 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Prosody Control for Speech Generation
Nov 07, 2021
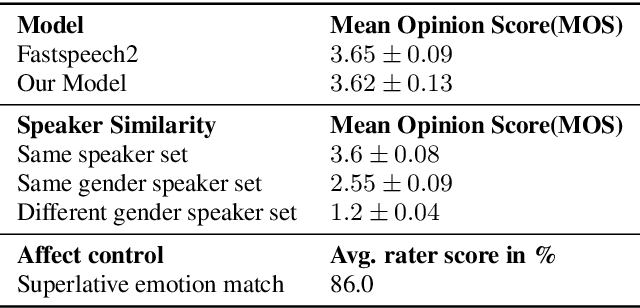
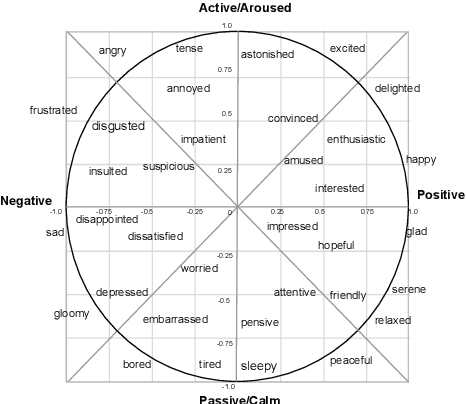
Machine-generated speech is characterized by its limited or unnatural emotional variation. Current text to speech systems generates speech with either a flat emotion, emotion selected from a predefined set, average variation learned from prosody sequences in training data or transferred from a source style. We propose a text to speech(TTS) system, where a user can choose the emotion of generated speech from a continuous and meaningful emotion space (Arousal-Valence space). The proposed TTS system can generate speech from the text in any speaker's style, with fine control of emotion. We show that the system works on emotion unseen during training and can scale to previously unseen speakers given his/her speech sample. Our work expands the horizon of the state-of-the-art FastSpeech2 backbone to a multi-speaker setting and gives it much-coveted continuous (and interpretable) affective control, without any observable degradation in the quality of the synthesized speech.
Reappraising Domain Generalization in Neural Networks
Oct 15, 2021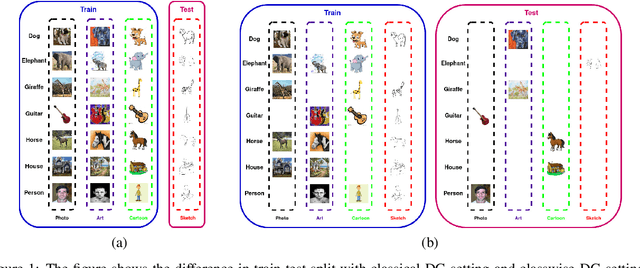


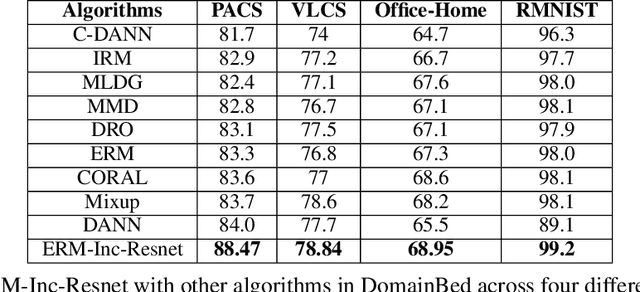
Domain generalization (DG) of machine learning algorithms is defined as their ability to learn a domain agnostic hypothesis from multiple training distributions, which generalizes onto data from an unseen domain. DG is vital in scenarios where the target domain with distinct characteristics has sparse data for training. Aligning with recent work~\cite{gulrajani2020search}, we find that a straightforward Empirical Risk Minimization (ERM) baseline consistently outperforms existing DG methods. We present ablation studies indicating that the choice of backbone, data augmentation, and optimization algorithms overshadows the many tricks and trades explored in the prior art. Our work leads to a new state of the art on the four popular DG datasets, surpassing previous methods by large margins. Furthermore, as a key contribution, we propose a classwise-DG formulation, where for each class, we randomly select one of the domains and keep it aside for testing. We argue that this benchmarking is closer to human learning and relevant in real-world scenarios. We comprehensively benchmark classwise-DG on the DomainBed and propose a method combining ERM and reverse gradients to achieve the state-of-the-art results. To our surprise, despite being exposed to all domains during training, the classwise DG is more challenging than traditional DG evaluation and motivates more fundamental rethinking on the problem of DG.
Bringing Generalization to Deep Multi-view Detection
Sep 24, 2021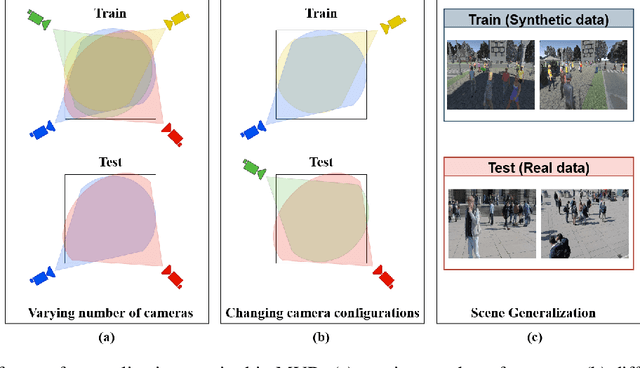
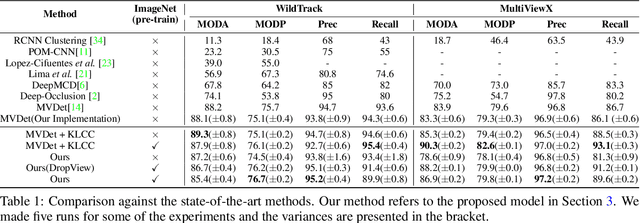
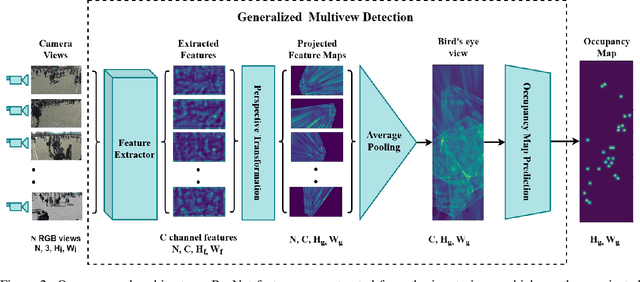
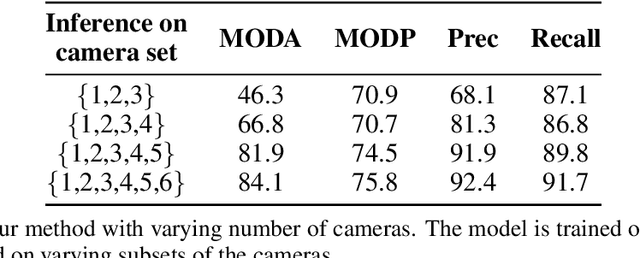
Multi-view Detection (MVD) is highly effective for occlusion reasoning and is a mainstream solution in various applications that require accurate top-view occupancy maps. While recent works using deep learning have made significant advances in the field, they have overlooked the generalization aspect, which makes them \emph{impractical for real-world deployment}. The key novelty of our work is to \emph{formalize} three critical forms of generalization and \emph{propose experiments to investigate them}: i) generalization across a varying number of cameras, ii) generalization with varying camera positions, and finally, iii) generalization to new scenes. We find that existing \sota models show poor generalization by overfitting to a single scene and camera configuration. We propose modifications in terms of pre-training, pooling strategy, regularization, and loss function to an existing state-of-the-art framework, leading to successful generalization across new camera configurations and new scenes. We perform a comprehensive set of experiments on the \wildtrack and \multiviewx datasets to (a) motivate the necessity to evaluate MVD methods on generalization abilities and (b) demonstrate the efficacy of the proposed approach. The code is publicly available at \url{https://github.com/jeetv/GMVD}
High-Resolution Depth Maps Based on TOF-Stereo Fusion
Jul 30, 2021

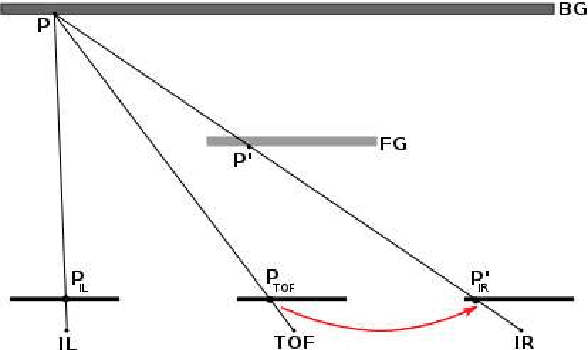

The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial "seeds" are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU.
Comprehensive Multi-Modal Interactions for Referring Image Segmentation
Apr 21, 2021
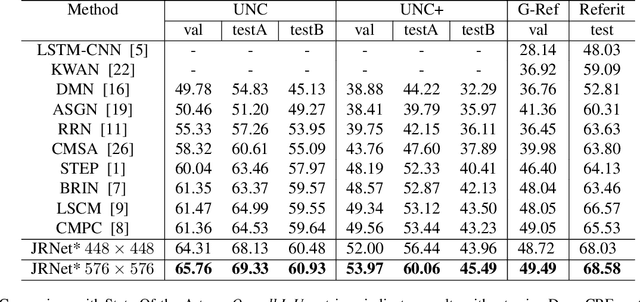
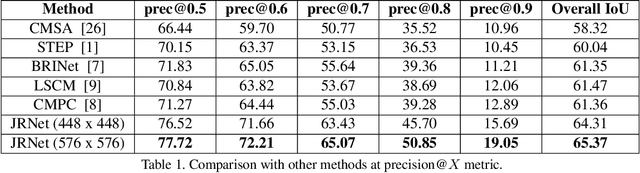
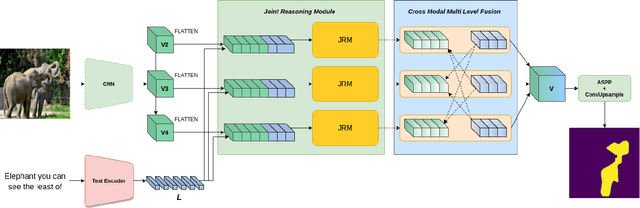
We investigate Referring Image Segmentation (RIS), which outputs a segmentation map corresponding to the given natural language description. To solve RIS efficiently, we need to understand each word's relationship with other words, each region in the image to other regions, and cross-modal alignment between linguistic and visual domains. Recent methods model these three types of interactions sequentially. We argue that such a modular approach limits these methods' performance, and joint simultaneous reasoning can help resolve ambiguities. To this end, we propose a Joint Reasoning (JRM) module and a novel Cross-Modal Multi-Level Fusion (CMMLF) module for tackling this task. JRM effectively models the referent's multi-modal context by jointly reasoning over visual and linguistic modalities (performing word-word, image region-region, word-region interactions in a single module). CMMLF module further refines the segmentation masks by exchanging contextual information across visual hierarchy through linguistic features acting as a bridge. We present thorough ablation studies and validate our approach's performance on four benchmark datasets, and show that the proposed method outperforms the existing state-of-the-art methods on all four datasets by significant margins.
No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep Networks
Apr 01, 2021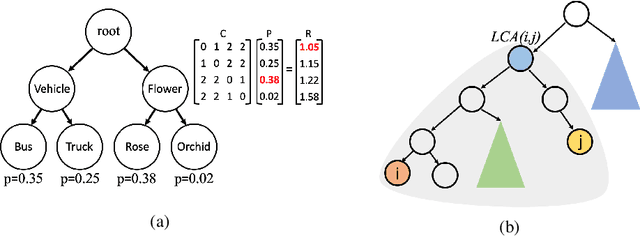
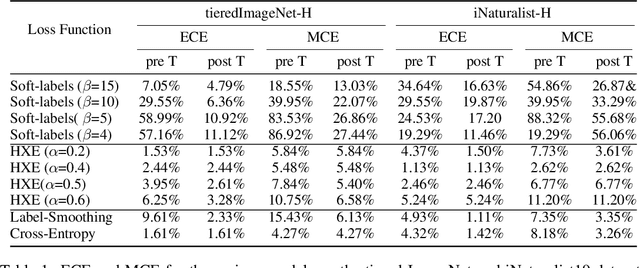


There has been increasing interest in building deep hierarchy-aware classifiers that aim to quantify and reduce the severity of mistakes, and not just reduce the number of errors. The idea is to exploit the label hierarchy (e.g., the WordNet ontology) and consider graph distances as a proxy for mistake severity. Surprisingly, on examining mistake-severity distributions of the top-1 prediction, we find that current state-of-the-art hierarchy-aware deep classifiers do not always show practical improvement over the standard cross-entropy baseline in making better mistakes. The reason for the reduction in average mistake-severity can be attributed to the increase in low-severity mistakes, which may also explain the noticeable drop in their accuracy. To this end, we use the classical Conditional Risk Minimization (CRM) framework for hierarchy-aware classification. Given a cost matrix and a reliable estimate of likelihoods (obtained from a trained network), CRM simply amends mistakes at inference time; it needs no extra hyperparameters and requires adding just a few lines of code to the standard cross-entropy baseline. It significantly outperforms the state-of-the-art and consistently obtains large reductions in the average hierarchical distance of top-$k$ predictions across datasets, with very little loss in accuracy. CRM, because of its simplicity, can be used with any off-the-shelf trained model that provides reliable likelihood estimates.
AViNet: Diving Deep into Audio-Visual Saliency Prediction
Dec 11, 2020

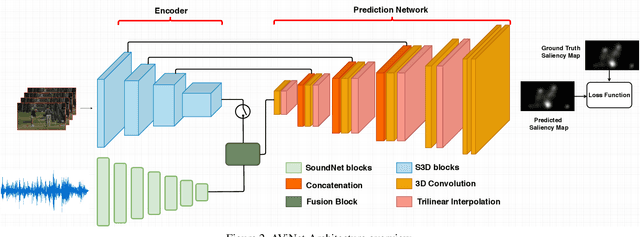
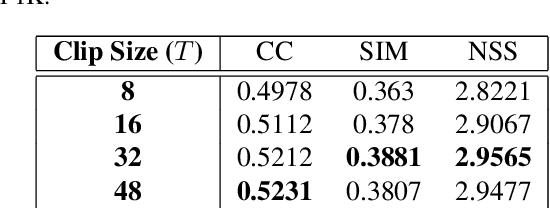
We propose the \textbf{AViNet} architecture for audiovisual saliency prediction. AViNet is a fully convolutional encoder-decoder architecture. The encoder combines visual features learned for action recognition, with audio embeddings learned via an aural network designed to classify objects and scenes. The decoder infers a saliency map via trilinear interpolation and 3D convolutions, combining hierarchical features. The overall architecture is conceptually simple, causal, and runs in real-time (60 fps). AViNet outperforms the state-of-the-art on ten (seven audiovisual and three visual-only) datasets while surpassing human performance on the CC, SIM, and AUC metrics for the AVE dataset. Visual features maximally account for saliency on existing datasets with audio-only contributing to minor gains, except in specific contexts like social events. Our work, therefore, motivates the need to curate saliency datasets reflective of real-life, where both the visual and aural modalities complimentarily drive saliency. Our code and pre-trained models are available at https://github.com/samyak0210/VideoSaliency
GAZED- Gaze-guided Cinematic Editing of Wide-Angle Monocular Video Recordings
Oct 22, 2020

We present GAZED- eye GAZe-guided EDiting for videos captured by a solitary, static, wide-angle and high-resolution camera. Eye-gaze has been effectively employed in computational applications as a cue to capture interesting scene content; we employ gaze as a proxy to select shots for inclusion in the edited video. Given the original video, scene content and user eye-gaze tracks are combined to generate an edited video comprising cinematically valid actor shots and shot transitions to generate an aesthetic and vivid representation of the original narrative. We model cinematic video editing as an energy minimization problem over shot selection, whose constraints capture cinematographic editing conventions. Gazed scene locations primarily determine the shots constituting the edited video. Effectiveness of GAZED against multiple competing methods is demonstrated via a psychophysical study involving 12 users and twelve performance videos.
* 10 pages
Cosine meets Softmax: A tough-to-beat baseline for visual grounding
Sep 13, 2020
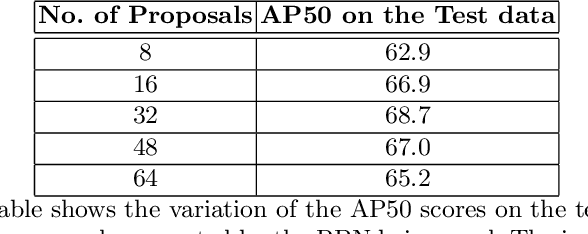

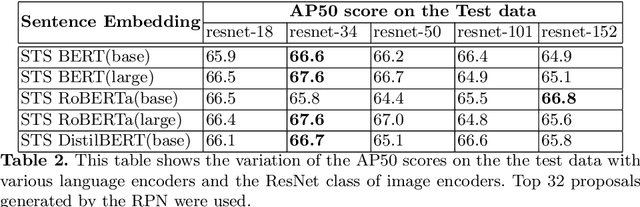
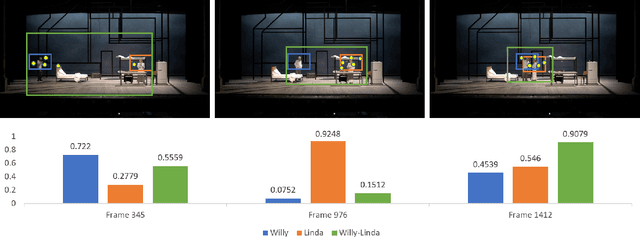
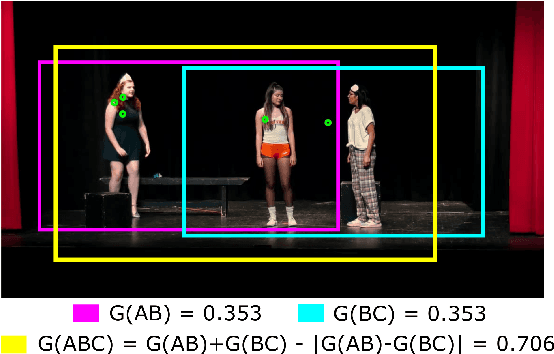
In this paper, we present a simple baseline for visual grounding for autonomous driving which outperforms the state of the art methods, while retaining minimal design choices. Our framework minimizes the cross-entropy loss over the cosine distance between multiple image ROI features with a text embedding (representing the give sentence/phrase). We use pre-trained networks for obtaining the initial embeddings and learn a transformation layer on top of the text embedding. We perform experiments on the Talk2Car dataset and achieve 68.7% AP50 accuracy, improving upon the previous state of the art by 8.6%. Our investigation suggests reconsideration towards more approaches employing sophisticated attention mechanisms or multi-stage reasoning or complex metric learning loss functions by showing promise in simpler alternatives.
The Curious Case of Convex Networks
Jun 09, 2020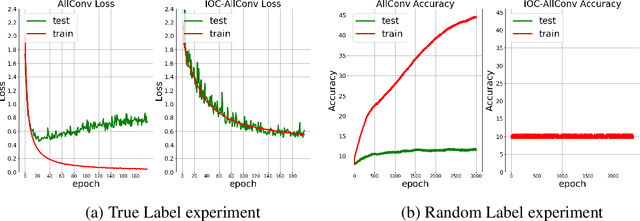
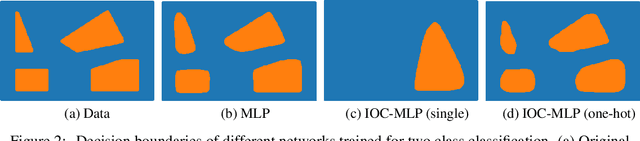
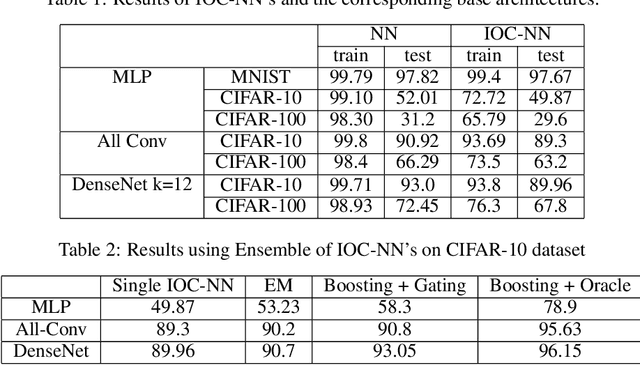
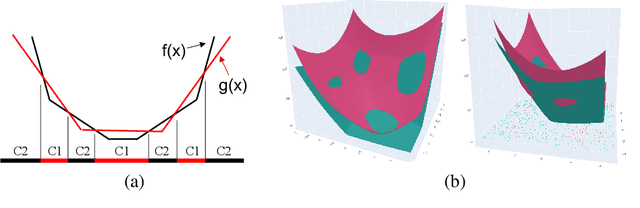
In this paper, we investigate a constrained formulation of neural networks where the output is a convex function of the input. We show that the convexity constraints can be enforced on both fully connected and convolutional layers, making them applicable to most architectures. The convexity constraints include restricting the weights (for all but the first layer) to be non-negative and using a non-decreasing convex activation function. Albeit simple, these constraints have profound implications on the generalization abilities of the network. We draw three valuable insights: (a) Input Output Convex Networks (IOC-NN) self regularize and almost uproot the problem of overfitting; (b) Although heavily constrained, they come close to the performance of the base architectures; and (c) The ensemble of convex networks can match or outperform the non convex counterparts. We demonstrate the efficacy of the proposed idea using thorough experiments and ablation studies on MNIST, CIFAR10, and CIFAR100 datasets with three different neural network architectures. The code for this project is publicly available at: \url{https://github.com/sarathsp1729/Convex-Networks}.