 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Concept Decoders: Training Scalable End-to-End Interpretability Assistants
Dec 17, 2025Interpreting the internal activations of neural networks can produce more faithful explanations of their behavior, but is difficult due to the complex structure of activation space. Existing approaches to scalable interpretability use hand-designed agents that make and test hypotheses about how internal activations relate to external behavior. We propose to instead turn this task into an end-to-end training objective, by training interpretability assistants to accurately predict model behavior from activations through a communication bottleneck. Specifically, an encoder compresses activations to a sparse list of concepts, and a decoder reads this list and answers a natural language question about the model. We show how to pretrain this assistant on large unstructured data, then finetune it to answer questions. The resulting architecture, which we call a Predictive Concept Decoder, enjoys favorable scaling properties: the auto-interp score of the bottleneck concepts improves with data, as does the performance on downstream applications. Specifically, PCDs can detect jailbreaks, secret hints, and implanted latent concepts, and are able to accurately surface latent user attributes.
Training Language Models to Explain Their Own Computations
Nov 11, 2025



Can language models (LMs) learn to faithfully describe their internal computations? Are they better able to describe themselves than other models? We study the extent to which LMs' privileged access to their own internals can be leveraged to produce new techniques for explaining their behavior. Using existing interpretability techniques as a source of ground truth, we fine-tune LMs to generate natural language descriptions of (1) the information encoded by LM features, (2) the causal structure of LMs' internal activations, and (3) the influence of specific input tokens on LM outputs. When trained with only tens of thousands of example explanations, explainer models exhibit non-trivial generalization to new queries. This generalization appears partly attributable to explainer models' privileged access to their own internals: using a model to explain its own computations generally works better than using a *different* model to explain its computations (even if the other model is significantly more capable). Our results suggest not only that LMs can learn to reliably explain their internal computations, but that such explanations offer a scalable complement to existing interpretability methods.
Using Large Language Models to Understand Telecom Standards
Apr 12, 2024



The Third Generation Partnership Project (3GPP) has successfully introduced standards for global mobility. However, the volume and complexity of these standards has increased over time, thus complicating access to relevant information for vendors and service providers. Use of Generative Artificial Intelligence (AI) and in particular Large Language Models (LLMs), may provide faster access to relevant information. In this paper, we evaluate the capability of state-of-art LLMs to be used as Question Answering (QA) assistants for 3GPP document reference. Our contribution is threefold. First, we provide a benchmark and measuring methods for evaluating performance of LLMs. Second, we do data preprocessing and fine-tuning for one of these LLMs and provide guidelines to increase accuracy of the responses that apply to all LLMs. Third, we provide a model of our own, TeleRoBERTa, that performs on-par with foundation LLMs but with an order of magnitude less number of parameters. Results show that LLMs can be used as a credible reference tool on telecom technical documents, and thus have potential for a number of different applications from troubleshooting and maintenance, to network operations and software product development.
Enhanced Experience Replay Generation for Efficient Reinforcement Learning
May 29, 2017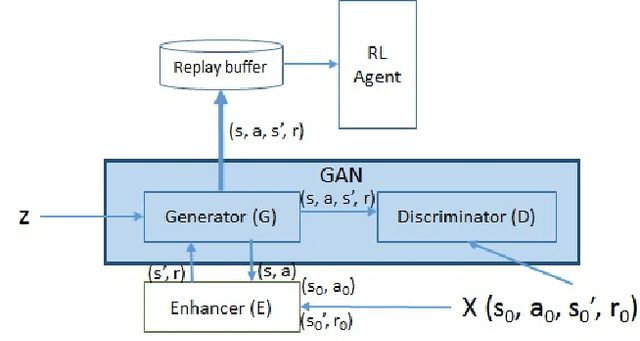

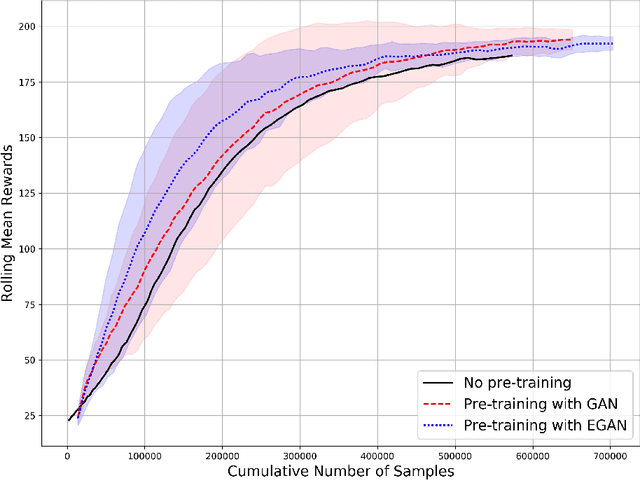
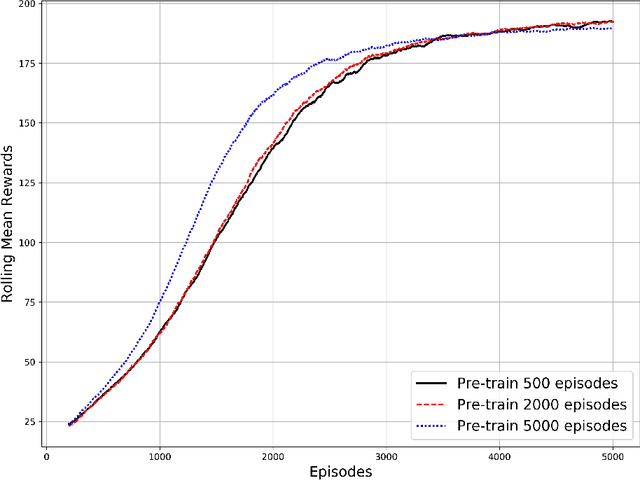
Applying deep reinforcement learning (RL) on real systems suffers from slow data sampling. We propose an enhanced generative adversarial network (EGAN) to initialize an RL agent in order to achieve faster learning. The EGAN utilizes the relation between states and actions to enhance the quality of data samples generated by a GAN. Pre-training the agent with the EGAN shows a steeper learning curve with a 20% improvement of training time in the beginning of learning, compared to no pre-training, and an improvement compared to training with GAN by about 5% with smaller variations. For real time systems with sparse and slow data sampling the EGAN could be used to speed up the early phases of the training process.