 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate and Reconstruct 3D Meshes with only 2D Supervision
Aug 24, 2018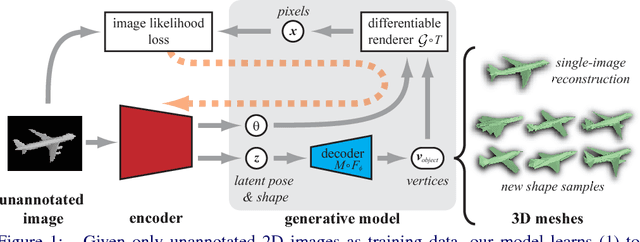
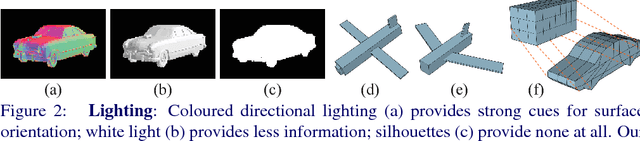


We present a unified framework tackling two problems: class-specific 3D reconstruction from a single image, and generation of new 3D shape samples. These tasks have received considerable attention recently; however, existing approaches rely on 3D supervision, annotation of 2D images with keypoints or poses, and/or training with multiple views of each object instance. Our framework is very general: it can be trained in similar settings to these existing approaches, while also supporting weaker supervision scenarios. Importantly, it can be trained purely from 2D images, without ground-truth pose annotations, and with a single view per instance. We employ meshes as an output representation, instead of voxels used in most prior work. This allows us to exploit shading information during training, which previous 2D-supervised methods cannot. Thus, our method can learn to generate and reconstruct concave object classes. We evaluate our approach on synthetic data in various settings, showing that (i) it learns to disentangle shape from pose; (ii) using shading in the loss improves performance; (iii) our model is comparable or superior to state-of-the-art voxel-based approaches on quantitative metrics, while producing results that are visually more pleasing; (iv) it still performs well when given supervision weaker than in prior works.
Automatic Generation of Constrained Furniture Layouts
Aug 23, 2018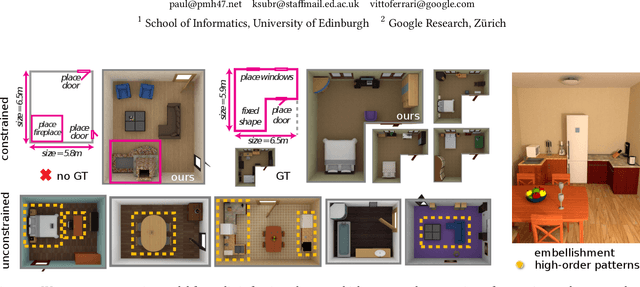
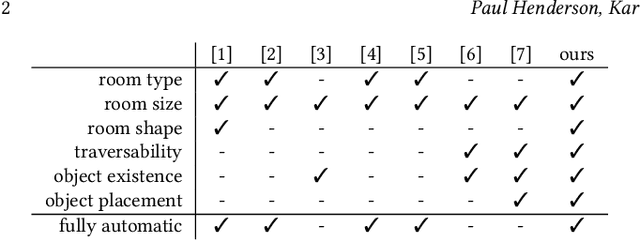
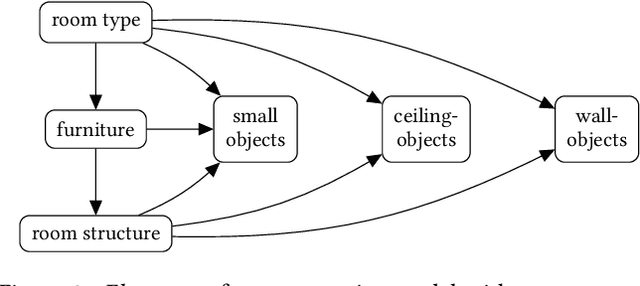
Efficient authoring of vast virtual environments hinges on algorithms that are able to automatically generate content while also being controllable. We propose a method to automatically generate furniture layouts for indoor environments. Our method is simple, efficient, human-interpretable and amenable to a wide variety of constraints. We model the composition of rooms into classes of objects and learn joint (co-occurrence) statistics from a database of training layouts. We generate new layouts by performing a sequence of conditional sampling steps, exploiting the statistics learned from the database. The generated layouts are specified as 3D object models, along with their positions and orientations. We incorporate constraints using a general mechanism -- rejection sampling -- which provides great flexibility at the cost of extra computation. We demonstrate the versatility of our method by accommodating a wide variety of constraints.
Detecting Visual Relationships Using Box Attention
Jul 05, 2018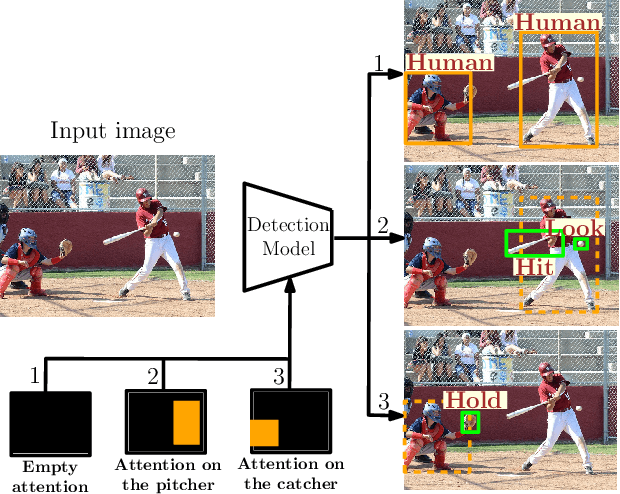
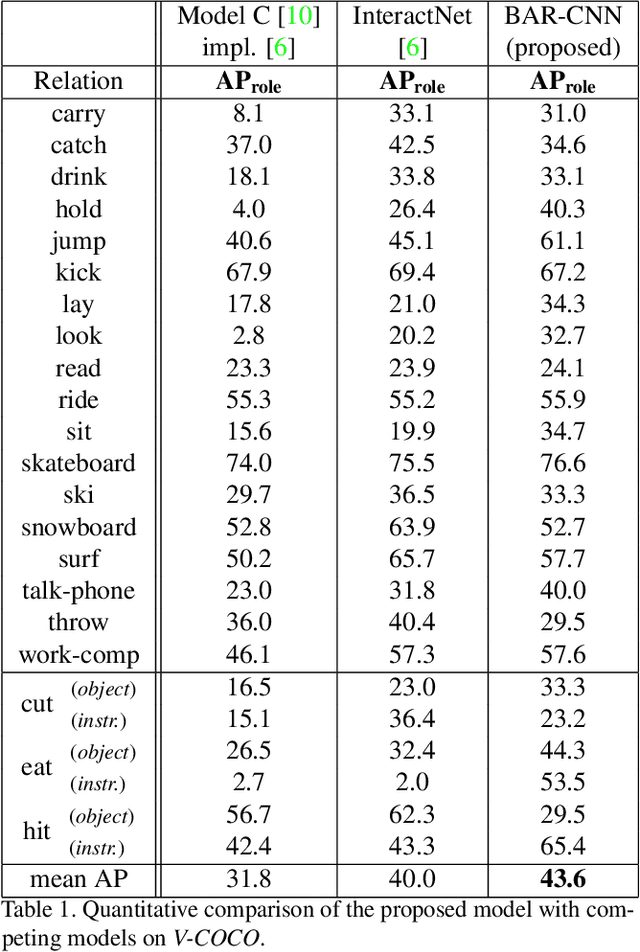

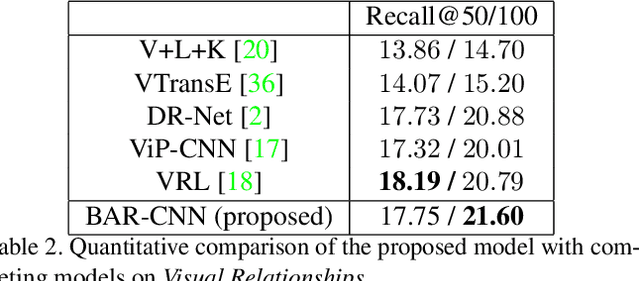
In this paper we propose a new model for detecting visual relationships. Our main technical novelty is a Box Attention mechanism that allows modelling pairwise interactions between objects in visual scenes using standard object detection pipelines. The resulting model is conceptually clean, expressive and relies on well-justified training and prediction procedures. Moreover, unlike previously proposed approaches, our model does not introduce any additional complex components or hyperparameters on top of those already required by the underlying detection model. We conduct an experimental evaluation on two challenging datasets, V-COCO and Visual Relationships, demonstrating strong quantitative and qualitative results.
Learning Intelligent Dialogs for Bounding Box Annotation
Mar 28, 2018
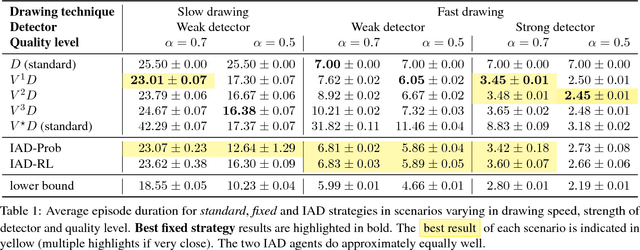
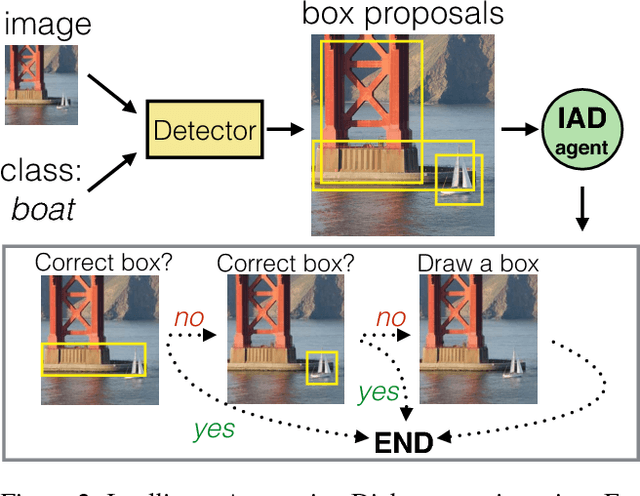
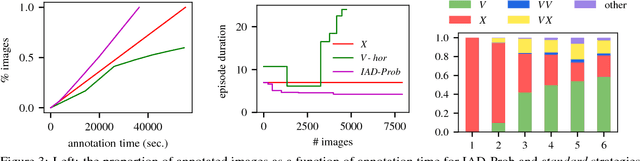
We introduce Intelligent Annotation Dialogs for bounding box annotation. We train an agent to automatically choose a sequence of actions for a human annotator to produce a bounding box in a minimal amount of time. Specifically, we consider two actions: box verification, where the annotator verifies a box generated by an object detector, and manual box drawing. We explore two kinds of agents, one based on predicting the probability that a box will be positively verified, and the other based on reinforcement learning. We demonstrate that (1) our agents are able to learn efficient annotation strategies in several scenarios, automatically adapting to the image difficulty, the desired quality of the boxes, and the detector strength; (2) in all scenarios the resulting annotation dialogs speed up annotation compared to manual box drawing alone and box verification alone, while also outperforming any fixed combination of verification and drawing in most scenarios; (3) in a realistic scenario where the detector is iteratively re-trained, our agents evolve a series of strategies that reflect the shifting trade-off between verification and drawing as the detector grows stronger.
Revisiting knowledge transfer for training object class detectors
Mar 28, 2018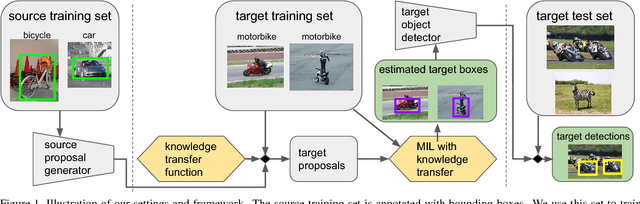

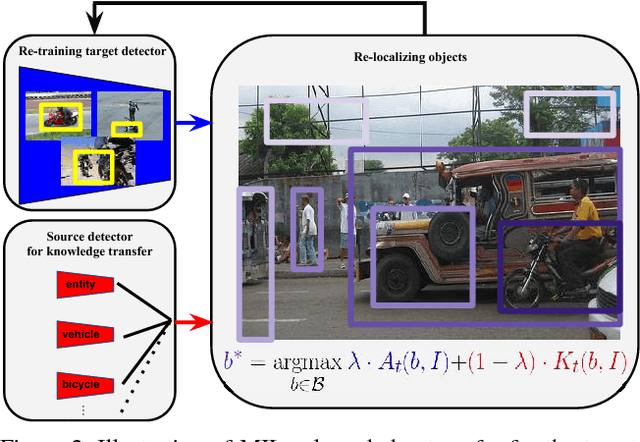
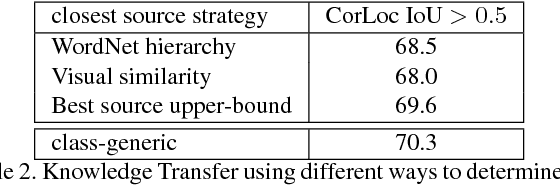
We propose to revisit knowledge transfer for training object detectors on target classes from weakly supervised training images, helped by a set of source classes with bounding-box annotations. We present a unified knowledge transfer framework based on training a single neural network multi-class object detector over all source classes, organized in a semantic hierarchy. This generates proposals with scores at multiple levels in the hierarchy, which we use to explore knowledge transfer over a broad range of generality, ranging from class-specific (bicycle to motorbike) to class-generic (objectness to any class). Experiments on the 200 object classes in the ILSVRC 2013 detection dataset show that our technique: (1) leads to much better performance on the target classes (70.3% CorLoc, 36.9% mAP) than a weakly supervised baseline which uses manually engineered objectness [11] (50.5% CorLoc, 25.4% mAP). (2) delivers target object detectors reaching 80% of the mAP of their fully supervised counterparts. (3) outperforms the best reported transfer learning results on this dataset (+41% CorLoc and +3% mAP over [18, 46], +16.2% mAP over [32]). Moreover, we also carry out several across-dataset knowledge transfer experiments [27, 24, 35] and find that (4) our technique outperforms the weakly supervised baseline in all dataset pairs by 1.5x-1.9x, establishing its general applicability.
COCO-Stuff: Thing and Stuff Classes in Context
Mar 28, 2018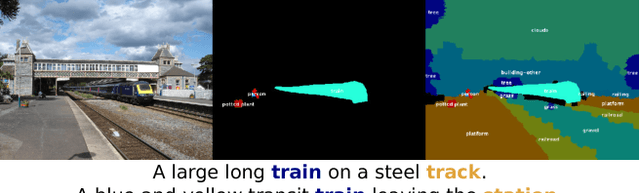
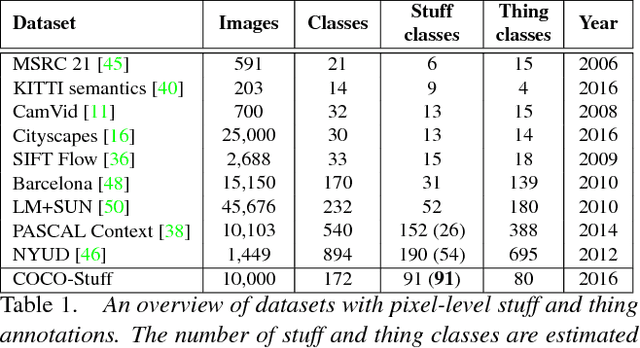

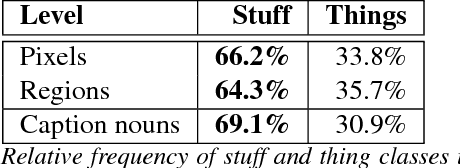
Semantic classes can be either things (objects with a well-defined shape, e.g. car, person) or stuff (amorphous background regions, e.g. grass, sky). While lots of classification and detection works focus on thing classes, less attention has been given to stuff classes. Nonetheless, stuff classes are important as they allow to explain important aspects of an image, including (1) scene type; (2) which thing classes are likely to be present and their location (through contextual reasoning); (3) physical attributes, material types and geometric properties of the scene. To understand stuff and things in context we introduce COCO-Stuff, which augments all 164K images of the COCO 2017 dataset with pixel-wise annotations for 91 stuff classes. We introduce an efficient stuff annotation protocol based on superpixels, which leverages the original thing annotations. We quantify the speed versus quality trade-off of our protocol and explore the relation between annotation time and boundary complexity. Furthermore, we use COCO-Stuff to analyze: (a) the importance of stuff and thing classes in terms of their surface cover and how frequently they are mentioned in image captions; (b) the spatial relations between stuff and things, highlighting the rich contextual relations that make our dataset unique; (c) the performance of a modern semantic segmentation method on stuff and thing classes, and whether stuff is easier to segment than things.
Objects as context for detecting their semantic parts
Mar 27, 2018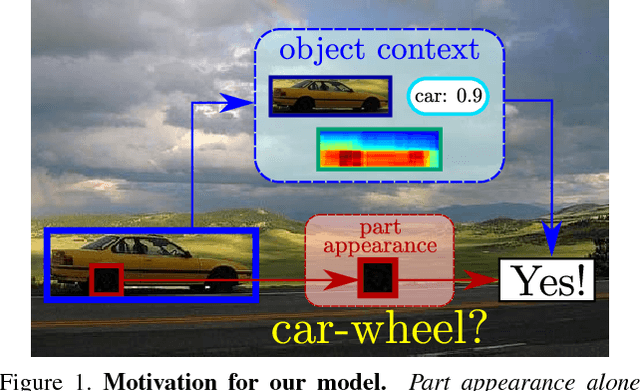
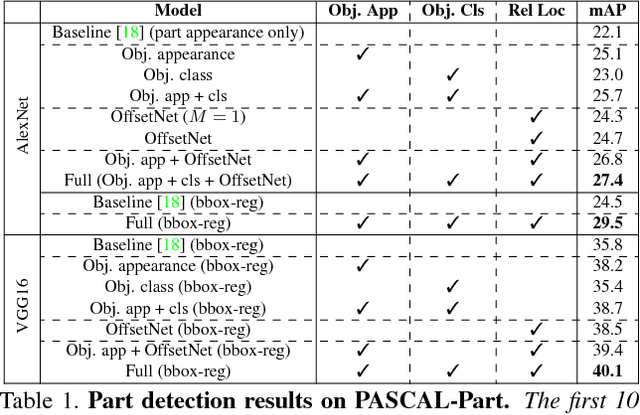
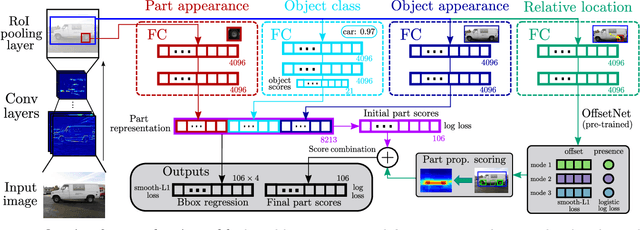
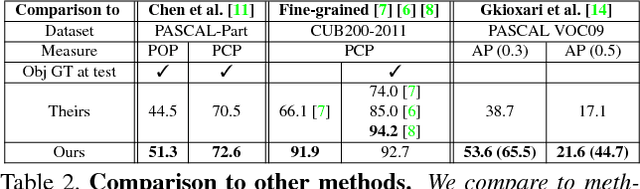
We present a semantic part detection approach that effectively leverages object information.We use the object appearance and its class as indicators of what parts to expect. We also model the expected relative location of parts inside the objects based on their appearance. We achieve this with a new network module, called OffsetNet, that efficiently predicts a variable number of part locations within a given object. Our model incorporates all these cues to detect parts in the context of their objects. This leads to considerably higher performance for the challenging task of part detection compared to using part appearance alone (+5 mAP on the PASCAL-Part dataset). We also compare to other part detection methods on both PASCAL-Part and CUB200-2011 datasets.
Do semantic parts emerge in Convolutional Neural Networks?
Sep 20, 2017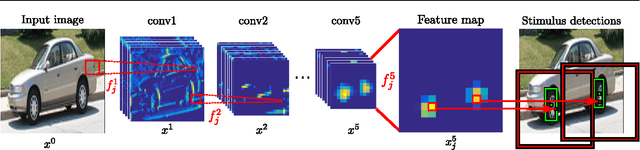
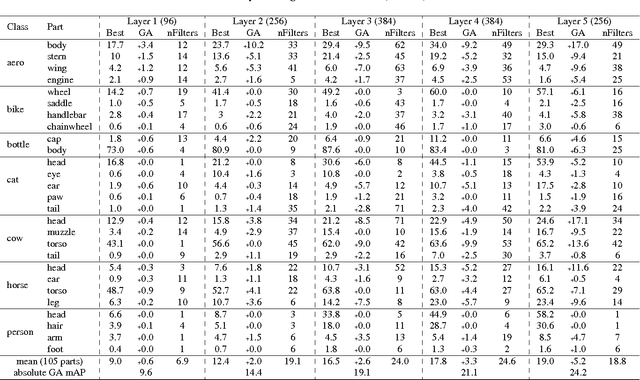

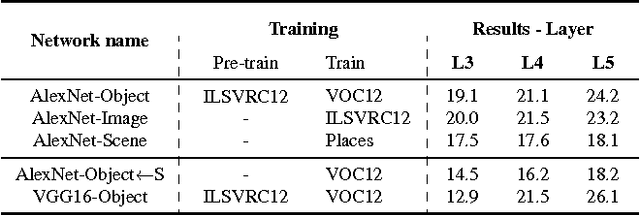
Semantic object parts can be useful for several visual recognition tasks. Lately, these tasks have been addressed using Convolutional Neural Networks (CNN), achieving outstanding results. In this work we study whether CNNs learn semantic parts in their internal representation. We investigate the responses of convolutional filters and try to associate their stimuli with semantic parts. We perform two extensive quantitative analyses. First, we use ground-truth part bounding-boxes from the PASCAL-Part dataset to determine how many of those semantic parts emerge in the CNN. We explore this emergence for different layers, network depths, and supervision levels. Second, we collect human judgements in order to study what fraction of all filters systematically fire on any semantic part, even if not annotated in PASCAL-Part. Moreover, we explore several connections between discriminative power and semantics. We find out which are the most discriminative filters for object recognition, and analyze whether they respond to semantic parts or to other image patches. We also investigate the other direction: we determine which semantic parts are the most discriminative and whether they correspond to those parts emerging in the network. This enables to gain an even deeper understanding of the role of semantic parts in the network.
Action Tubelet Detector for Spatio-Temporal Action Localization
Aug 21, 2017
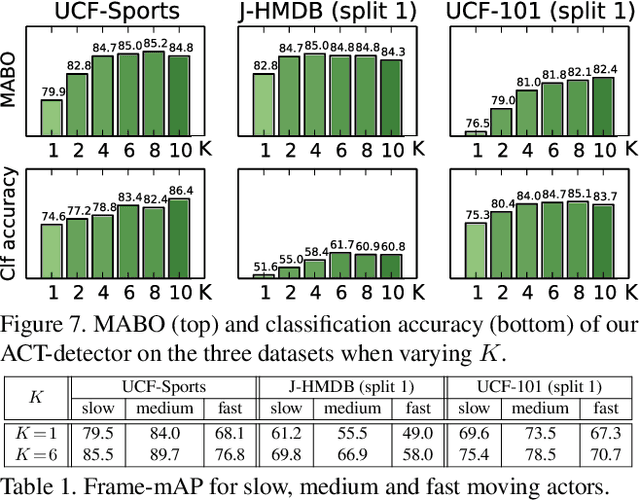

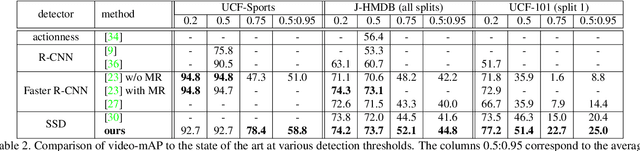
Current state-of-the-art approaches for spatio-temporal action localization rely on detections at the frame level that are then linked or tracked across time. In this paper, we leverage the temporal continuity of videos instead of operating at the frame level. We propose the ACtion Tubelet detector (ACT-detector) that takes as input a sequence of frames and outputs tubelets, i.e., sequences of bounding boxes with associated scores. The same way state-of-the-art object detectors rely on anchor boxes, our ACT-detector is based on anchor cuboids. We build upon the SSD framework. Convolutional features are extracted for each frame, while scores and regressions are based on the temporal stacking of these features, thus exploiting information from a sequence. Our experimental results show that leveraging sequences of frames significantly improves detection performance over using individual frames. The gain of our tubelet detector can be explained by both more accurate scores and more precise localization. Our ACT-detector outperforms the state-of-the-art methods for frame-mAP and video-mAP on the J-HMDB and UCF-101 datasets, in particular at high overlap thresholds.
The Devil is in the Decoder
Aug 12, 2017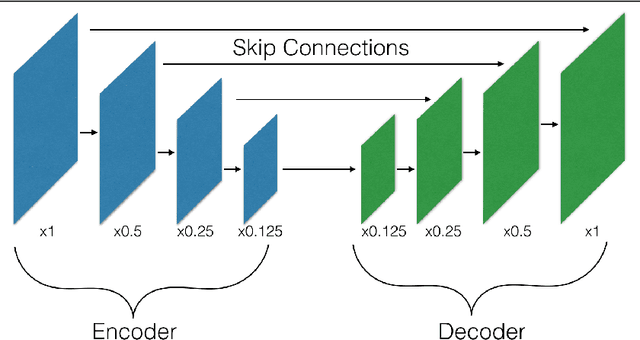

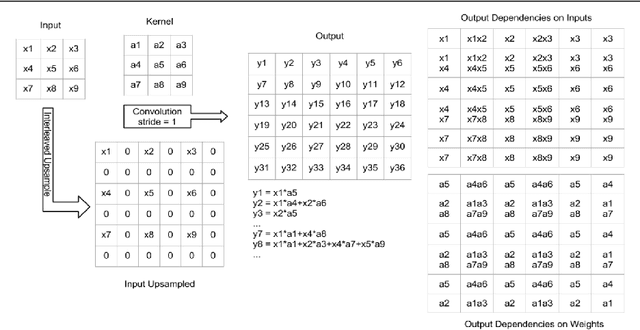
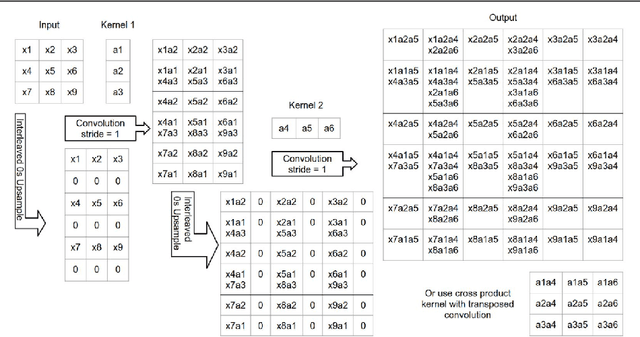
Many machine vision applications require predictions for every pixel of the input image (for example semantic segmentation, boundary detection). Models for such problems usually consist of encoders which decreases spatial resolution while learning a high-dimensional representation, followed by decoders who recover the original input resolution and result in low-dimensional predictions. While encoders have been studied rigorously, relatively few studies address the decoder side. Therefore this paper presents an extensive comparison of a variety of decoders for a variety of pixel-wise prediction tasks. Our contributions are: (1) Decoders matter: we observe significant variance in results between different types of decoders on various problems. (2) We introduce a novel decoder: bilinear additive upsampling. (3) We introduce new residual-like connections for decoders. (4) We identify two decoder types which give a consistently high performance.