 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBLP: Phase-Aware Bounded-Loss Transport for Burst-Resilient Distributed ML Training
May 03, 2026Distributed machine learning (ML) training has become a necessity with the prevalence of billion to trillion-parameter-scale models. While prior work has improved training efficiency from the ML perspective at the application layer, it often fails to address transient congestion events at the network layer that introduce severe tail latency and training-time variability, thereby undermining the quality of service (QoS) of distributed ML training systems. Existing network optimizations treat all gradients equally and thus fail to integrate sufficient model-training insights into communication protocol design. In this paper, we present Dynamic Bounded-Loss Protocol (DBLP), a burst-resilient, training-phase-aware, and hardware-agnostic transport protocol that incorporates model-level tolerance properties into gradient communication. By dynamically adjusting gradient loss tolerance across training phases, DBLP reduces overall training time and mitigates tail-latency collapse during transient high-loss events (i.e., microbursts). Compared to the current state-of-the-art solution (baseline), DBLP tolerates significantly higher loss while achieving comparable test accuracy, and reduces end-to-end training time by an average of 24.4% and a maximum of 33.9%. At microburst events, DBLP achieves up to 5.88x single-round communication latency speedups over the baseline, preventing burst-induced tail-latency spikes and maintaining stable training performance.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach
Nov 16, 2016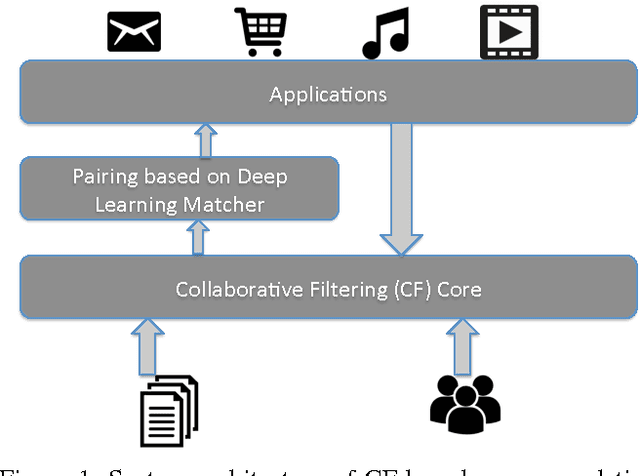
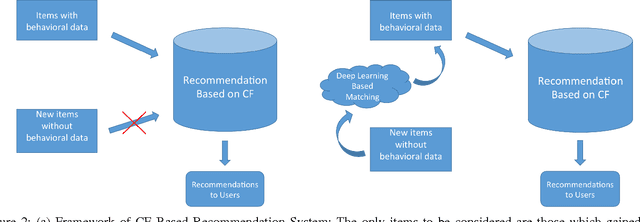
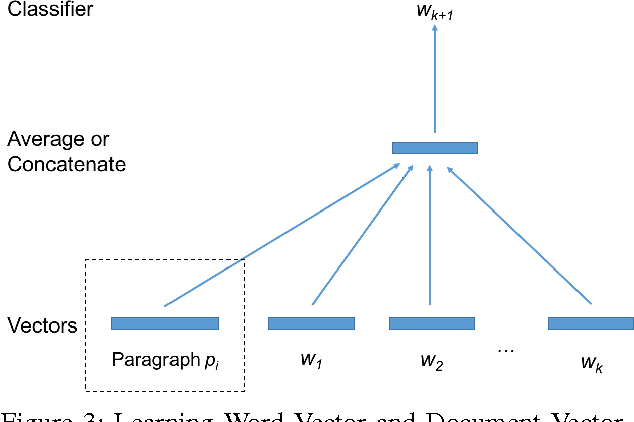
Collaborative Filtering (CF) is widely used in large-scale recommendation engines because of its efficiency, accuracy and scalability. However, in practice, the fact that recommendation engines based on CF require interactions between users and items before making recommendations, make it inappropriate for new items which haven't been exposed to the end users to interact with. This is known as the cold-start problem. In this paper we introduce a novel approach which employs deep learning to tackle this problem in any CF based recommendation engine. One of the most important features of the proposed technique is the fact that it can be applied on top of any existing CF based recommendation engine without changing the CF core. We successfully applied this technique to overcome the item cold-start problem in Careerbuilder's CF based recommendation engine. Our experiments show that the proposed technique is very efficient to resolve the cold-start problem while maintaining high accuracy of the CF recommendations.
A Data-Driven Approach for Semantic Role Labeling from Induced Grammar Structures in Language
Jun 20, 2016
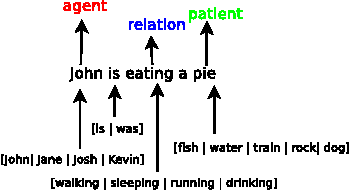
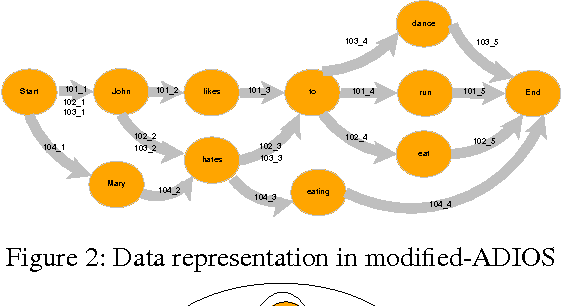

Semantic roles play an important role in extracting knowledge from text. Current unsupervised approaches utilize features from grammar structures, to induce semantic roles. The dependence on these grammars, however, makes it difficult to adapt to noisy and new languages. In this paper we develop a data-driven approach to identifying semantic roles, the approach is entirely unsupervised up to the point where rules need to be learned to identify the position the semantic role occurs. Specifically we develop a modified-ADIOS algorithm based on ADIOS Solan et al. (2005) to learn grammar structures, and use these grammar structures to learn the rules for identifying the semantic roles based on the context in which the grammar structures appeared. The results obtained are comparable with the current state-of-art models that are inherently dependent on human annotated data.
Feature-Weighted Linear Stacking
Nov 04, 2009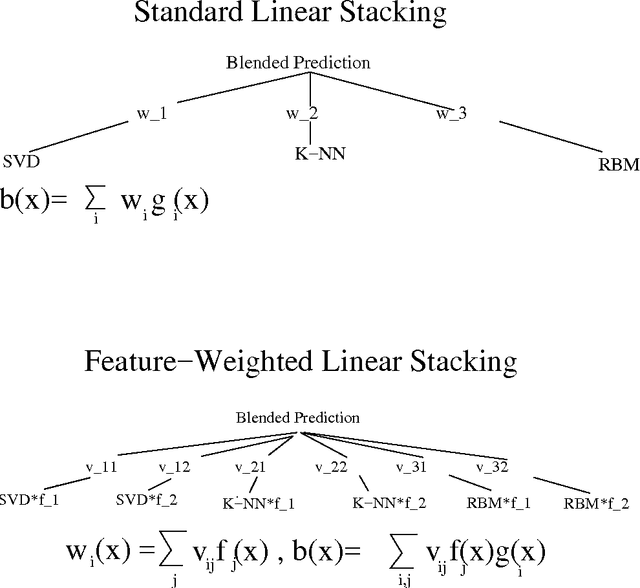
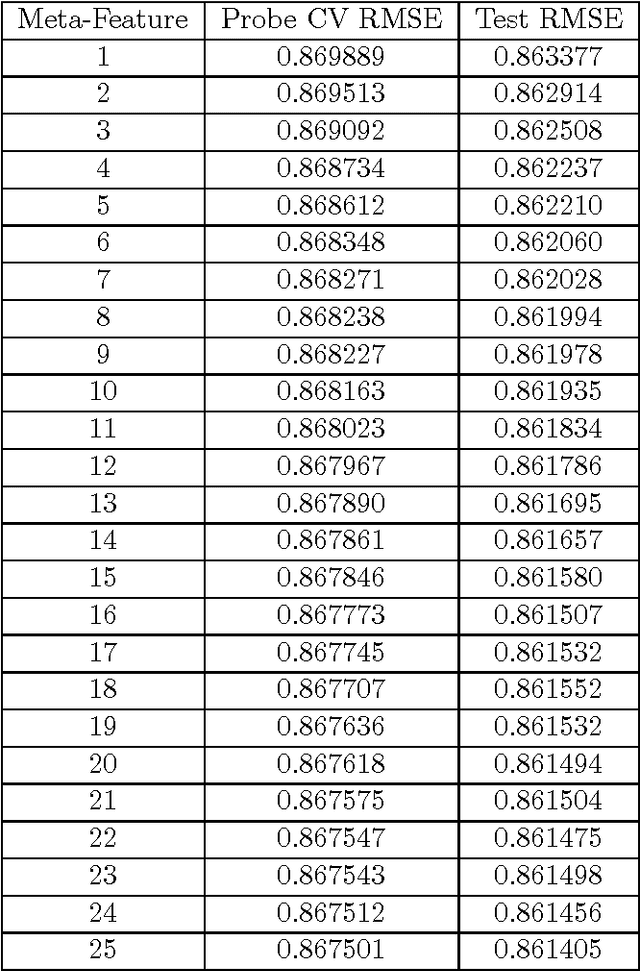
Ensemble methods, such as stacking, are designed to boost predictive accuracy by blending the predictions of multiple machine learning models. Recent work has shown that the use of meta-features, additional inputs describing each example in a dataset, can boost the performance of ensemble methods, but the greatest reported gains have come from nonlinear procedures requiring significant tuning and training time. Here, we present a linear technique, Feature-Weighted Linear Stacking (FWLS), that incorporates meta-features for improved accuracy while retaining the well-known virtues of linear regression regarding speed, stability, and interpretability. FWLS combines model predictions linearly using coefficients that are themselves linear functions of meta-features. This technique was a key facet of the solution of the second place team in the recently concluded Netflix Prize competition. Significant increases in accuracy over standard linear stacking are demonstrated on the Netflix Prize collaborative filtering dataset.