 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Role of Mood Patterns in Predicting Self-Reported Depressive symptoms
Jun 14, 2020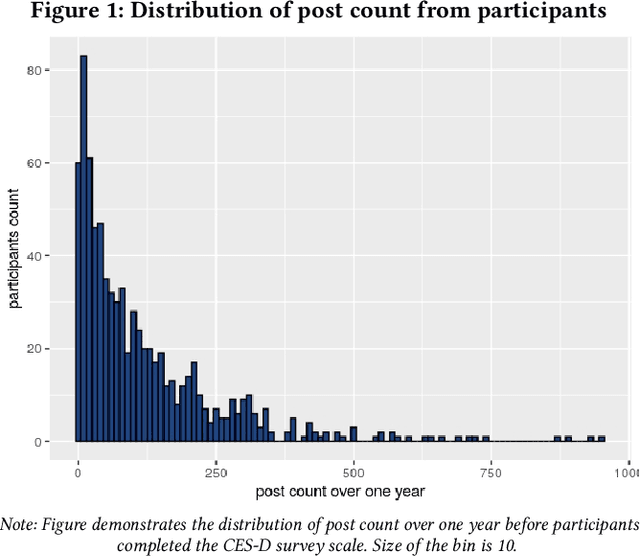
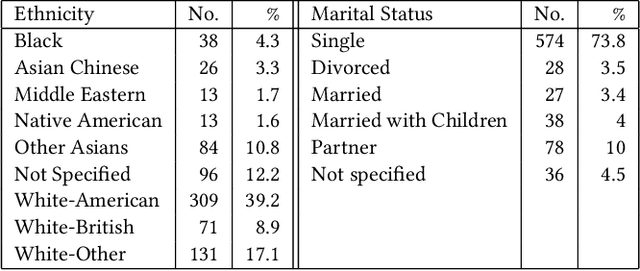
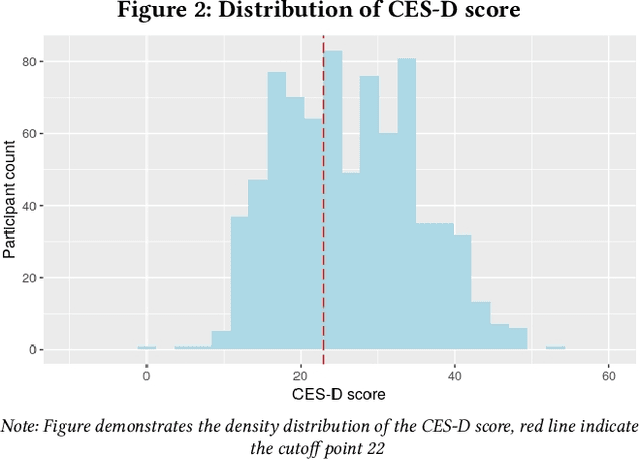
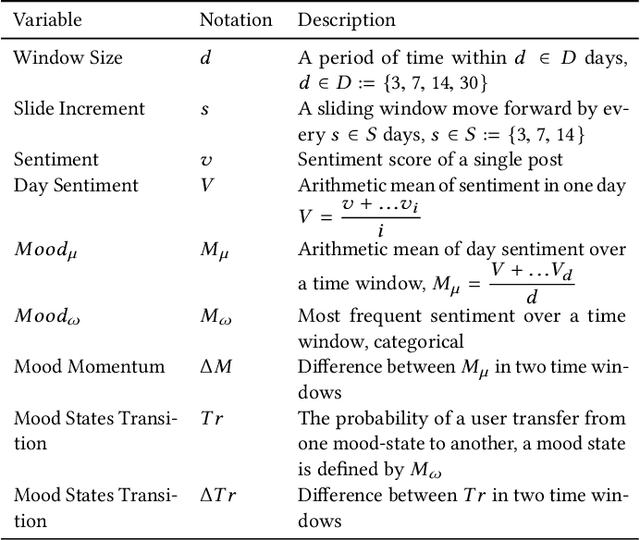
Depression is the leading cause of disability worldwide. Initial efforts to detect depression signals from social media posts have shown promising results. Given the high internal validity, results from such analyses are potentially beneficial to clinical judgment. The existing models for automatic detection of depressive symptoms learn proxy diagnostic signals from social media data, such as help-seeking behavior for mental health or medication names. However, in reality, individuals with depression typically experience depressed mood, loss of pleasure nearly in all the activities, feeling of worthlessness or guilt, and diminished ability to think. Therefore, a lot of the proxy signals used in these models lack the theoretical underpinnings for depressive symptoms. It is also reported that social media posts from many patients in the clinical setting do not contain these signals. Based on this research gap, we propose to monitor a type of signal that is well-established as a class of symptoms in affective disorders -- mood. The mood is an experience of feeling that can last for hours, days, or even weeks. In this work, we attempt to enrich current technology for detecting symptoms of potential depression by constructing a 'mood profile' for social media users.
Stance Detection on Social Media: State of the Art and Trends
Jun 11, 2020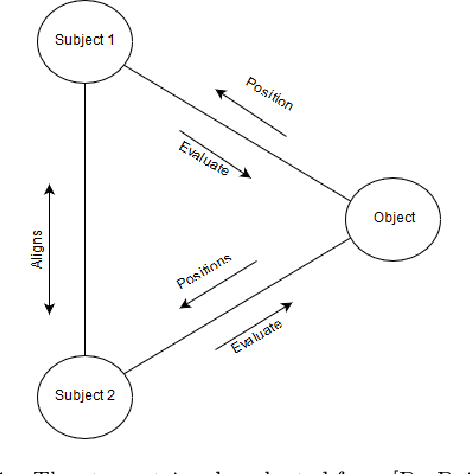
Stance detection on social media is an emerging opinion mining paradigm for various social and political applications where sentiment analysis might be sub-optimal. This paper surveys the work on stance detection and situates its usage within current opinion mining techniques in social media. An exhaustive review of stance detection techniques on social media is presented,including the task definition, the different types of targets in stance detection, the features set used, and the various machine learning approaches applied. The survey reports the state-of-the-art results on the existing benchmark datasets on stance detection, and discusses the most effective approaches. In addition, this study explores the emerging trends and the different applications of stance detection on social media. The study concludes by providing discussion of the gaps in the current existing research and highlighting the possible future directions for stance detection on social media.
Analyzing Temporal Relationships between Trending Terms on Twitter and Urban Dictionary Activity
May 18, 2020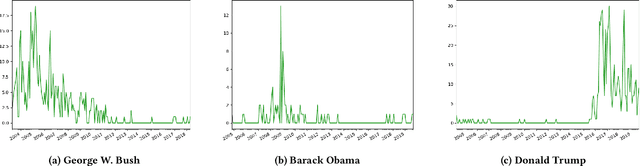
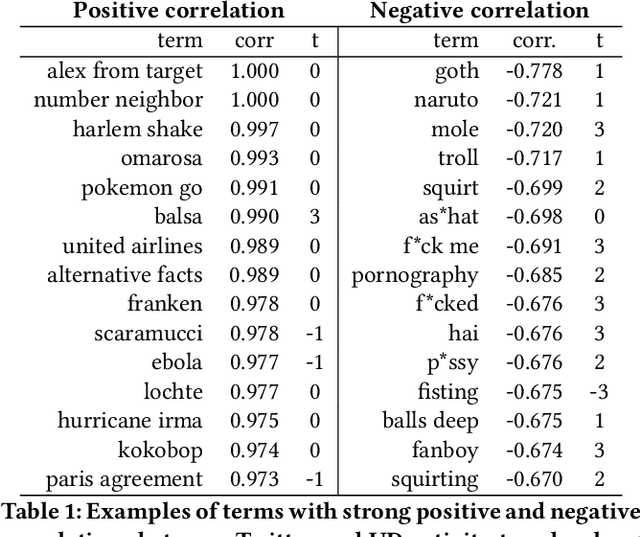

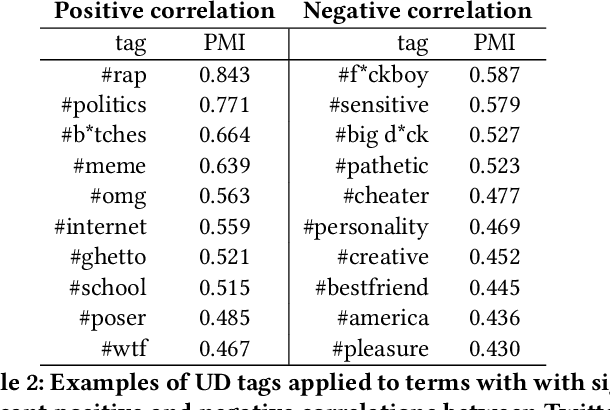
As an online, crowd-sourced, open English-language slang dictionary, the Urban Dictionary platform contains a wealth of opinions, jokes, and definitions of terms, phrases, acronyms, and more. However, it is unclear exactly how activity on this platform relates to larger conversations happening elsewhere on the web, such as discussions on larger, more popular social media platforms. In this research, we study the temporal activity trends on Urban Dictionary and provide the first analysis of how this activity relates to content being discussed on a major social network: Twitter. By collecting the whole of Urban Dictionary, as well as a large sample of tweets over seven years, we explore the connections between the words and phrases that are defined and searched for on Urban Dictionary and the content that is talked about on Twitter. Through a series of cross-correlation calculations, we identify cases in which Urban Dictionary activity closely reflects the larger conversation happening on Twitter. Then, we analyze the types of terms that have a stronger connection to discussions on Twitter, finding that Urban Dictionary activity that is positively correlated with Twitter is centered around terms related to memes, popular public figures, and offline events. Finally, We explore the relationship between periods of time when terms are trending on Twitter and the corresponding activity on Urban Dictionary, revealing that new definitions are more likely to be added to Urban Dictionary for terms that are currently trending on Twitter.
The Effect of Sociocultural Variables on Sarcasm Communication Online
Apr 10, 2020


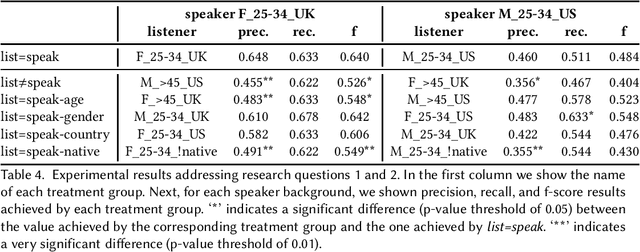
Online social networks (OSN) play an essential role for connecting people and allowing them to communicate online. OSN users share their thoughts, moments, and news with their network. The messages they share online can include sarcastic posts, where the intended meaning expressed by the written text is different from the literal one. This could result in miscommunication. Previous research in psycholinguistics has studied the sociocultural factors the might lead to sarcasm misunderstanding between speakers and listeners. However, there is a lack of such studies in the context of OSN. In this paper we fill this gap by performing a quantitative analysis on the influence of sociocultural variables, including gender, age, country, and English language nativeness, on the effectiveness of sarcastic communication online. We collect examples of sarcastic tweets directly from the authors who posted them. Further, we ask third-party annotators of different sociocultural backgrounds to label these tweets for sarcasm. Our analysis indicates that age, English language nativeness, and country are significantly influential and should be considered in the design of future social analysis tools that either study sarcasm directly, or look at related phenomena where sarcasm may have an influence. We also make observations about the social ecology surrounding sarcastic exchanges on OSNs. We conclude by suggesting ways in which our findings can be included in future work.
SemEval-2016 Task 3: Community Question Answering
Dec 03, 2019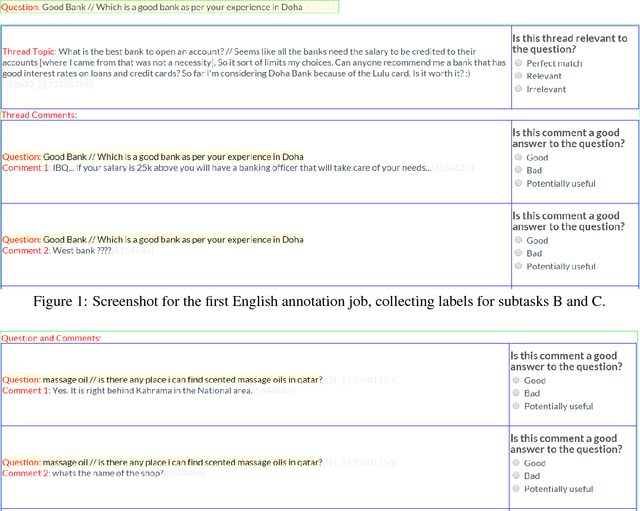
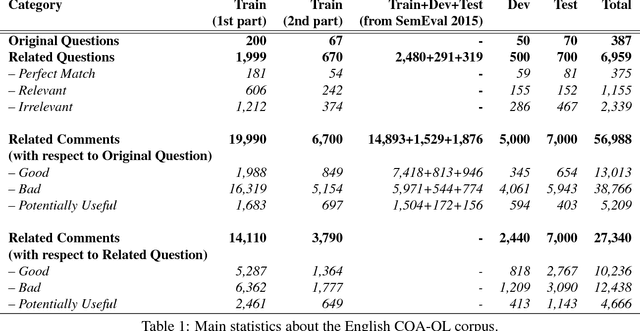
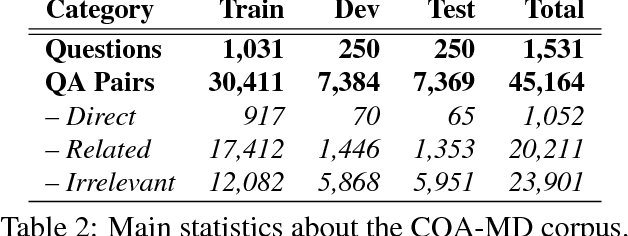
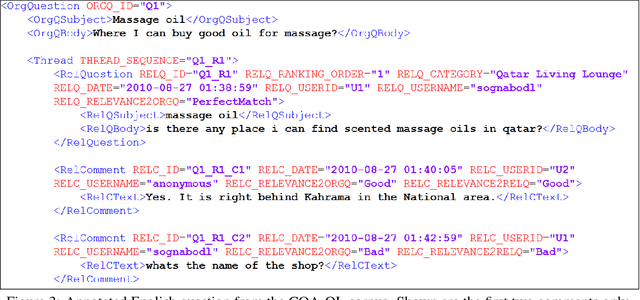
This paper describes the SemEval--2016 Task 3 on Community Question Answering, which we offered in English and Arabic. For English, we had three subtasks: Question--Comment Similarity (subtask A), Question--Question Similarity (B), and Question--External Comment Similarity (C). For Arabic, we had another subtask: Rerank the correct answers for a new question (D). Eighteen teams participated in the task, submitting a total of 95 runs (38 primary and 57 contrastive) for the four subtasks. A variety of approaches and features were used by the participating systems to address the different subtasks, which are summarized in this paper. The best systems achieved an official score (MAP) of 79.19, 76.70, 55.41, and 45.83 in subtasks A, B, C, and D, respectively. These scores are significantly better than those for the baselines that we provided. For subtask A, the best system improved over the 2015 winner by 3 points absolute in terms of Accuracy.
* community question answering, question-question similarity, question-comment similarity, answer reranking, English, Arabic. arXiv admin note: substantial text overlap with arXiv:1912.00730
SemEval-2015 Task 3: Answer Selection in Community Question Answering
Nov 26, 2019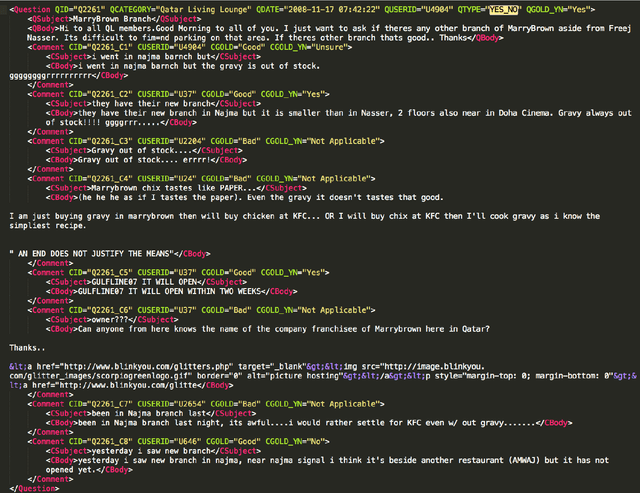
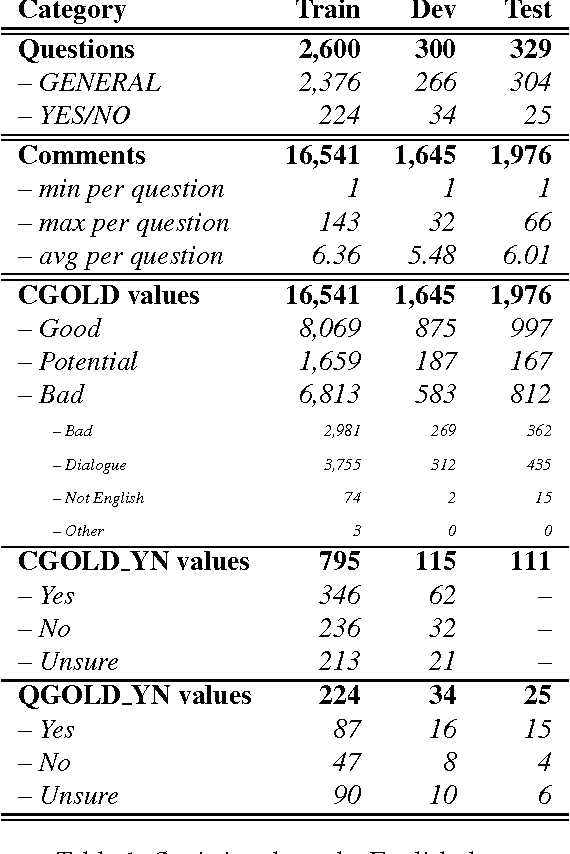
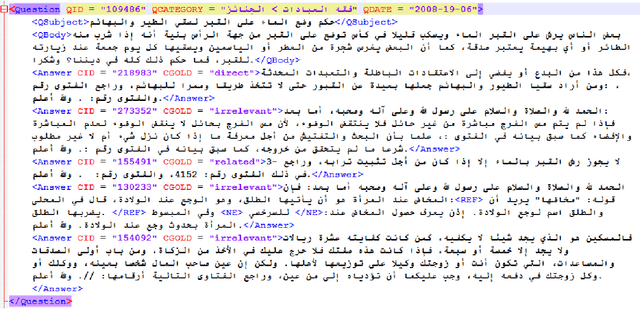
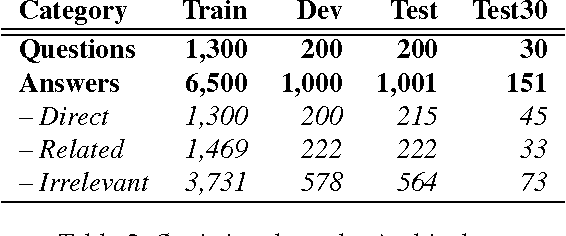
Community Question Answering (cQA) provides new interesting research directions to the traditional Question Answering (QA) field, e.g., the exploitation of the interaction between users and the structure of related posts. In this context, we organized SemEval-2015 Task 3 on "Answer Selection in cQA", which included two subtasks: (a) classifying answers as "good", "bad", or "potentially relevant" with respect to the question, and (b) answering a YES/NO question with "yes", "no", or "unsure", based on the list of all answers. We set subtask A for Arabic and English on two relatively different cQA domains, i.e., the Qatar Living website for English, and a Quran-related website for Arabic. We used crowdsourcing on Amazon Mechanical Turk to label a large English training dataset, which we released to the research community. Thirteen teams participated in the challenge with a total of 61 submissions: 24 primary and 37 contrastive. The best systems achieved an official score (macro-averaged F1) of 57.19 and 63.7 for the English subtasks A and B, and 78.55 for the Arabic subtask A.
* community question answering, answer selection, English, Arabic
iSarcasm: A Dataset of Intended Sarcasm
Nov 08, 2019


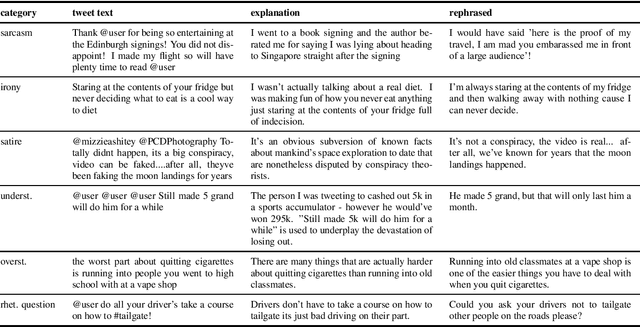
This paper considers the distinction between intended and perceived sarcasm in the context of textual sarcasm detection. The former occurs when an utterance is sarcastic from the perspective of its author, while the latter occurs when the utterance is interpreted as sarcastic by the audience. We show the limitations of previous labelling methods in capturing intended sarcasm and introduce the iSarcasm dataset of tweets labeled for sarcasm directly by their authors. We experiment with sarcasm detection models on our dataset. The low performance indicates that sarcasm might be a phenomenon under-studied computationally thus far.
Exploring Author Context for Detecting Intended vs Perceived Sarcasm
Oct 25, 2019
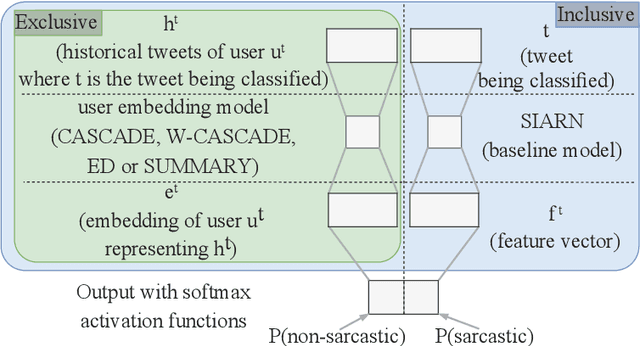
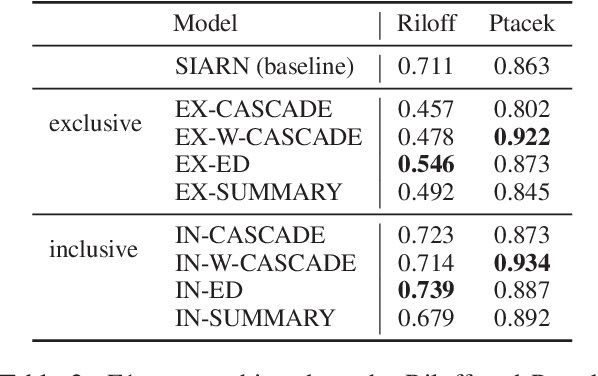
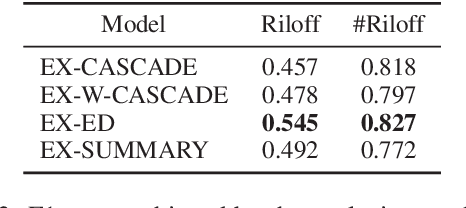
We investigate the impact of using author context on textual sarcasm detection. We define author context as the embedded representation of their historical posts on Twitter and suggest neural models that extract these representations. We experiment with two tweet datasets, one labelled manually for sarcasm, and the other via tag-based distant supervision. We achieve state-of-the-art performance on the second dataset, but not on the one labelled manually, indicating a difference between intended sarcasm, captured by distant supervision, and perceived sarcasm, captured by manual labelling.
* 6 pages, 1 figure, ACL 2020
Assessing Sentiment of the Expressed Stance on Social Media
Aug 08, 2019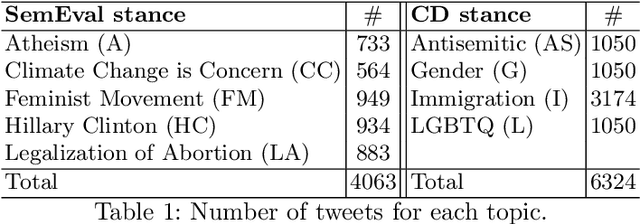
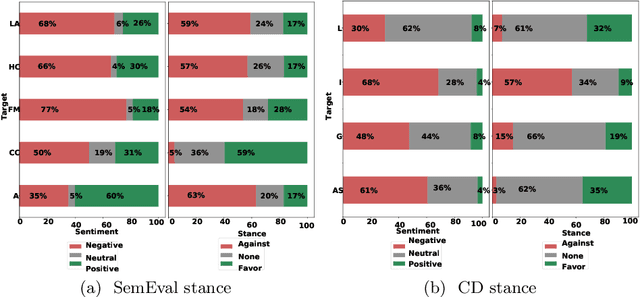
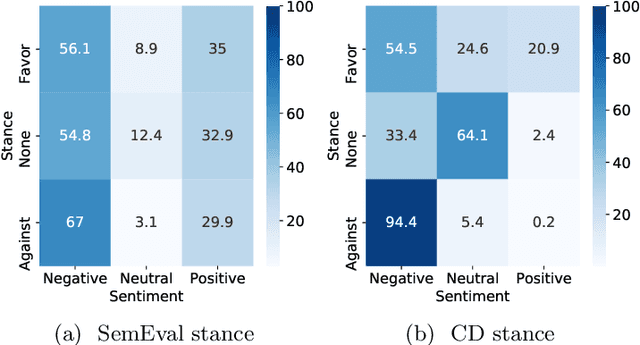

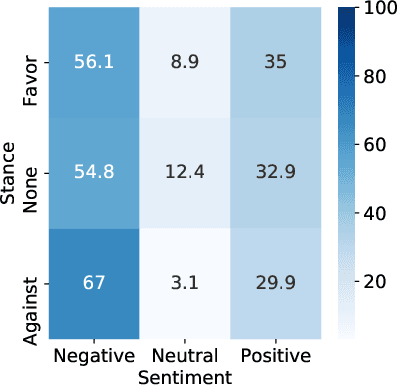
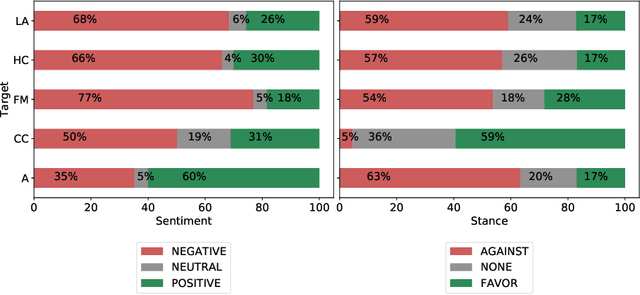
Stance detection is the task of inferring viewpoint towards a given topic or entity either being supportive or opposing. One may express a viewpoint towards a topic by using positive or negative language. This paper examines how the stance is being expressed in social media according to the sentiment polarity. There has been a noticeable misconception of the similarity between the stance and sentiment when it comes to viewpoint discovery, where negative sentiment is assumed to mean against stance, and positive sentiment means in-favour stance. To analyze the relation between stance and sentiment, we construct a new dataset with four topics and examine how people express their viewpoint with regards these topics. We validate our results by carrying a further analysis of the popular stance benchmark SemEval stance dataset. Our analyses reveal that sentiment and stance are not highly aligned, and hence the simple sentiment polarity cannot be used solely to denote a stance toward a given topic.
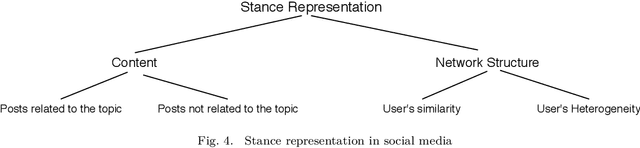
Your Stance is Exposed! Analysing Possible Factors for Stance Detection on Social Media
Aug 08, 2019
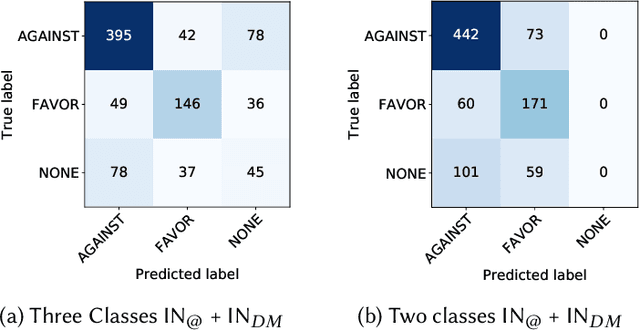
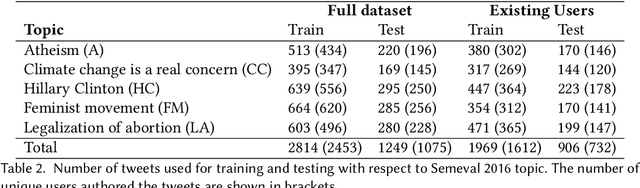
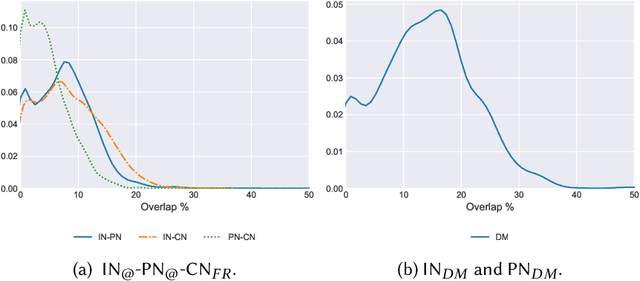
To what extent user's stance towards a given topic could be inferred? Most of the studies on stance detection have focused on analysing user's posts on a given topic to predict the stance. However, the stance in social media can be inferred from a mixture of signals that might reflect user's beliefs including posts and online interactions. This paper examines various online features of users to detect their stance towards different topics. We compare multiple set of features, including on-topic content, network interactions, user's preferences, and online network connections. Our objective is to understand the online signals that can reveal the users' stance. Experimentation is applied on tweets dataset from the SemEval stance detection task, which covers five topics. Results show that stance of a user can be detected with multiple signals of user's online activity, including their posts on the topic, the network they interact with or follow, the websites they visit, and the content they like. The performance of the stance modelling using different network features are comparable with the state-of-the-art reported model that used textual content only. In addition, combining network and content features leads to the highest reported performance to date on the SemEval dataset with F-measure of 72.49%. We further present an extensive analysis to show how these different set of features can reveal stance. Our findings have distinct privacy implications, where they highlight that stance is strongly embedded in user's online social network that, in principle, individuals can be profiled from their interactions and connections even when they do not post about the topic.