 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBRACE: Shaping Inclusive Opinion Representation by Aligning Implicit Conversations with Social Norms
Jul 27, 2025Shaping inclusive representations that embrace diversity and ensure fair participation and reflections of values is at the core of many conversation-based models. However, many existing methods rely on surface inclusion using mention of user demographics or behavioral attributes of social groups. Such methods overlook the nuanced, implicit expression of opinion embedded in conversations. Furthermore, the over-reliance on overt cues can exacerbate misalignment and reinforce harmful or stereotypical representations in model outputs. Thus, we took a step back and recognized that equitable inclusion needs to account for the implicit expression of opinion and use the stance of responses to validate the normative alignment. This study aims to evaluate how opinions are represented in NLP or computational models by introducing an alignment evaluation framework that foregrounds implicit, often overlooked conversations and evaluates the normative social views and discourse. Our approach models the stance of responses as a proxy for the underlying opinion, enabling a considerate and reflective representation of diverse social viewpoints. We evaluate the framework using both (i) positive-unlabeled (PU) online learning with base classifiers, and (ii) instruction-tuned language models to assess post-training alignment. Through this, we provide a lens on how implicit opinions are (mis)represented and offer a pathway toward more inclusive model behavior.
Covert Bias: The Severity of Social Views' Unalignment Towards Implicit and Explicit Opinion
Aug 15, 2024While various approaches have recently been studied for bias identification, little is known about how implicit language that does not explicitly convey a viewpoint affects bias amplification in large language models.To examine the severity of bias toward a view, we evaluated the performance of two downstream tasks where the implicit and explicit knowledge of social groups were used. First, we present a stress test evaluation by using a biased model in edge cases of excessive bias scenarios. Then, we evaluate how LLMs calibrate linguistically in response to both implicit and explicit opinions when they are aligned with conflicting viewpoints. Our findings reveal a discrepancy in LLM performance in identifying implicit and explicit opinions, with a general tendency of bias toward explicit opinions of opposing stances. Moreover, the bias-aligned models generate more cautious responses using uncertainty phrases compared to the unaligned (zero-shot) base models. The direct, incautious responses of the unaligned models suggest a need for further refinement of decisiveness by incorporating uncertainty markers to enhance their reliability, especially on socially nuanced topics with high subjectivity.
Hatred Stems from Ignorance! Distillation of the Persuasion Modes in Countering Conversational Hate Speech
Mar 18, 2024Examining the factors that the counter-speech uses is at the core of understanding the optimal methods for confronting hate speech online. Various studies assess the emotional base factor used in counter speech, such as emotion-empathy, offensiveness, and level of hostility. To better understand the counter-speech used in conversational interactions, this study distills persuasion modes into reason, emotion, and credibility and then evaluates their use in two types of conversation interactions: closed (multi-turn) and open (single-turn) conversation interactions concerning racism, sexism, and religion. The evaluation covers the distinct behaviors of human versus generated counter-speech. We also assess the interplay between the replies' stance and each mode of persuasion in the counter-speech. Notably, we observe nuanced differences in the counter-speech persuasion modes for open and closed interactions -- especially on the topic level -- with a general tendency to use reason as a persuasion mode to express the counterpoint to hate comments. The generated counter-speech tends to exhibit an emotional persuasion mode, while human counters lean towards using reasoning. Furthermore, our study shows that reason as a persuasion mode tends to obtain more supportive replies than do other persuasion types. The findings highlight the potential of incorporating persuasion modes into studies about countering hate speech, as these modes can serve as an optimal means of explainability and paves the way for the further adoption of the reply's stance and the role it plays in assessing what comprises the optimal counter-speech.
Toxicity Inspector: A Framework to Evaluate Ground Truth in Toxicity Detection Through Feedback
May 11, 2023Toxic language is difficult to define, as it is not monolithic and has many variations in perceptions of toxicity. This challenge of detecting toxic language is increased by the highly contextual and subjectivity of its interpretation, which can degrade the reliability of datasets and negatively affect detection model performance. To fill this void, this paper introduces a toxicity inspector framework that incorporates a human-in-the-loop pipeline with the aim of enhancing the reliability of toxicity benchmark datasets by centering the evaluator's values through an iterative feedback cycle. The centerpiece of this framework is the iterative feedback process, which is guided by two metric types (hard and soft) that provide evaluators and dataset creators with insightful examination to balance the tradeoff between performance gains and toxicity avoidance.
Assessing Sentiment of the Expressed Stance on Social Media
Aug 08, 2019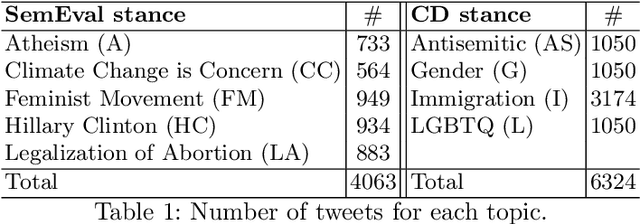
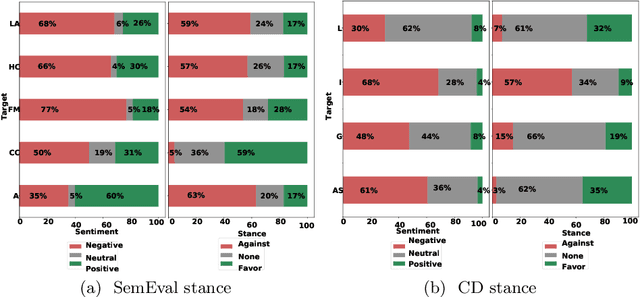
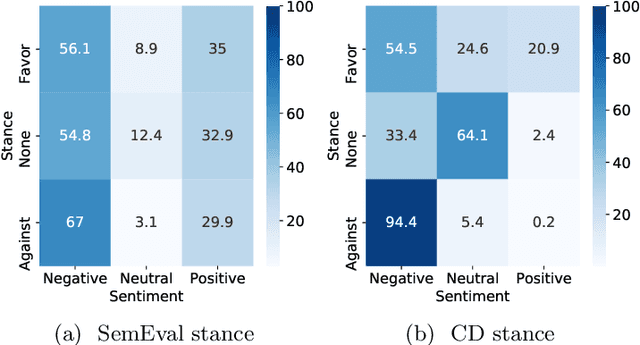

Stance detection is the task of inferring viewpoint towards a given topic or entity either being supportive or opposing. One may express a viewpoint towards a topic by using positive or negative language. This paper examines how the stance is being expressed in social media according to the sentiment polarity. There has been a noticeable misconception of the similarity between the stance and sentiment when it comes to viewpoint discovery, where negative sentiment is assumed to mean against stance, and positive sentiment means in-favour stance. To analyze the relation between stance and sentiment, we construct a new dataset with four topics and examine how people express their viewpoint with regards these topics. We validate our results by carrying a further analysis of the popular stance benchmark SemEval stance dataset. Our analyses reveal that sentiment and stance are not highly aligned, and hence the simple sentiment polarity cannot be used solely to denote a stance toward a given topic.
Your Stance is Exposed! Analysing Possible Factors for Stance Detection on Social Media
Aug 08, 2019
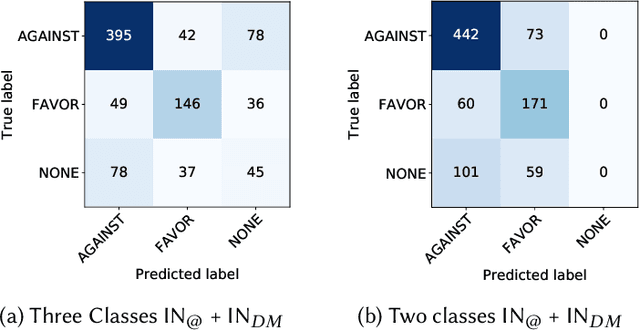
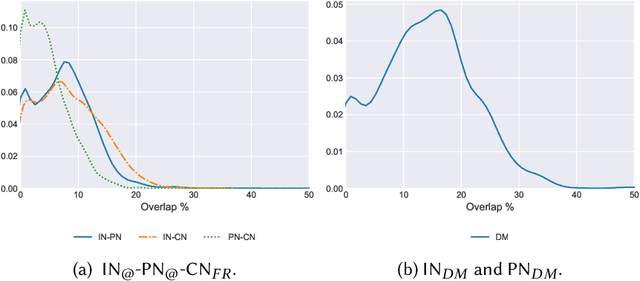
To what extent user's stance towards a given topic could be inferred? Most of the studies on stance detection have focused on analysing user's posts on a given topic to predict the stance. However, the stance in social media can be inferred from a mixture of signals that might reflect user's beliefs including posts and online interactions. This paper examines various online features of users to detect their stance towards different topics. We compare multiple set of features, including on-topic content, network interactions, user's preferences, and online network connections. Our objective is to understand the online signals that can reveal the users' stance. Experimentation is applied on tweets dataset from the SemEval stance detection task, which covers five topics. Results show that stance of a user can be detected with multiple signals of user's online activity, including their posts on the topic, the network they interact with or follow, the websites they visit, and the content they like. The performance of the stance modelling using different network features are comparable with the state-of-the-art reported model that used textual content only. In addition, combining network and content features leads to the highest reported performance to date on the SemEval dataset with F-measure of 72.49%. We further present an extensive analysis to show how these different set of features can reveal stance. Our findings have distinct privacy implications, where they highlight that stance is strongly embedded in user's online social network that, in principle, individuals can be profiled from their interactions and connections even when they do not post about the topic.