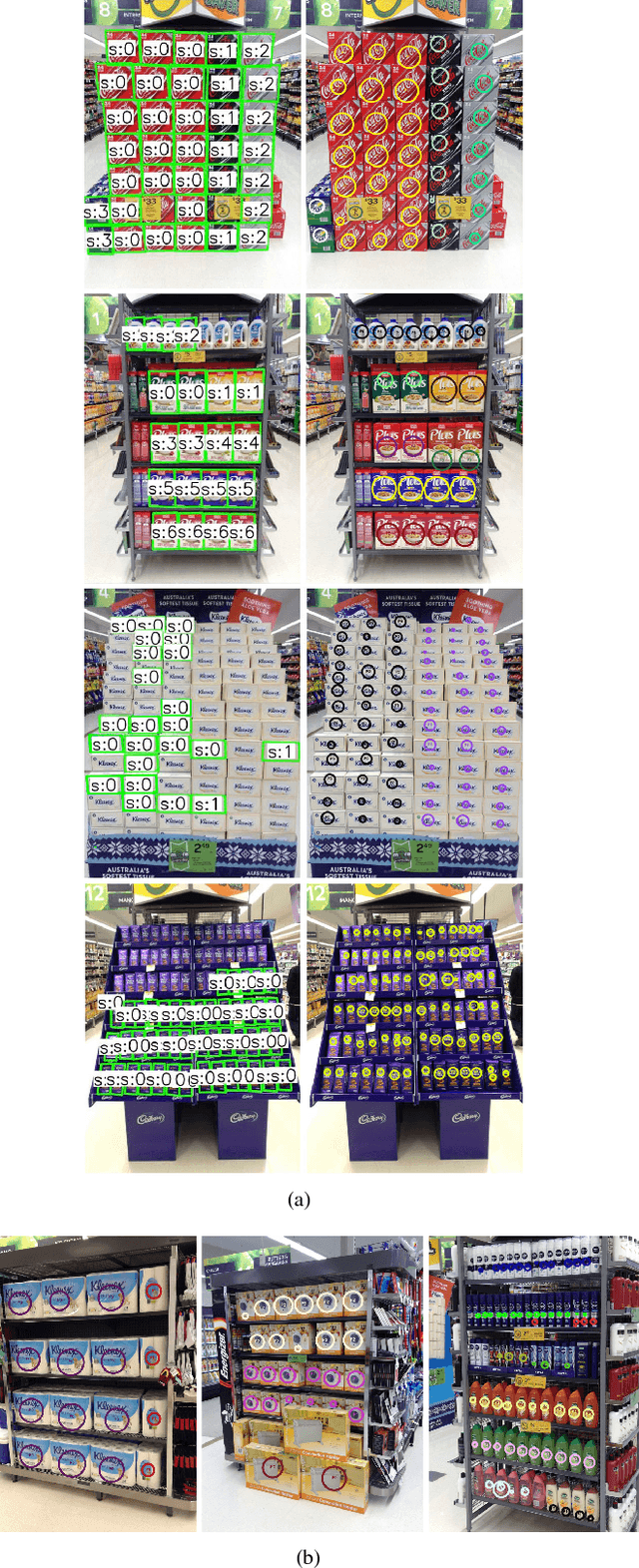
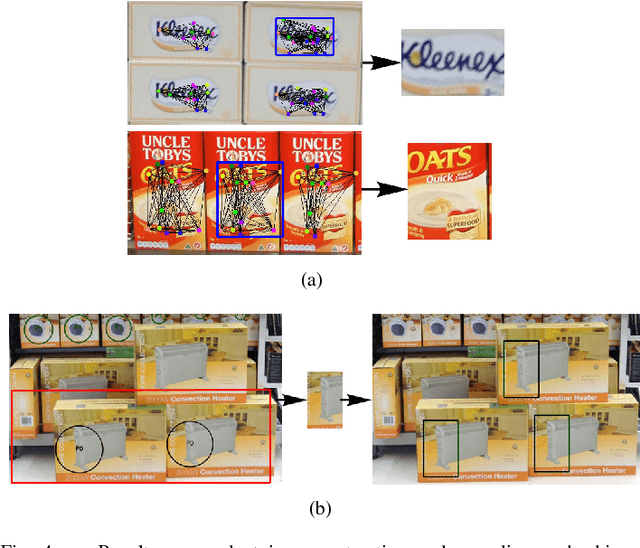
In this paper, a novel method for automatic planogram compliance checking in retail chains is proposed without requiring product template images for training. Product layout is extracted from an input image by means of unsupervised recurring pattern detection and matched via graph matching with the expected product layout specified by a planogram to measure the level of compliance. A divide and conquer strategy is employed to improve the speed. Specifically, the input image is divided into several regions based on the planogram. Recurring patterns are detected in each region respectively and then merged together to estimate the product layout. Experimental results on real data have verified the efficacy of the proposed method. Compared with a template-based method, higher accuracies are achieved by the proposed method over a wide range of products.
Creating Simplified 3D Models with High Quality Textures
Feb 22, 2016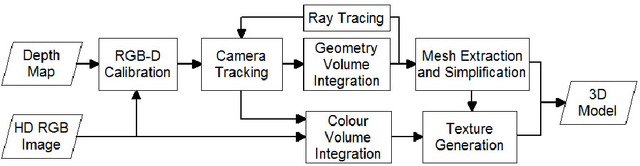



This paper presents an extension to the KinectFusion algorithm which allows creating simplified 3D models with high quality RGB textures. This is achieved through (i) creating model textures using images from an HD RGB camera that is calibrated with Kinect depth camera, (ii) using a modified scheme to update model textures in an asymmetrical colour volume that contains a higher number of voxels than that of the geometry volume, (iii) simplifying dense polygon mesh model using quadric-based mesh decimation algorithm, and (iv) creating and mapping 2D textures to every polygon in the output 3D model. The proposed method is implemented in real-time by means of GPU parallel processing. Visualization via ray casting of both geometry and colour volumes provides users with a real-time feedback of the currently scanned 3D model. Experimental results show that the proposed method is capable of keeping the model texture quality even for a heavily decimated model and that, when reconstructing small objects, photorealistic RGB textures can still be reconstructed.
Combining ConvNets with Hand-Crafted Features for Action Recognition Based on an HMM-SVM Classifier
Feb 01, 2016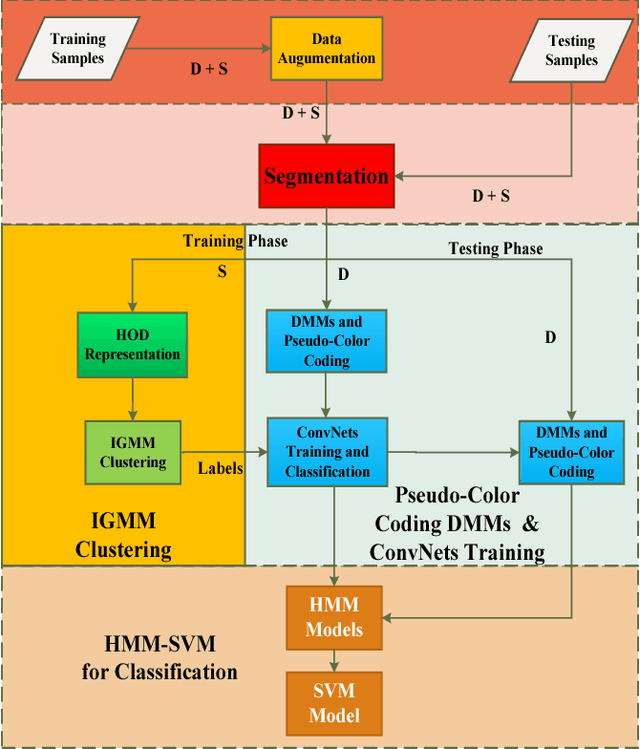
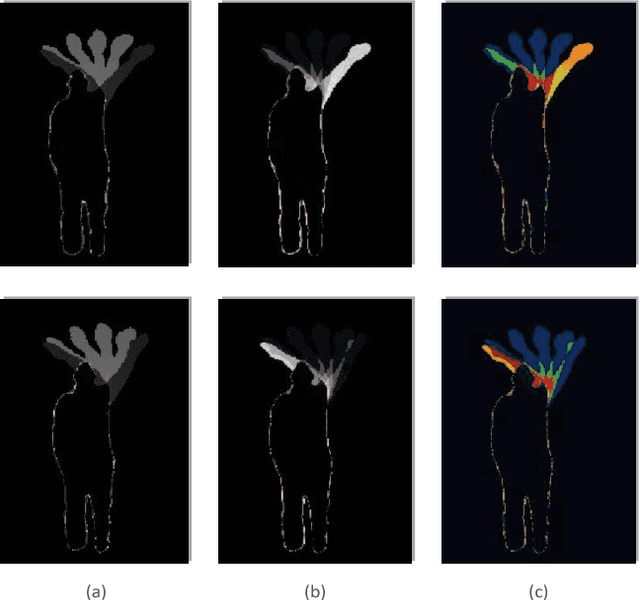
This paper proposes a new framework for RGB-D-based action recognition that takes advantages of hand-designed features from skeleton data and deeply learned features from depth maps, and exploits effectively both the local and global temporal information. Specifically, depth and skeleton data are firstly augmented for deep learning and making the recognition insensitive to view variance. Secondly, depth sequences are segmented using the hand-crafted features based on skeleton joints motion histogram to exploit the local temporal information. All training se gments are clustered using an Infinite Gaussian Mixture Model (IGMM) through Bayesian estimation and labelled for training Convolutional Neural Networks (ConvNets) on the depth maps. Thus, a depth sequence can be reliably encoded into a sequence of segment labels. Finally, the sequence of labels is fed into a joint Hidden Markov Model and Support Vector Machine (HMM-SVM) classifier to explore the global temporal information for final recognition.