 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicture-to-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Oct 17, 2020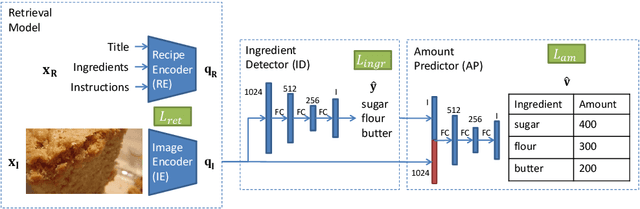
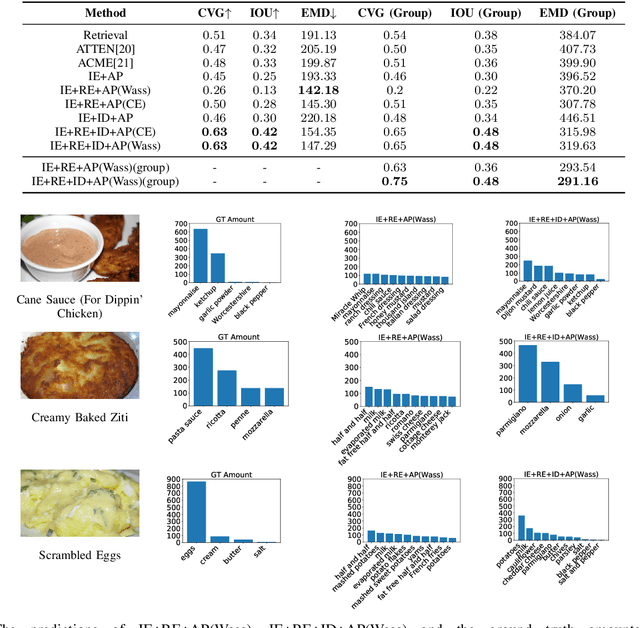

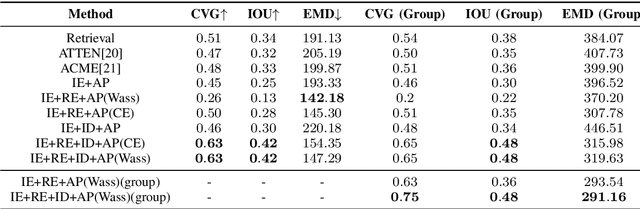
Increased awareness of the impact of food consumption on health and lifestyle today has given rise to novel data-driven food analysis systems. Although these systems may recognize the ingredients, a detailed analysis of their amounts in the meal, which is paramount for estimating the correct nutrition, is usually ignored. In this paper, we study the novel and challenging problem of predicting the relative amount of each ingredient from a food image. We propose PITA, the Picture-to-Amount deep learning architecture to solve the problem. More specifically, we predict the ingredient amounts using a domain-driven Wasserstein loss from image-to-recipe cross-modal embeddings learned to align the two views of food data. Experiments on a dataset of recipes collected from the Internet show the model generates promising results and improves the baselines on this challenging task. A demo of our system and our data is availableat: foodai.cs.rutgers.edu.
Ordinal-Content VAE: Isolating Ordinal-Valued Content Factors in Deep Latent Variable Models
Sep 07, 2020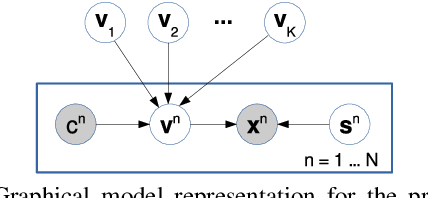
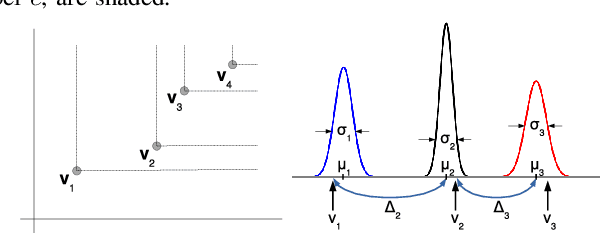
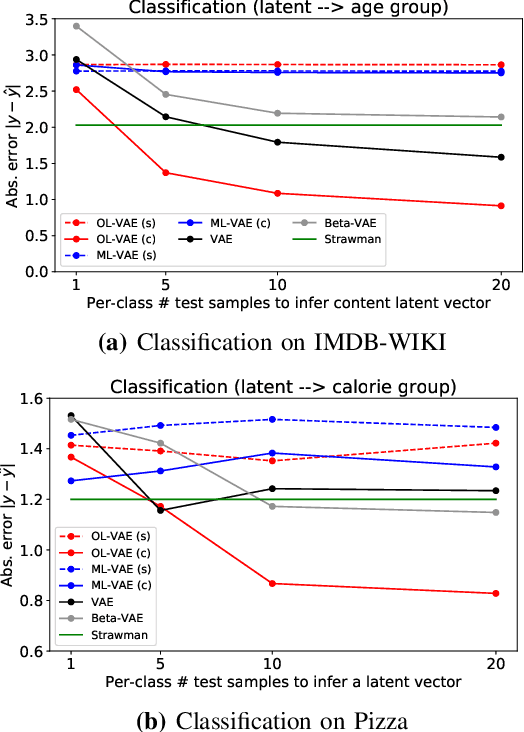
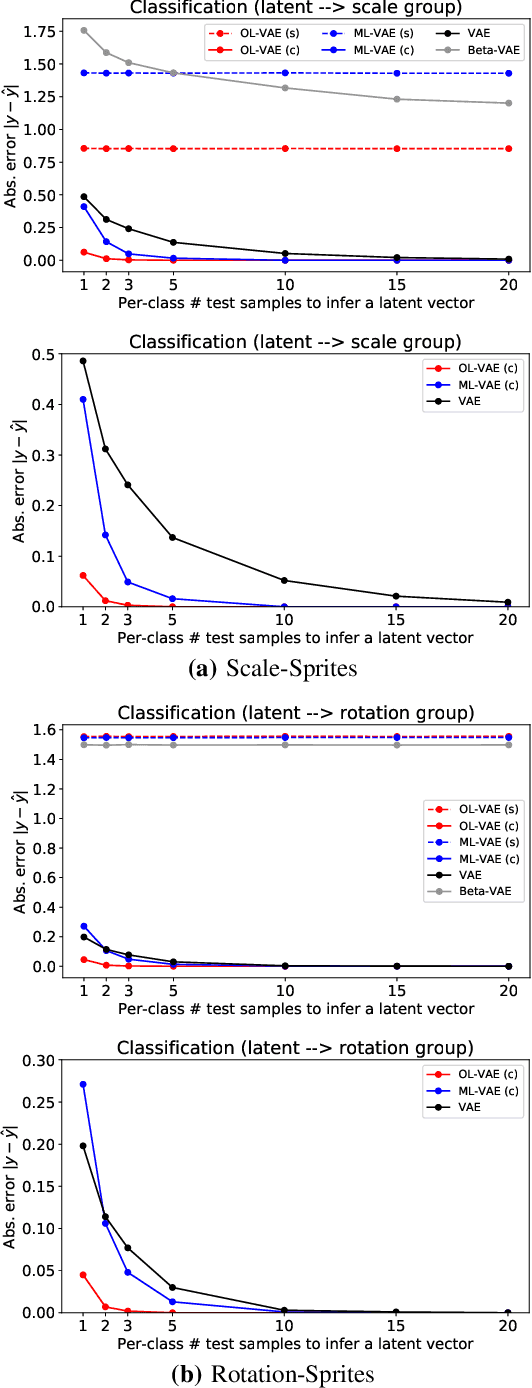
In deep representational learning, it is often desired to isolate a particular factor (termed {\em content}) from other factors (referred to as {\em style}). What constitutes the content is typically specified by users through explicit labels in the data, while all unlabeled/unknown factors are regarded as style. Recently, it has been shown that such content-labeled data can be effectively exploited by modifying the deep latent factor models (e.g., VAE) such that the style and content are well separated in the latent representations. However, the approach assumes that the content factor is categorical-valued (e.g., subject ID in face image data, or digit class in the MNIST dataset). In certain situations, the content is ordinal-valued, that is, the values the content factor takes are {\em ordered} rather than categorical, making content-labeled VAEs, including the latent space they infer, suboptimal. In this paper, we propose a novel extension of VAE that imposes a partially ordered set (poset) structure in the content latent space, while simultaneously making it aligned with the ordinal content values. To this end, instead of the iid Gaussian latent prior adopted in prior approaches, we introduce a conditional Gaussian spacing prior model. This model admits a tractable joint Gaussian prior, but also effectively places negligible density values on the content latent configurations that violate the poset constraint. To evaluate this model, we consider two specific ordinal structured problems: estimating a subject's age in a face image and elucidating the calorie amount in a food meal image. We demonstrate significant improvements in content-style separation over previous non-ordinal approaches.
CookGAN: Meal Image Synthesis from Ingredients
Feb 25, 2020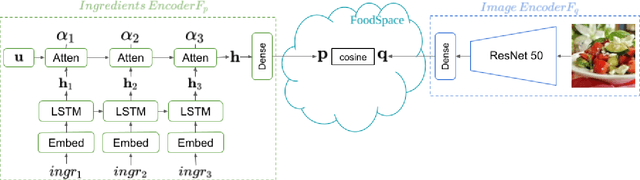
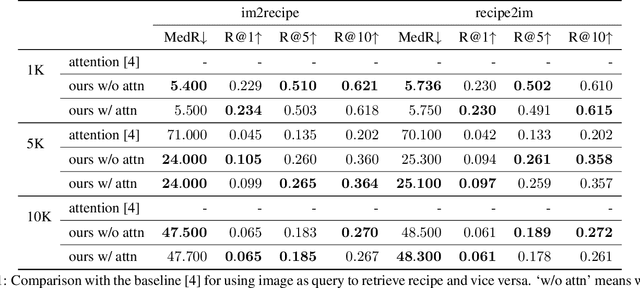
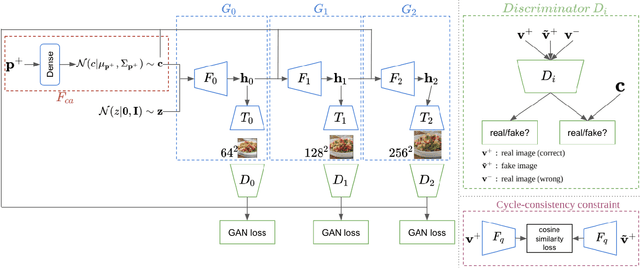
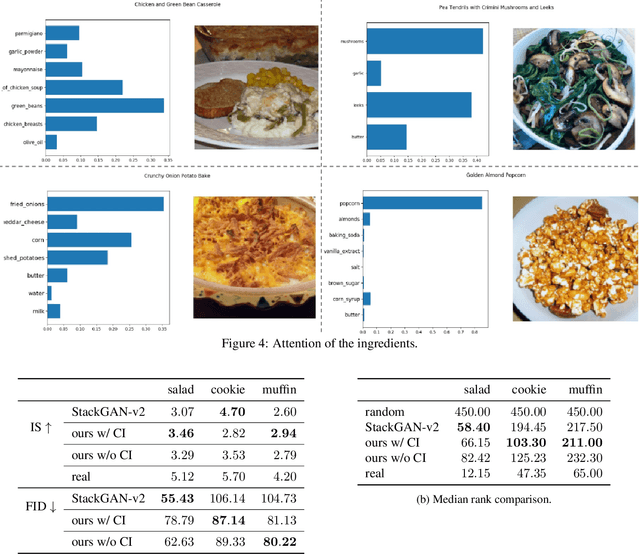
In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual list of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by generative neural networks (GAN) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers, but meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. To generate real-like meal images from ingredients, we propose Cook Generative Adversarial Networks (CookGAN), CookGAN first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Experiments show our model is able to generate meal images corresponding to the ingredients.
Deep Crowd-Flow Prediction in Built Environments
Oct 13, 2019
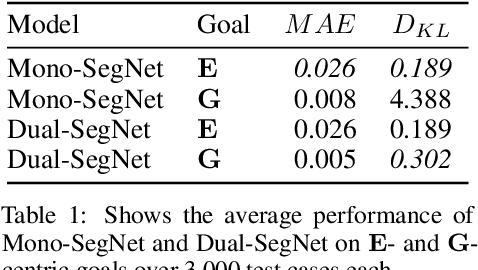
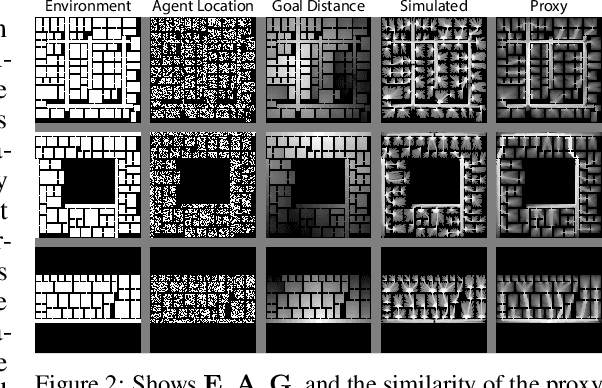
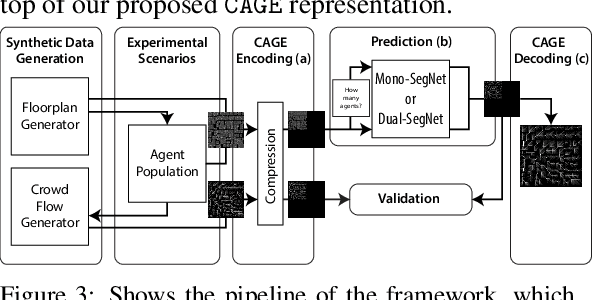
Predicting the behavior of crowds in complex environments is a key requirement in a multitude of application areas, including crowd and disaster management, architectural design, and urban planning. Given a crowd's immediate state, current approaches simulate crowd movement to arrive at a future state. However, most applications require the ability to predict hundreds of possible simulation outcomes (e.g., under different environment and crowd situations) at real-time rates, for which these approaches are prohibitively expensive. In this paper, we propose an approach to instantly predict the long-term flow of crowds in arbitrarily large, realistic environments. Central to our approach is a novel CAGE representation consisting of Capacity, Agent, Goal, and Environment-oriented information, which efficiently encodes and decodes crowd scenarios into compact, fixed-size representations that are environmentally lossless. We present a framework to facilitate the accurate and efficient prediction of crowd flow in never-before-seen crowd scenarios. We conduct a series of experiments to evaluate the efficacy of our approach and showcase positive results.
Task-Discriminative Domain Alignment for Unsupervised Domain Adaptation
Sep 26, 2019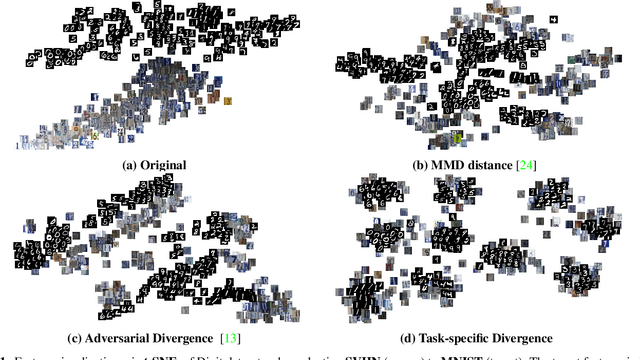
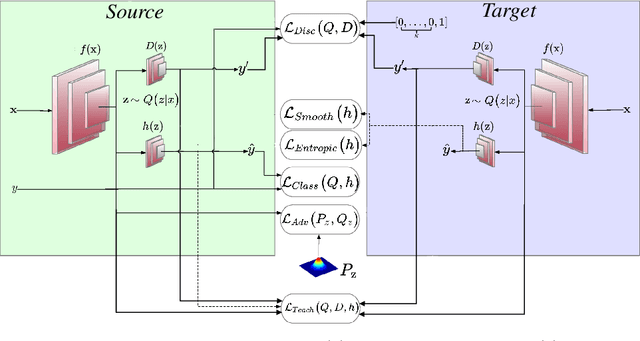

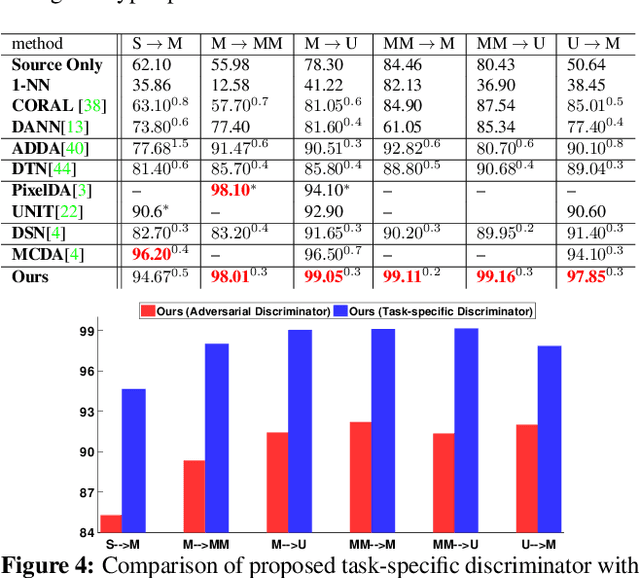
Domain Adaptation (DA), the process of effectively adapting task models learned on one domain, the source, to other related but distinct domains, the targets, with no or minimal retraining, is typically accomplished using the process of source-to-target manifold alignment. However, this process often leads to unsatisfactory adaptation performance, in part because it ignores the task-specific structure of the data. In this paper, we improve the performance of DA by introducing a discriminative discrepancy measure which takes advantage of auxiliary information available in the source and the target domains to better align the source and target distributions. Specifically, we leverage the cohesive clustering structure within individual data manifolds, associated with different tasks, to improve the alignment. This structure is explicit in the source, where the task labels are available, but is implicit in the target, making the problem challenging. We address the challenge by devising a deep DA framework, which combines a new task-driven domain alignment discriminator with domain regularizers that encourage the shared features as task-specific and domain invariant, and prompt the task model to be data structure preserving, guiding its decision boundaries through the low density data regions. We validate our framework on standard benchmarks, including Digits (MNIST, USPS, SVHN, MNIST-M), PACS, and VisDA. Our results show that our proposed model consistently outperforms the state-of-the-art in unsupervised domain adaptation.
Deep Cooking: Predicting Relative Food Ingredient Amounts from Images
Sep 26, 2019



In this paper, we study the novel problem of not only predicting ingredients from a food image, but also predicting the relative amounts of the detected ingredients. We propose two prediction-based models using deep learning that output sparse and dense predictions, coupled with important semi-automatic multi-database integrative data pre-processing, to solve the problem. Experiments on a dataset of recipes collected from the Internet show the models generate encouraging experimental results.
Fast and Effective Adaptation of Facial Action Unit Detection Deep Model
Sep 26, 2019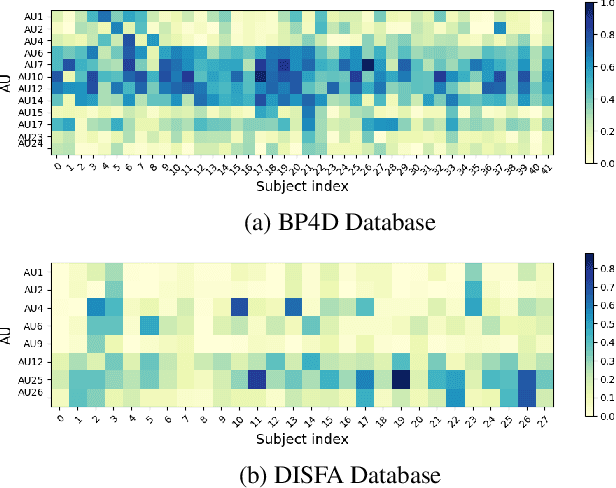
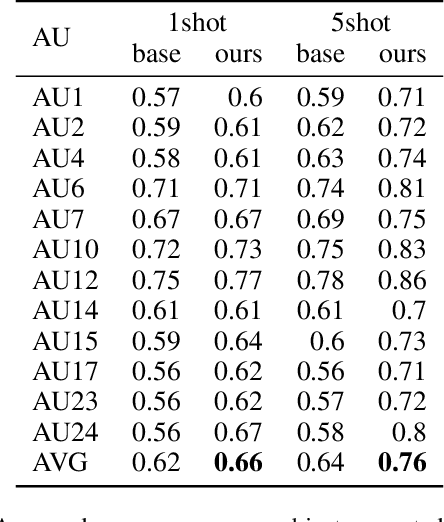
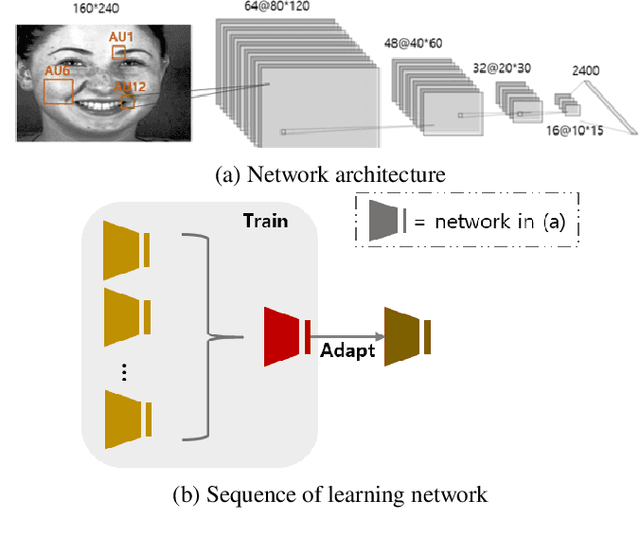
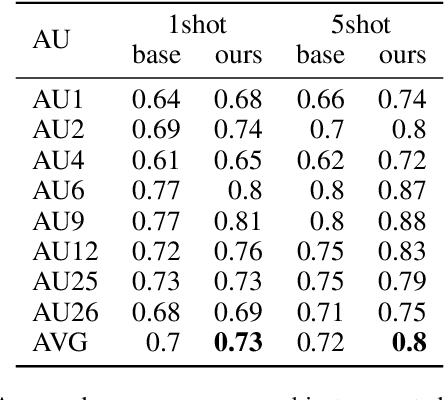
Detecting facial action units (AU) is one of the fundamental steps in automatic recognition of facial expression of emotions and cognitive states. Though there have been a variety of approaches proposed for this task, most of these models are trained only for the specific target AUs, and as such they fail to easily adapt to the task of recognition of new AUs (i.e., those not initially used to train the target models). In this paper, we propose a deep learning approach for facial AU detection that can easily and in a fast manner adapt to a new AU or target subject by leveraging only a few labeled samples from the new task (either an AU or subject). To this end, we propose a modeling approach based on the notion of the model-agnostic meta-learning [C. Finn and Levine, 2017], originally proposed for the general image recognition/detection tasks (e.g., the character recognition from the Omniglot dataset). Specifically, each subject and/or AU is treated as a new learning task and the model learns to adapt based on the knowledge of the previous tasks (the AUs and subjects used to pre-train the target models). Thus, given a new subject or AU, this meta-knowledge (that is shared among training and test tasks) is used to adapt the model to the new task using the notion of deep learning and model-agnostic meta-learning. We show on two benchmark datasets (BP4D and DISFA) for facial AU detection that the proposed approach can be easily adapted to new tasks (AUs/subjects). Using only a few labeled examples from these tasks, the model achieves large improvements over the baselines (i.e., non-adapted models).
Bayes-Factor-VAE: Hierarchical Bayesian Deep Auto-Encoder Models for Factor Disentanglement
Sep 06, 2019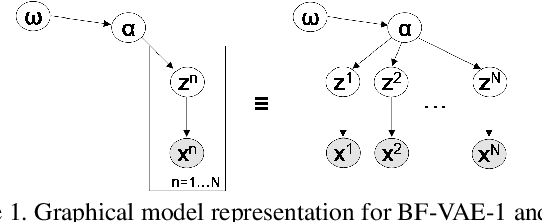
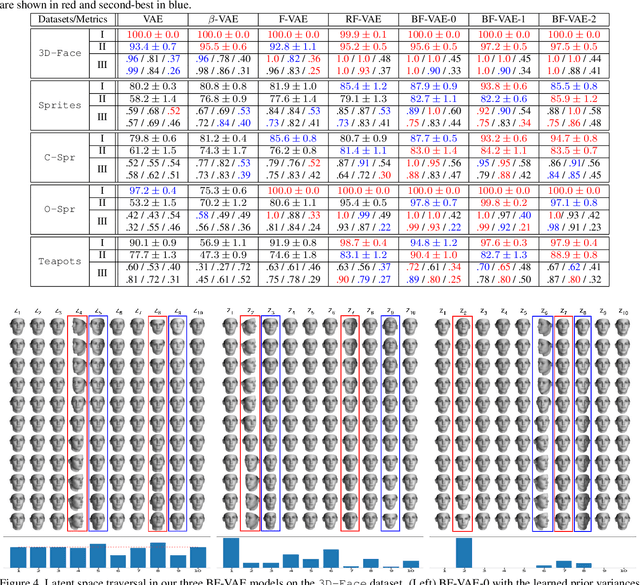
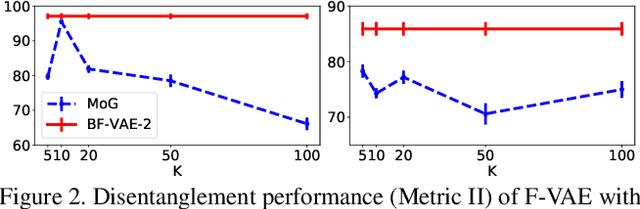

We propose a family of novel hierarchical Bayesian deep auto-encoder models capable of identifying disentangled factors of variability in data. While many recent attempts at factor disentanglement have focused on sophisticated learning objectives within the VAE framework, their choice of a standard normal as the latent factor prior is both suboptimal and detrimental to performance. Our key observation is that the disentangled latent variables responsible for major sources of variability, the relevant factors, can be more appropriately modeled using long-tail distributions. The typical Gaussian priors are, on the other hand, better suited for modeling of nuisance factors. Motivated by this, we extend the VAE to a hierarchical Bayesian model by introducing hyper-priors on the variances of Gaussian latent priors, mimicking an infinite mixture, while maintaining tractable learning and inference of the traditional VAEs. This analysis signifies the importance of partitioning and treating in a different manner the latent dimensions corresponding to relevant factors and nuisances. Our proposed models, dubbed Bayes-Factor-VAEs, are shown to outperform existing methods both quantitatively and qualitatively in terms of latent disentanglement across several challenging benchmark tasks.
Efficient Deep Gaussian Process Models for Variable-Sized Input
May 16, 2019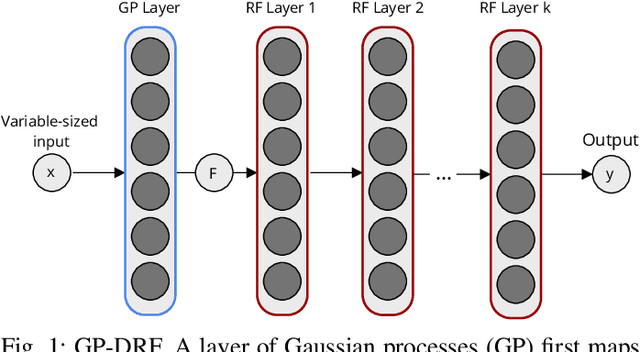
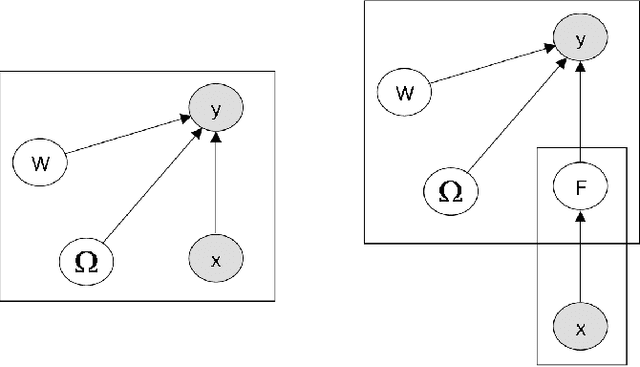
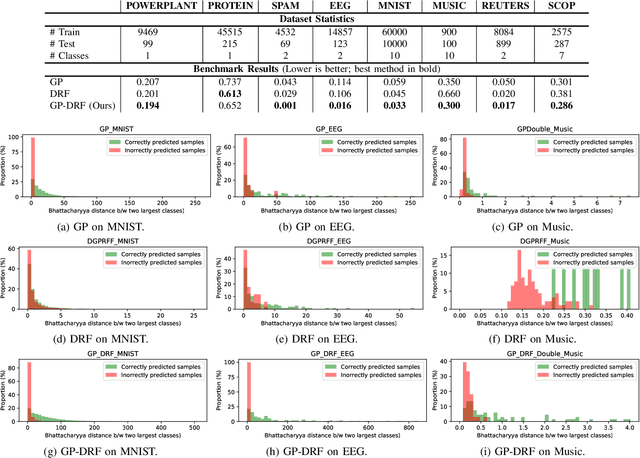

Deep Gaussian processes (DGP) have appealing Bayesian properties, can handle variable-sized data, and learn deep features. Their limitation is that they do not scale well with the size of the data. Existing approaches address this using a deep random feature (DRF) expansion model, which makes inference tractable by approximating DGPs. However, DRF is not suitable for variable-sized input data such as trees, graphs, and sequences. We introduce the GP-DRF, a novel Bayesian model with an input layer of GPs, followed by DRF layers. The key advantage is that the combination of GP and DRF leads to a tractable model that can both handle a variable-sized input as well as learn deep long-range dependency structures of the data. We provide a novel efficient method to simultaneously infer the posterior of GP's latent vectors and infer the posterior of DRF's internal weights and random frequencies. Our experiments show that GP-DRF outperforms the standard GP model and DRF model across many datasets. Furthermore, they demonstrate that GP-DRF enables improved uncertainty quantification compared to GP and DRF alone, with respect to a Bhattacharyya distance assessment. Source code is available at https://github.com/IssamLaradji/GP_DRF.
The Art of Food: Meal Image Synthesis from Ingredients
May 09, 2019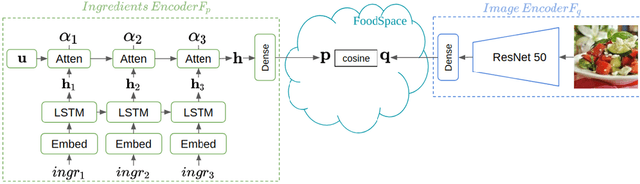
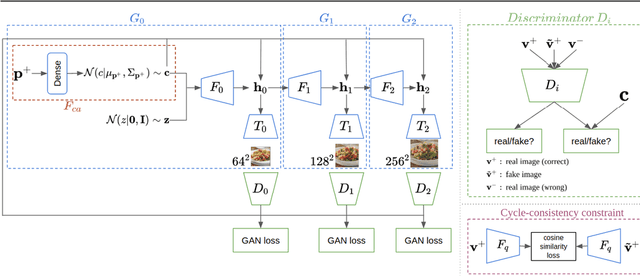


In this work we propose a new computational framework, based on generative deep models, for synthesis of photo-realistic food meal images from textual descriptions of its ingredients. Previous works on synthesis of images from text typically rely on pre-trained text models to extract text features, followed by a generative neural networks (GANs) aimed to generate realistic images conditioned on the text features. These works mainly focus on generating spatially compact and well-defined categories of objects, such as birds or flowers. In contrast, meal images are significantly more complex, consisting of multiple ingredients whose appearance and spatial qualities are further modified by cooking methods. We propose a method that first builds an attention-based ingredients-image association model, which is then used to condition a generative neural network tasked with synthesizing meal images. Furthermore, a cycle-consistent constraint is added to further improve image quality and control appearance. Extensive experiments show our model is able to generate meal image corresponding to the ingredients, which could be used to augment existing dataset for solving other computational food analysis problems.