 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Adversarial Robustness for Deep Metric Learning
Mar 02, 2022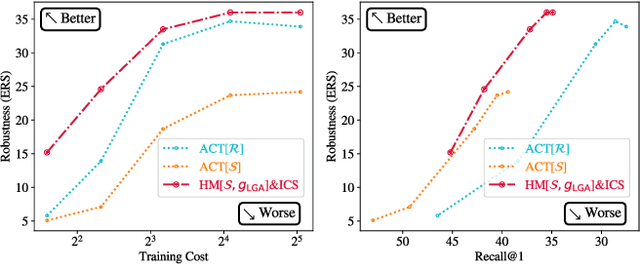


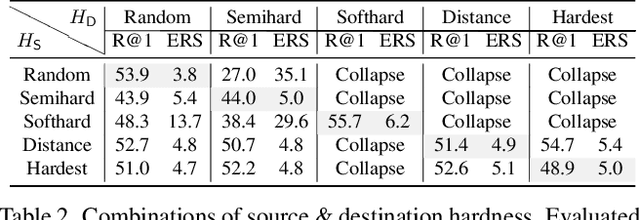
Owing to security implications of adversarial vulnerability, adversarial robustness of deep metric learning models has to be improved. In order to avoid model collapse due to excessively hard examples, the existing defenses dismiss the min-max adversarial training, but instead learn from a weak adversary inefficiently. Conversely, we propose Hardness Manipulation to efficiently perturb the training triplet till a specified level of hardness for adversarial training, according to a harder benign triplet or a pseudo-hardness function. It is flexible since regular training and min-max adversarial training are its boundary cases. Besides, Gradual Adversary, a family of pseudo-hardness functions is proposed to gradually increase the specified hardness level during training for a better balance between performance and robustness. Additionally, an Intra-Class Structure loss term among benign and adversarial examples further improves model robustness and efficiency. Comprehensive experimental results suggest that the proposed method, although simple in its form, overwhelmingly outperforms the state-of-the-art defenses in terms of robustness, training efficiency, as well as performance on benign examples.
Exploring Adversarially Robust Training for Unsupervised Domain Adaptation
Feb 18, 2022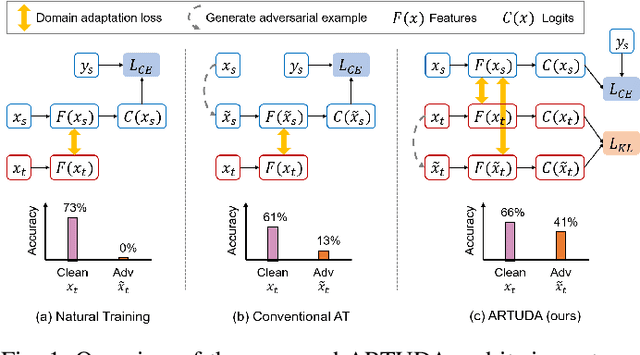
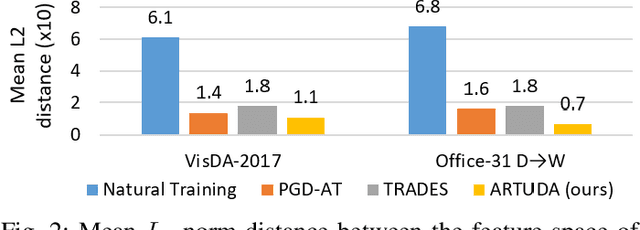
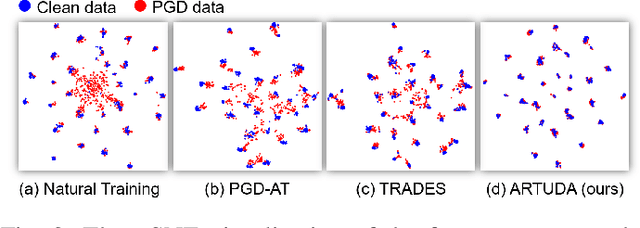
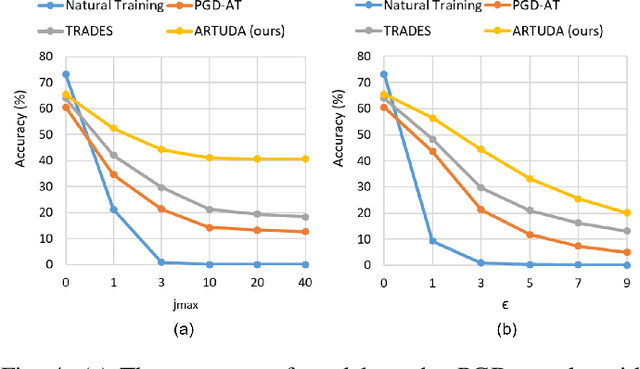
Unsupervised Domain Adaptation (UDA) methods aim to transfer knowledge from a labeled source domain to an unlabeled target domain. UDA has been extensively studied in the computer vision literature. Deep networks have been shown to be vulnerable to adversarial attacks. However, very little focus is devoted to improving the adversarial robustness of deep UDA models, causing serious concerns about model reliability. Adversarial Training (AT) has been considered to be the most successful adversarial defense approach. Nevertheless, conventional AT requires ground-truth labels to generate adversarial examples and train models, which limits its effectiveness in the unlabeled target domain. In this paper, we aim to explore AT to robustify UDA models: How to enhance the unlabeled data robustness via AT while learning domain-invariant features for UDA? To answer this, we provide a systematic study into multiple AT variants that potentially apply to UDA. Moreover, we propose a novel Adversarially Robust Training method for UDA accordingly, referred to as ARTUDA. Extensive experiments on multiple attacks and benchmarks show that ARTUDA consistently improves the adversarial robustness of UDA models.
Open-set Adversarial Defense with Clean-Adversarial Mutual Learning
Feb 12, 2022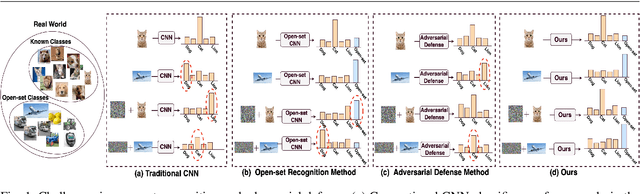

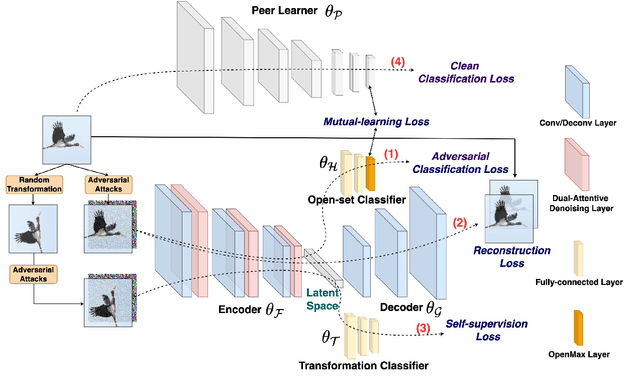
Open-set recognition and adversarial defense study two key aspects of deep learning that are vital for real-world deployment. The objective of open-set recognition is to identify samples from open-set classes during testing, while adversarial defense aims to robustify the network against images perturbed by imperceptible adversarial noise. This paper demonstrates that open-set recognition systems are vulnerable to adversarial samples. Furthermore, this paper shows that adversarial defense mechanisms trained on known classes are unable to generalize well to open-set samples. Motivated by these observations, we emphasize the necessity of an Open-Set Adversarial Defense (OSAD) mechanism. This paper proposes an Open-Set Defense Network with Clean-Adversarial Mutual Learning (OSDN-CAML) as a solution to the OSAD problem. The proposed network designs an encoder with dual-attentive feature-denoising layers coupled with a classifier to learn a noise-free latent feature representation, which adaptively removes adversarial noise guided by channel and spatial-wise attentive filters. Several techniques are exploited to learn a noise-free and informative latent feature space with the aim of improving the performance of adversarial defense and open-set recognition. First, we incorporate a decoder to ensure that clean images can be well reconstructed from the obtained latent features. Then, self-supervision is used to ensure that the latent features are informative enough to carry out an auxiliary task. Finally, to exploit more complementary knowledge from clean image classification to facilitate feature denoising and search for a more generalized local minimum for open-set recognition, we further propose clean-adversarial mutual learning, where a peer network (classifying clean images) is further introduced to mutually learn with the classifier (classifying adversarial images).
ReconFormer: Accelerated MRI Reconstruction Using Recurrent Transformer
Jan 28, 2022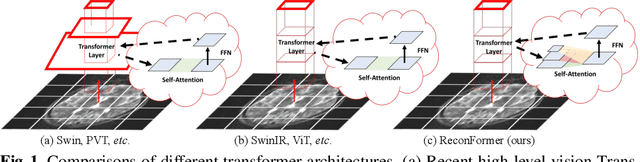
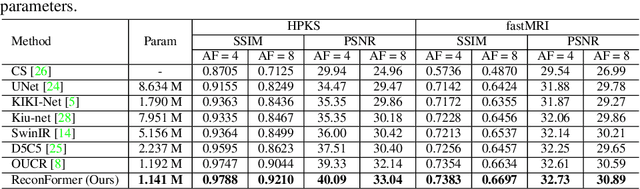
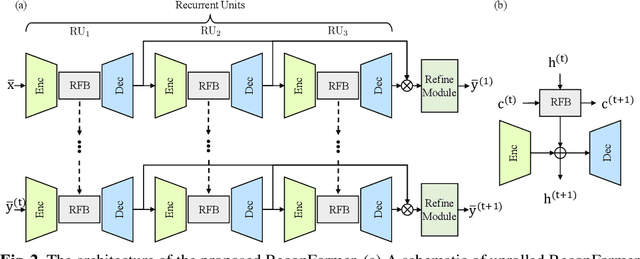
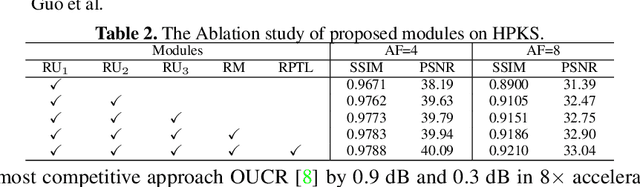
Accelerating magnetic resonance image (MRI) reconstruction process is a challenging ill-posed inverse problem due to the excessive under-sampling operation in k-space. In this paper, we propose a recurrent transformer model, namely ReconFormer, for MRI reconstruction which can iteratively reconstruct high fertility magnetic resonance images from highly under-sampled k-space data. In particular, the proposed architecture is built upon Recurrent Pyramid Transformer Layers (RPTL), which jointly exploits intrinsic multi-scale information at every architecture unit as well as the dependencies of the deep feature correlation through recurrent states. Moreover, the proposed ReconFormer is lightweight since it employs the recurrent structure for its parameter efficiency. We validate the effectiveness of ReconFormer on multiple datasets with different magnetic resonance sequences and show that it achieves significant improvements over the state-of-the-art methods with better parameter efficiency. Implementation code will be available in https://github.com/guopengf/ReconFormer.
Transformer-based SAR Image Despeckling
Jan 23, 2022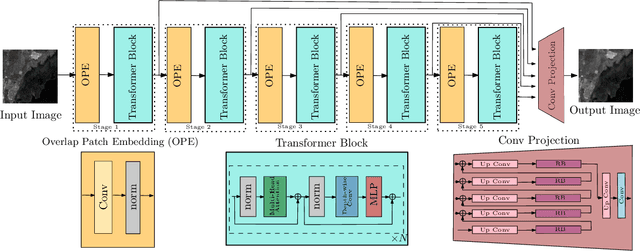
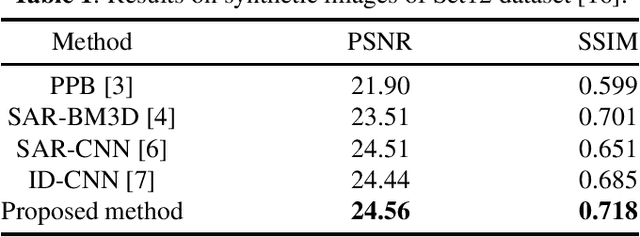
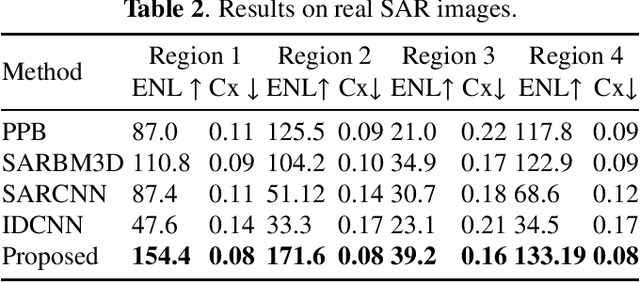
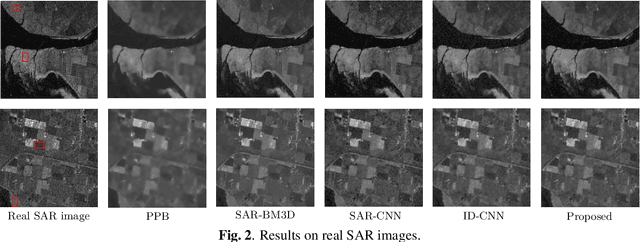
Synthetic Aperture Radar (SAR) images are usually degraded by a multiplicative noise known as speckle which makes processing and interpretation of SAR images difficult. In this paper, we introduce a transformer-based network for SAR image despeckling. The proposed despeckling network comprises of a transformer-based encoder which allows the network to learn global dependencies between different image regions - aiding in better despeckling. The network is trained end-to-end with synthetically generated speckled images using a composite loss function. Experiments show that the proposed method achieves significant improvements over traditional and convolutional neural network-based despeckling methods on both synthetic and real SAR images.
A Transformer-Based Siamese Network for Change Detection
Jan 15, 2022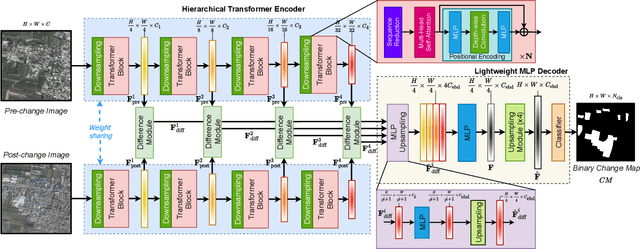
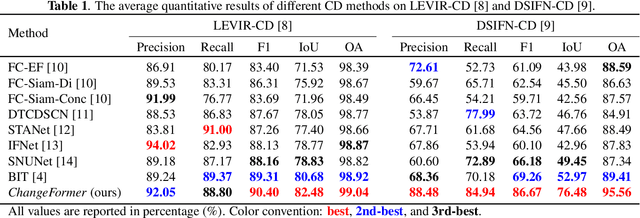
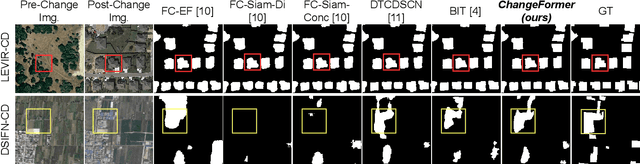
This paper presents a transformer-based Siamese network architecture (abbreviated by ChangeFormer) for Change Detection (CD) from a pair of co-registered remote sensing images. Different from recent CD frameworks, which are based on fully convolutional networks (ConvNets), the proposed method unifies hierarchically structured transformer encoder with Multi-Layer Perception (MLP) decoder in a Siamese network architecture to efficiently render multi-scale long-range details required for accurate CD. Experiments on two CD datasets show that the proposed end-to-end trainable ChangeFormer architecture achieves better CD performance than previous counterparts. Our code is available at https://github.com/wgcban/ChangeFormer.
LTT-GAN: Looking Through Turbulence by Inverting GANs
Dec 04, 2021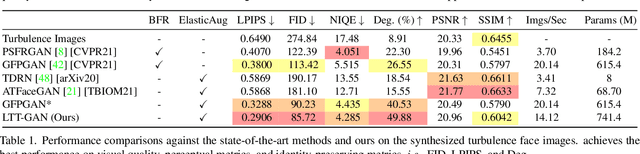
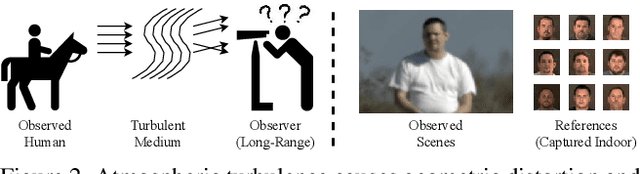
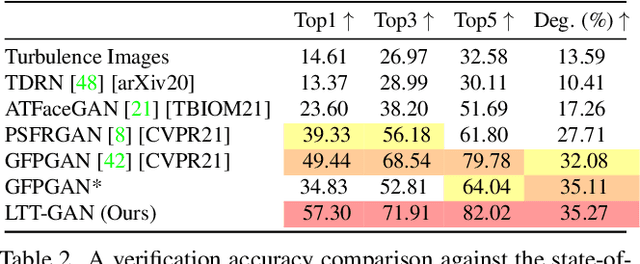
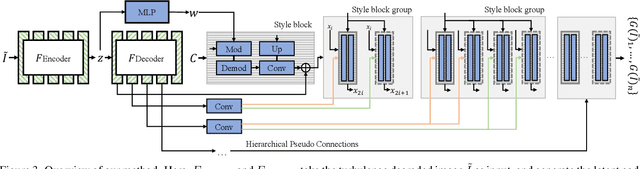
In many applications of long-range imaging, we are faced with a scenario where a person appearing in the captured imagery is often degraded by atmospheric turbulence. However, restoring such degraded images for face verification is difficult since the degradation causes images to be geometrically distorted and blurry. To mitigate the turbulence effect, in this paper, we propose the first turbulence mitigation method that makes use of visual priors encapsulated by a well-trained GAN. Based on the visual priors, we propose to learn to preserve the identity of restored images on a spatial periodic contextual distance. Such a distance can keep the realism of restored images from the GAN while considering the identity difference at the network learning. In addition, hierarchical pseudo connections are proposed for facilitating the identity-preserving learning by introducing more appearance variance without identity changing. Extensive experiments show that our method significantly outperforms prior art in both the visual quality and face verification accuracy of restored results.
Attentive Prototypes for Source-free Unsupervised Domain Adaptive 3D Object Detection
Dec 01, 2021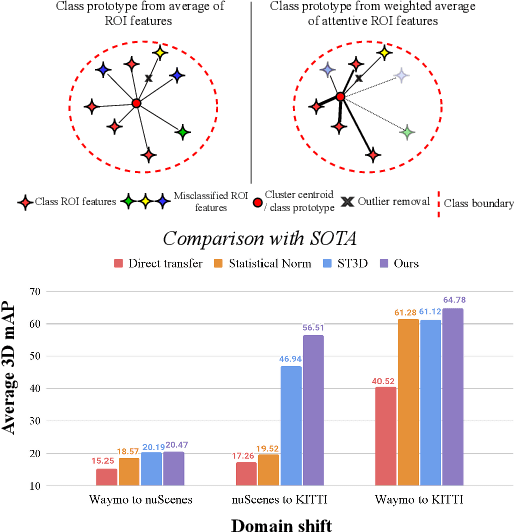
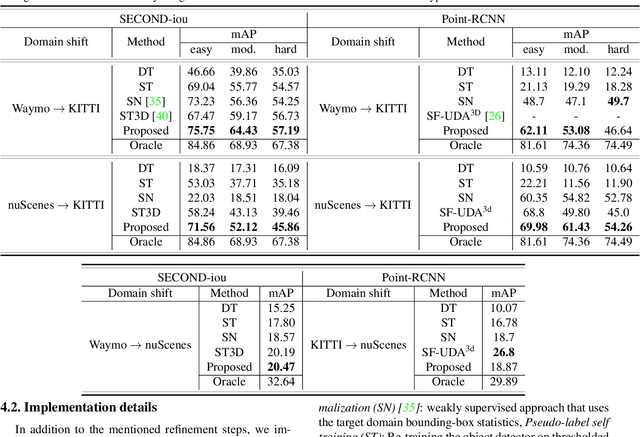
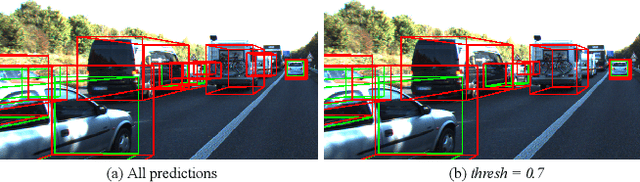
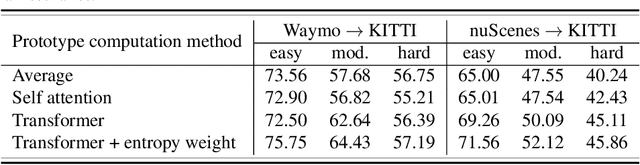
3D object detection networks tend to be biased towards the data they are trained on. Evaluation on datasets captured in different locations, conditions or sensors than that of the training (source) data results in a drop in model performance due to the gap in distribution with the test (or target) data. Current methods for domain adaptation either assume access to source data during training, which may not be available due to privacy or memory concerns, or require a sequence of lidar frames as an input. We propose a single-frame approach for source-free, unsupervised domain adaptation of lidar-based 3D object detectors that uses class prototypes to mitigate the effect pseudo-label noise. Addressing the limitations of traditional feature aggregation methods for prototype computation in the presence of noisy labels, we utilize a transformer module to identify outlier ROI's that correspond to incorrect, over-confident annotations, and compute an attentive class prototype. Under an iterative training strategy, the losses associated with noisy pseudo labels are down-weighed and thus refined in the process of self-training. To validate the effectiveness of our proposed approach, we examine the domain shift associated with networks trained on large, label-rich datasets (such as the Waymo Open Dataset and nuScenes) and evaluate on smaller, label-poor datasets (such as KITTI) and vice-versa. We demonstrate our approach on two recent object detectors and achieve results that out-perform the other domain adaptation works.
SketchEdit: Mask-Free Local Image Manipulation with Partial Sketches
Nov 30, 2021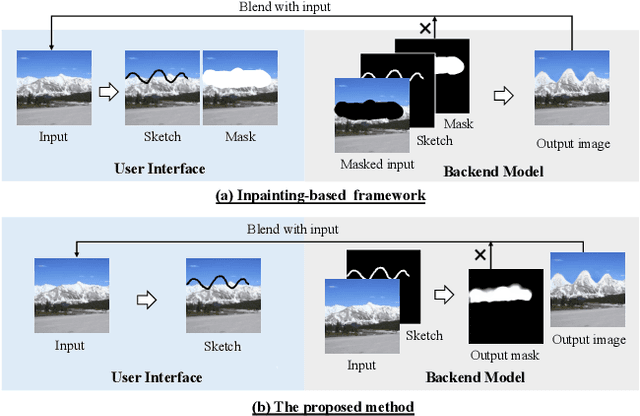
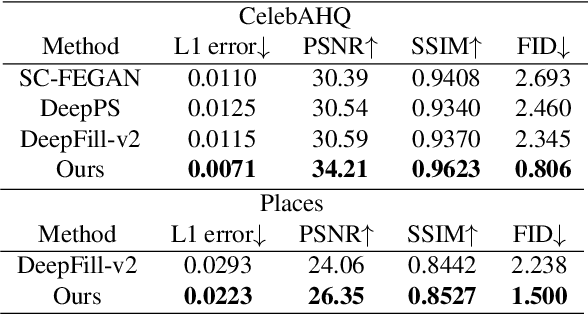
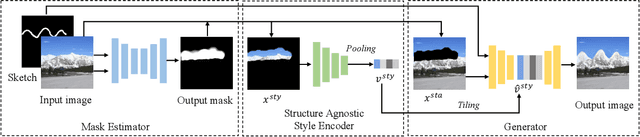
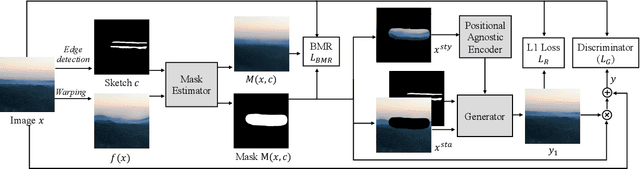
Sketch-based image manipulation is an interactive image editing task to modify an image based on input sketches from users. Existing methods typically formulate this task as a conditional inpainting problem, which requires users to draw an extra mask indicating the region to modify in addition to sketches. The masked regions are regarded as holes and filled by an inpainting model conditioned on the sketch. With this formulation, paired training data can be easily obtained by randomly creating masks and extracting edges or contours. Although this setup simplifies data preparation and model design, it complicates user interaction and discards useful information in masked regions. To this end, we investigate a new paradigm of sketch-based image manipulation: mask-free local image manipulation, which only requires sketch inputs from users and utilizes the entire original image. Given an image and sketch, our model automatically predicts the target modification region and encodes it into a structure agnostic style vector. A generator then synthesizes the new image content based on the style vector and sketch. The manipulated image is finally produced by blending the generator output into the modification region of the original image. Our model can be trained in a self-supervised fashion by learning the reconstruction of an image region from the style vector and sketch. The proposed method offers simpler and more intuitive user workflows for sketch-based image manipulation and provides better results than previous approaches. More results, code and interactive demo will be available at \url{https://zengxianyu.github.io/sketchedit}.
TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions
Nov 29, 2021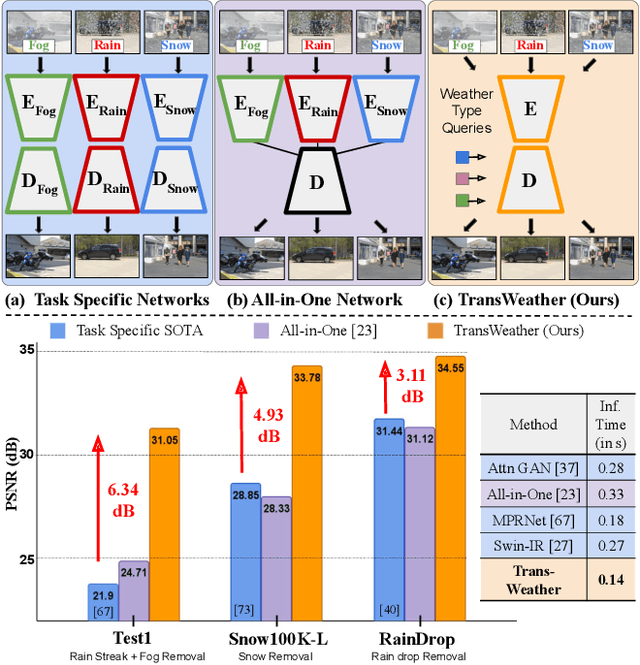
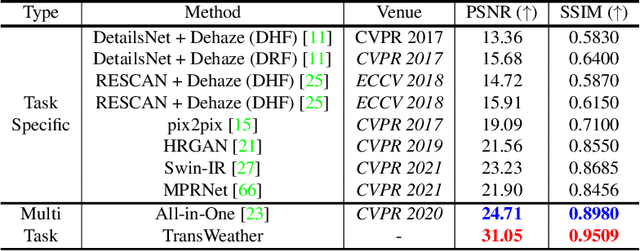
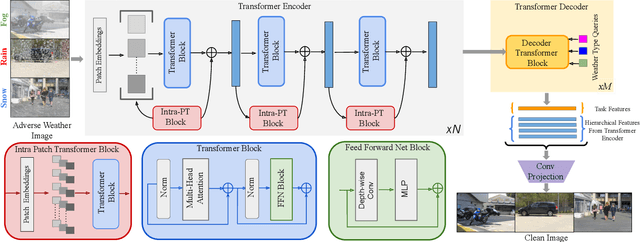
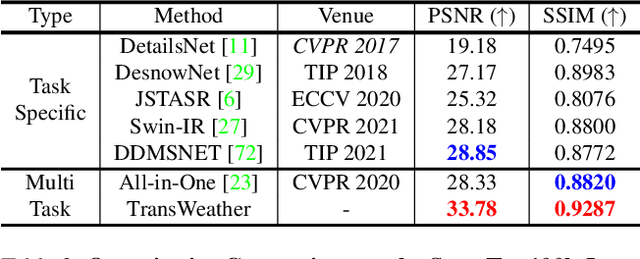
Removing adverse weather conditions like rain, fog, and snow from images is an important problem in many applications. Most methods proposed in the literature have been designed to deal with just removing one type of degradation. Recently, a CNN-based method using neural architecture search (All-in-One) was proposed to remove all the weather conditions at once. However, it has a large number of parameters as it uses multiple encoders to cater to each weather removal task and still has scope for improvement in its performance. In this work, we focus on developing an efficient solution for the all adverse weather removal problem. To this end, we propose TransWeather, a transformer-based end-to-end model with just a single encoder and a decoder that can restore an image degraded by any weather condition. Specifically, we utilize a novel transformer encoder using intra-patch transformer blocks to enhance attention inside the patches to effectively remove smaller weather degradations. We also introduce a transformer decoder with learnable weather type embeddings to adjust to the weather degradation at hand. TransWeather achieves significant improvements across multiple test datasets over both All-in-One network as well as methods fine-tuned for specific tasks. In particular, TransWeather pushes the current state-of-the-art by +6.34 PSNR on the Test1 (rain+fog) dataset, +4.93 PSNR on the SnowTest100K-L dataset and +3.11 PSNR on the RainDrop test dataset. TransWeather is also validated on real world test images and found to be more effective than previous methods. Implementation code and pre-trained weights can be accessed at https://github.com/jeya-maria-jose/TransWeather .