 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisibility Constrained Generative Model for Depth-based 3D Facial Pose Tracking
May 06, 2019
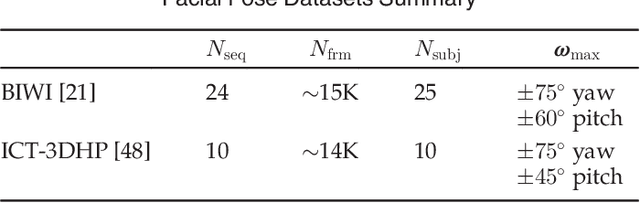
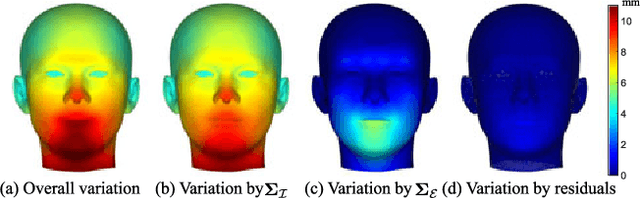

In this paper, we propose a generative framework that unifies depth-based 3D facial pose tracking and face model adaptation on-the-fly, in the unconstrained scenarios with heavy occlusions and arbitrary facial expression variations. Specifically, we introduce a statistical 3D morphable model that flexibly describes the distribution of points on the surface of the face model, with an efficient switchable online adaptation that gradually captures the identity of the tracked subject and rapidly constructs a suitable face model when the subject changes. Moreover, unlike prior art that employed ICP-based facial pose estimation, to improve robustness to occlusions, we propose a ray visibility constraint that regularizes the pose based on the face model's visibility with respect to the input point cloud. Ablation studies and experimental results on Biwi and ICT-3DHP datasets demonstrate that the proposed framework is effective and outperforms completing state-of-the-art depth-based methods.
Unsupervised Visual Domain Adaptation: A Deep Max-Margin Gaussian Process Approach
Feb 23, 2019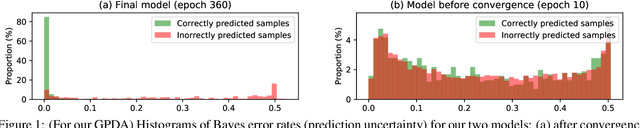
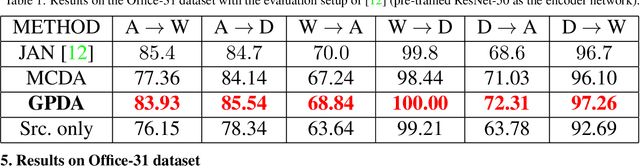
In unsupervised domain adaptation, it is widely known that the target domain error can be provably reduced by having a shared input representation that makes the source and target domains indistinguishable from each other. Very recently it has been studied that not just matching the marginal input distributions, but the alignment of output (class) distributions is also critical. The latter can be achieved by minimizing the maximum discrepancy of predictors (classifiers). In this paper, we adopt this principle, but propose a more systematic and effective way to achieve hypothesis consistency via Gaussian processes (GP). The GP allows us to define/induce a hypothesis space of the classifiers from the posterior distribution of the latent random functions, turning the learning into a simple large-margin posterior separation problem, far easier to solve than previous approaches based on adversarial minimax optimization. We formulate a learning objective that effectively pushes the posterior to minimize the maximum discrepancy. This is further shown to be equivalent to maximizing margins and minimizing uncertainty of the class predictions in the target domain, a well-established principle in classical (semi-)supervised learning. Empirical results demonstrate that our approach is comparable or superior to the existing methods on several benchmark domain adaptation datasets.
Relevance Factor VAE: Learning and Identifying Disentangled Factors
Feb 05, 2019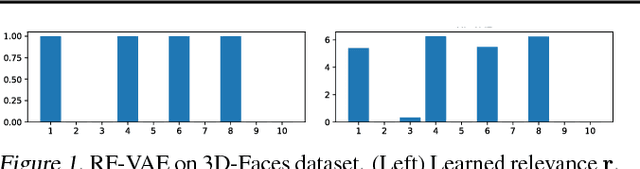
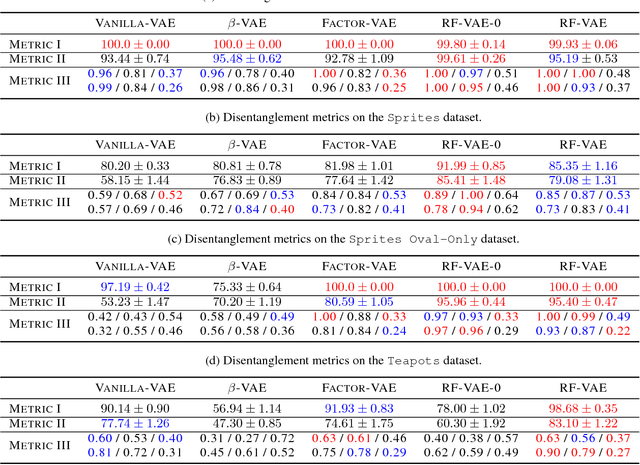

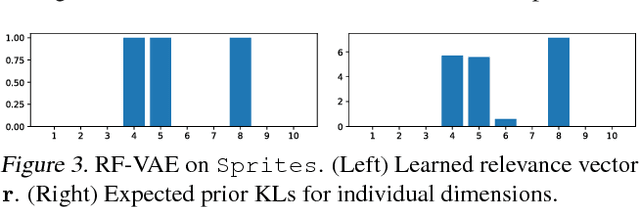
We propose a novel VAE-based deep auto-encoder model that can learn disentangled latent representations in a fully unsupervised manner, endowed with the ability to identify all meaningful sources of variation and their cardinality. Our model, dubbed Relevance-Factor-VAE, leverages the total correlation (TC) in the latent space to achieve the disentanglement goal, but also addresses the key issue of existing approaches which cannot distinguish between meaningful and nuisance factors of latent variation, often the source of considerable degradation in disentanglement performance. We tackle this issue by introducing the so-called relevance indicator variables that can be automatically learned from data, together with the VAE parameters. Our model effectively focuses the TC loss onto the relevant factors only by tolerating large prior KL divergences, a desideratum justified by our semi-parametric theoretical analysis. Using a suite of disentanglement metrics, including a newly proposed one, as well as qualitative evidence, we demonstrate that our model outperforms existing methods across several challenging benchmark datasets.
Unsupervised Multi-Target Domain Adaptation: An Information Theoretic Approach
Oct 26, 2018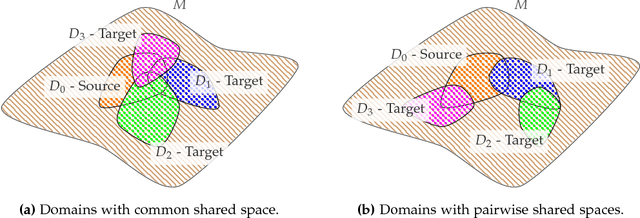
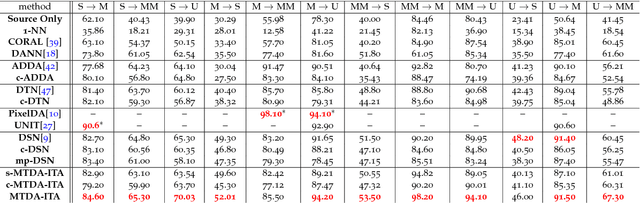
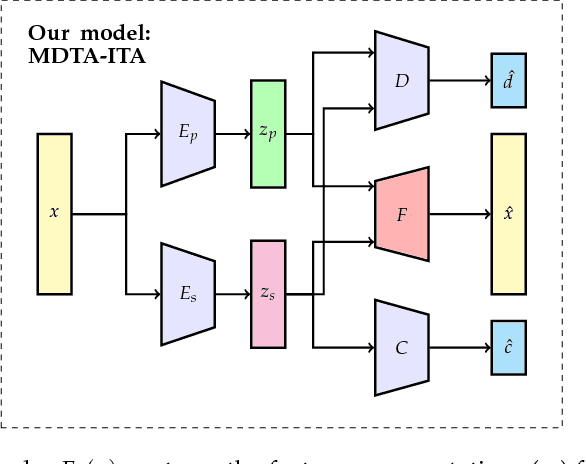
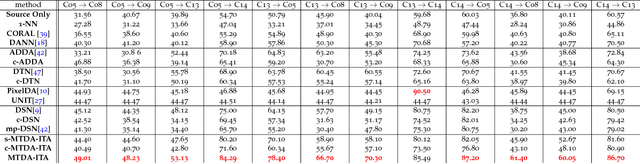
Unsupervised domain adaptation (uDA) models focus on pairwise adaptation settings where there is a single, labeled, source and a single target domain. However, in many real-world settings one seeks to adapt to multiple, but somewhat similar, target domains. Applying pairwise adaptation approaches to this setting may be suboptimal, as they fail to leverage shared information among multiple domains. In this work we propose an information theoretic approach for domain adaptation in the novel context of multiple target domains with unlabeled instances and one source domain with labeled instances. Our model aims to find a shared latent space common to all domains, while simultaneously accounting for the remaining private, domain-specific factors. Disentanglement of shared and private information is accomplished using a unified information-theoretic approach, which also serves to establish a stronger link between the latent representations and the observed data. The resulting model, accompanied by an efficient optimization algorithm, allows simultaneous adaptation from a single source to multiple target domains. We test our approach on three challenging publicly-available datasets, showing that it outperforms several popular domain adaptation methods.
Sketch-Based Face Editing in Videos Using Identity Deformation Transfer
May 31, 2018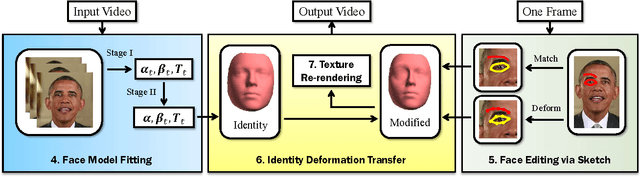
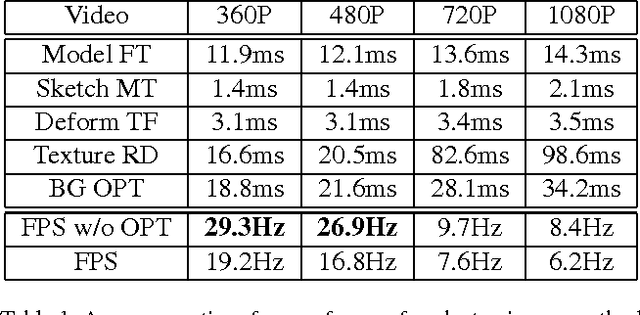
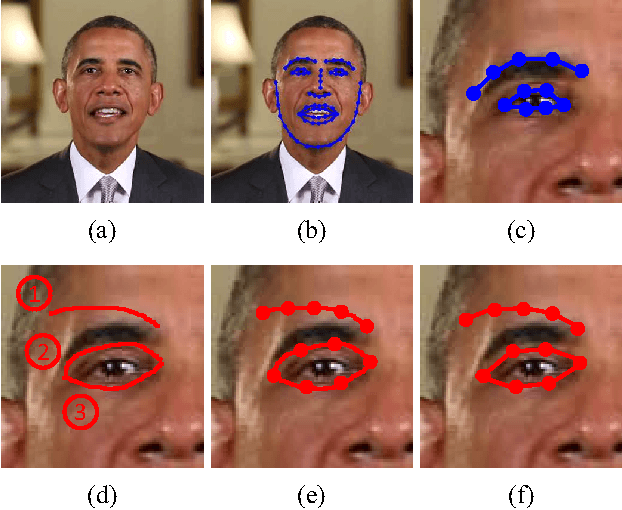

We address the problem of using hand-drawn sketches to edit the facial identity, such as enlarging the shape or modifying the position of eyes or mouth, in the entire video. This task is formulated as a 3D face model reconstruction and deformation problem. We first introduce a two-stage real-time 3D face model fitting schema to recover the facial identity and expressions from the video. User's editing intention is recognized from input sketches as a set of facial modifications. Then a novel identity deformation algorithm is proposed to transfer these facial deformations from 2D space to the 3D facial identity directly, while preserving the facial expressions. After an optional stage for further refining the 3D face model, these changes are propagated to the whole video with the modified identity. Both the user study and experimental results demonstrate that our sketching framework can help users effectively edit facial identities in videos, while high consistency and fidelity are ensured at the same time.
Generative Adversarial Talking Head: Bringing Portraits to Life with a Weakly Supervised Neural Network
Mar 28, 2018
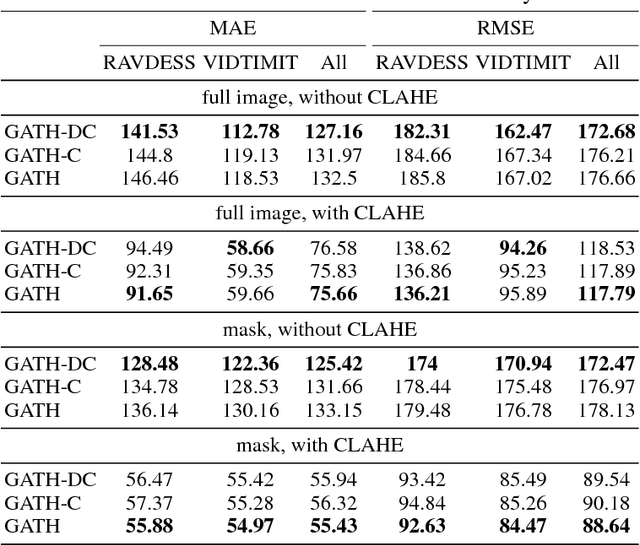
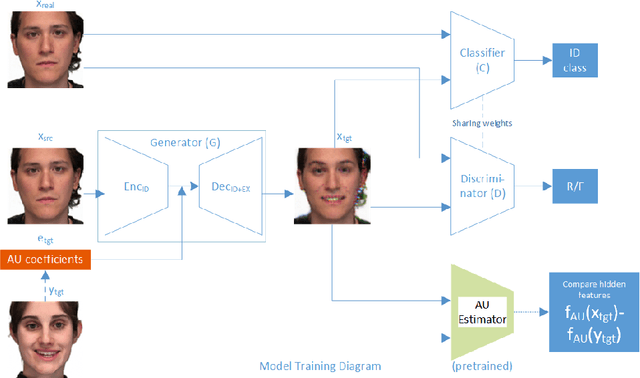

This paper presents Generative Adversarial Talking Head (GATH), a novel deep generative neural network that enables fully automatic facial expression synthesis of an arbitrary portrait with continuous action unit (AU) coefficients. Specifically, our model directly manipulates image pixels to make the unseen subject in the still photo express various emotions controlled by values of facial AU coefficients, while maintaining her personal characteristics, such as facial geometry, skin color and hair style, as well as the original surrounding background. In contrast to prior work, GATH is purely data-driven and it requires neither a statistical face model nor image processing tricks to enact facial deformations. Additionally, our model is trained from unpaired data, where the input image, with its auxiliary identity label taken from abundance of still photos in the wild, and the target frame are from different persons. In order to effectively learn such model, we propose a novel weakly supervised adversarial learning framework that consists of a generator, a discriminator, a classifier and an action unit estimator. Our work gives rise to template-and-target-free expression editing, where still faces can be effortlessly animated with arbitrary AU coefficients provided by the user.
End-to-end Learning for 3D Facial Animation from Raw Waveforms of Speech
Dec 07, 2017
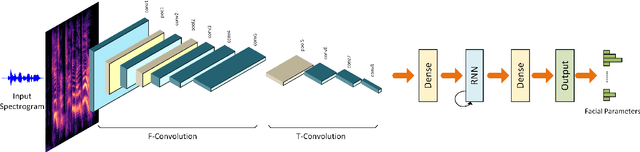

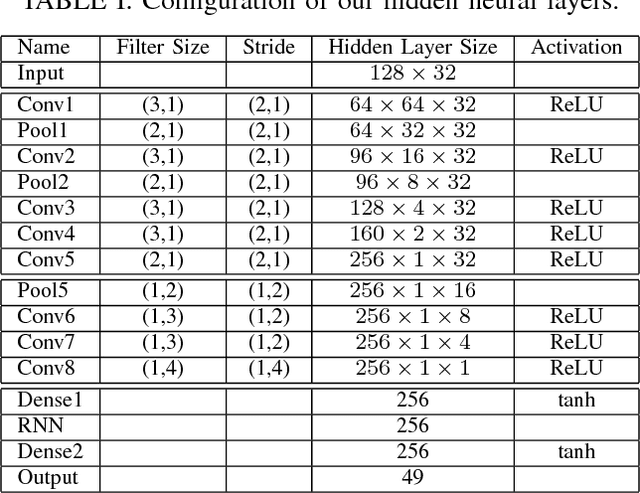
We present a deep learning framework for real-time speech-driven 3D facial animation from just raw waveforms. Our deep neural network directly maps an input sequence of speech audio to a series of micro facial action unit activations and head rotations to drive a 3D blendshape face model. In particular, our deep model is able to learn the latent representations of time-varying contextual information and affective states within the speech. Hence, our model not only activates appropriate facial action units at inference to depict different utterance generating actions, in the form of lip movements, but also, without any assumption, automatically estimates emotional intensity of the speaker and reproduces her ever-changing affective states by adjusting strength of facial unit activations. For example, in a happy speech, the mouth opens wider than normal, while other facial units are relaxed; or in a surprised state, both eyebrows raise higher. Experiments on a diverse audiovisual corpus of different actors across a wide range of emotional states show interesting and promising results of our approach. Being speaker-independent, our generalized model is readily applicable to various tasks in human-machine interaction and animation.
Unsupervised Domain Adaptation with Copula Models
Sep 29, 2017


We study the task of unsupervised domain adaptation, where no labeled data from the target domain is provided during training time. To deal with the potential discrepancy between the source and target distributions, both in features and labels, we exploit a copula-based regression framework. The benefits of this approach are two-fold: (a) it allows us to model a broader range of conditional predictive densities beyond the common exponential family, (b) we show how to leverage Sklar's theorem, the essence of the copula formulation relating the joint density to the copula dependency functions, to find effective feature mappings that mitigate the domain mismatch. By transforming the data to a copula domain, we show on a number of benchmark datasets (including human emotion estimation), and using different regression models for prediction, that we can achieve a more robust and accurate estimation of target labels, compared to recently proposed feature transformation (adaptation) methods.
Robust Time-Series Retrieval Using Probabilistic Adaptive Segmental Alignment
Sep 26, 2016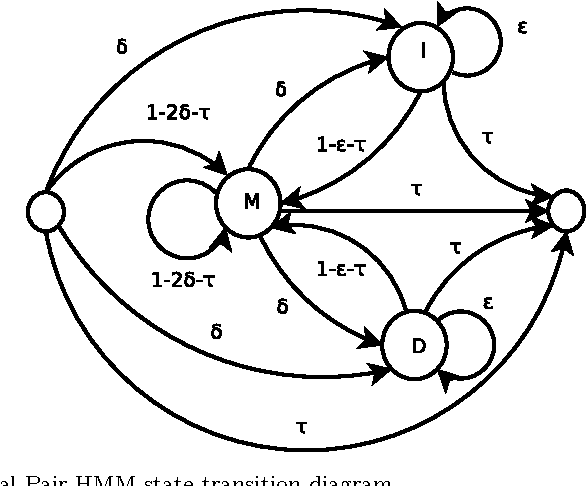

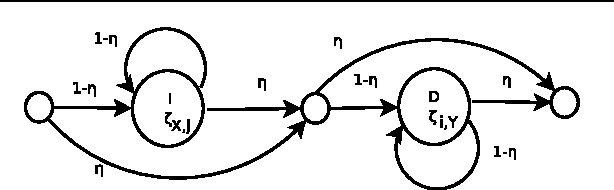
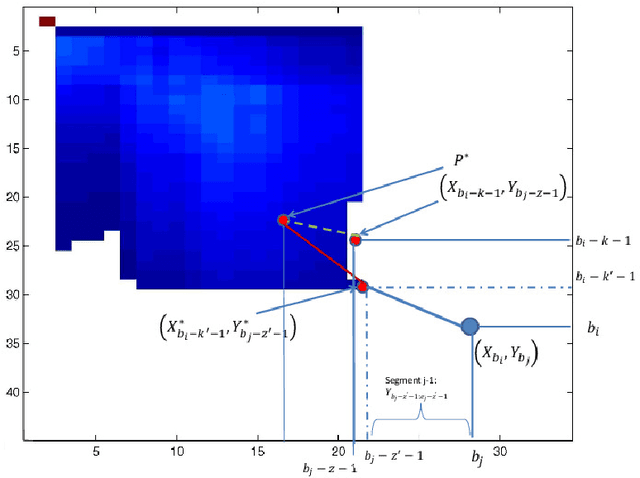
Traditional pairwise sequence alignment is based on matching individual samples from two sequences, under time monotonicity constraints. However, in many application settings matching subsequences (segments) instead of individual samples may bring in additional robustness to noise or local non-causal perturbations. This paper presents an approach to segmental sequence alignment that jointly segments and aligns two sequences, generalizing the traditional per-sample alignment. To accomplish this task, we introduce a distance metric between segments based on average pairwise distances and then present a modified pair-HMM (PHMM) that incorporates the proposed distance metric to solve the joint segmentation and alignment task. We also propose a relaxation to our model that improves the computational efficiency of the generic segmental PHMM. Our results demonstrate that this new measure of sequence similarity can lead to improved classification performance, while being resilient to noise, on a variety of sequence retrieval problems, from EEG to motion sequence classification.
Variable-state Latent Conditional Random Fields for Facial Expression Recognition and Action Unit Detection
Oct 13, 2015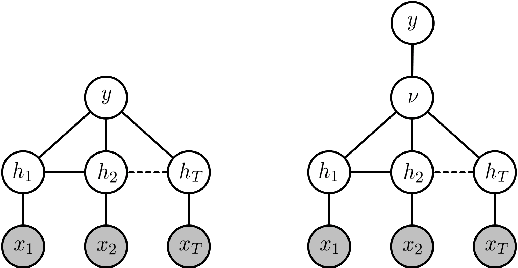

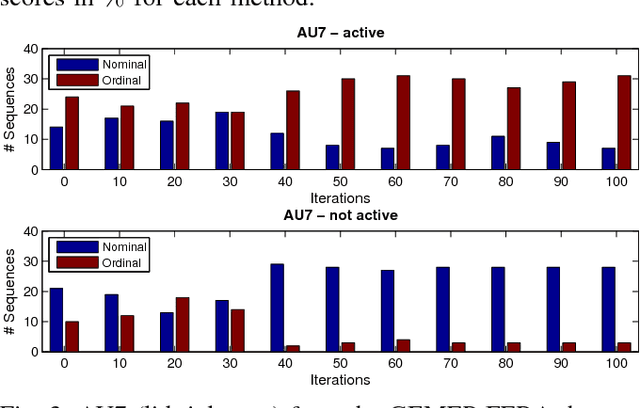
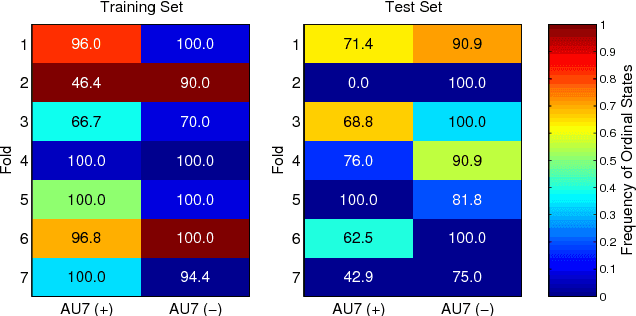
Automated recognition of facial expressions of emotions, and detection of facial action units (AUs), from videos depends critically on modeling of their dynamics. These dynamics are characterized by changes in temporal phases (onset-apex-offset) and intensity of emotion expressions and AUs, the appearance of which may vary considerably among target subjects, making the recognition/detection task very challenging. The state-of-the-art Latent Conditional Random Fields (L-CRF) framework allows one to efficiently encode these dynamics through the latent states accounting for the temporal consistency in emotion expression and ordinal relationships between its intensity levels, these latent states are typically assumed to be either unordered (nominal) or fully ordered (ordinal). Yet, such an approach is often too restrictive. For instance, in the case of AU detection, the goal is to discriminate between the segments of an image sequence in which this AU is active or inactive. While the sequence segments containing activation of the target AU may better be described using ordinal latent states, the inactive segments better be described using unordered (nominal) latent states, as no assumption can be made about their underlying structure (since they can contain either neutral faces or activations of non-target AUs). To address this, we propose the variable-state L-CRF (VSL-CRF) model that automatically selects the optimal latent states for the target image sequence. To reduce the model overfitting either the nominal or ordinal latent states, we propose a novel graph-Laplacian regularization of the latent states. Our experiments on three public expression databases show that the proposed model achieves better generalization performance compared to traditional L-CRFs and other related state-of-the-art models.