 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICC++: Explainable Image Retrieval for Art Historical Corpora using Image Composition Canvas
Jun 22, 2022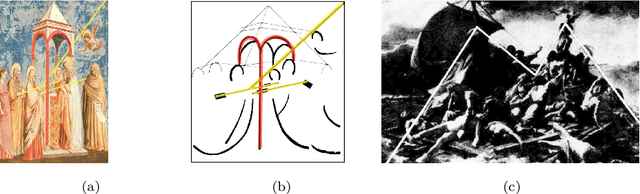
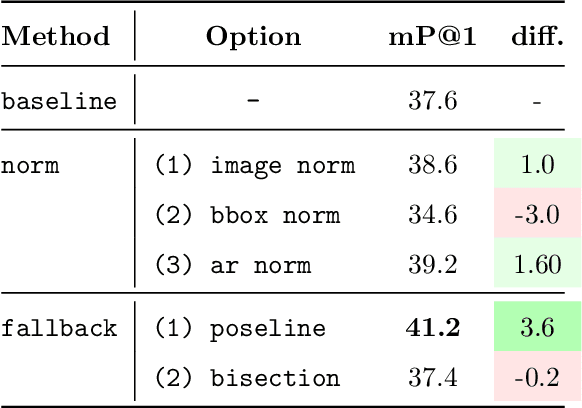
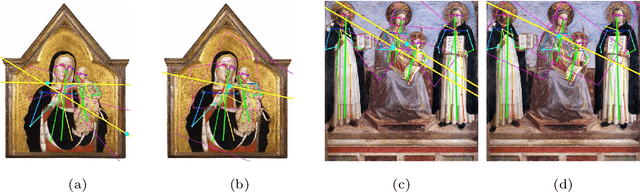
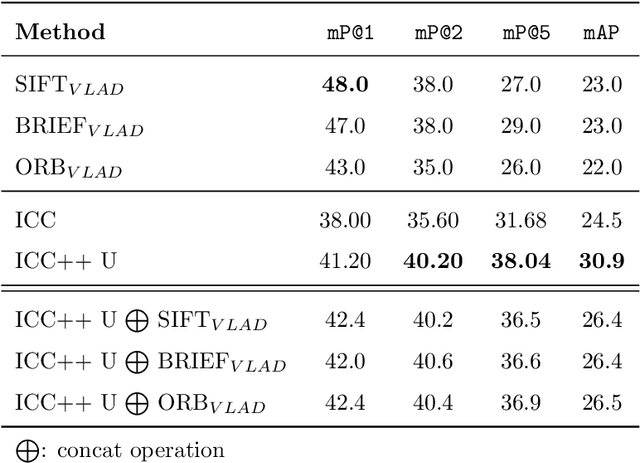
Image compositions are helpful in the study of image structures and assist in discovering the semantics of the underlying scene portrayed across art forms and styles. With the digitization of artworks in recent years, thousands of images of a particular scene or narrative could potentially be linked together. However, manually linking this data with consistent objectiveness can be a highly challenging and time-consuming task. In this work, we present a novel approach called Image Composition Canvas (ICC++) to compare and retrieve images having similar compositional elements. ICC++ is an improvement over ICC specializing in generating low and high-level features (compositional elements) motivated by Max Imdahl's work. To this end, we present a rigorous quantitative and qualitative comparison of our approach with traditional and state-of-the-art (SOTA) methods showing that our proposed method outperforms all of them. In combination with deep features, our method outperforms the best deep learning-based method, opening the research direction for explainable machine learning for digital humanities. We will release the code and the data post-publication.
Exploring the Open World Using Incremental Extreme Value Machines
May 30, 2022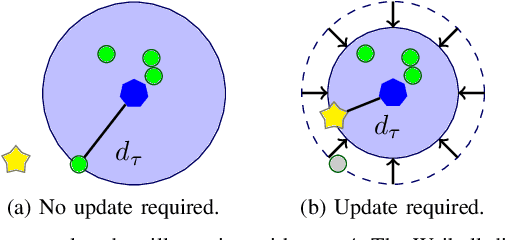

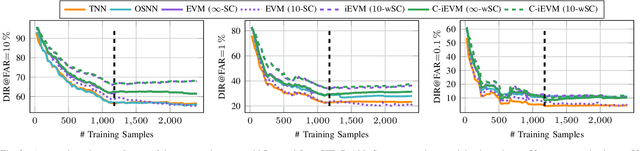
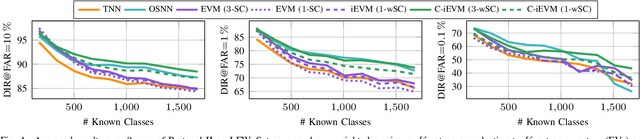
Dynamic environments require adaptive applications. One particular machine learning problem in dynamic environments is open world recognition. It characterizes a continuously changing domain where only some classes are seen in one batch of the training data and such batches can only be learned incrementally. Open world recognition is a demanding task that is, to the best of our knowledge, addressed by only a few methods. This work introduces a modification of the widely known Extreme Value Machine (EVM) to enable open world recognition. Our proposed method extends the EVM with a partial model fitting function by neglecting unaffected space during an update. This reduces the training time by a factor of 28. In addition, we provide a modified model reduction using weighted maximum K-set cover to strictly bound the model complexity and reduce the computational effort by a factor of 3.5 from 2.1 s to 0.6 s. In our experiments, we rigorously evaluate openness with two novel evaluation protocols. The proposed method achieves superior accuracy of about 12 % and computational efficiency in the tasks of image classification and face recognition.
TorMentor: Deterministic dynamic-path, data augmentations with fractals
Apr 07, 2022
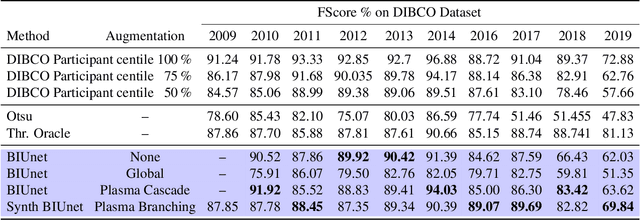

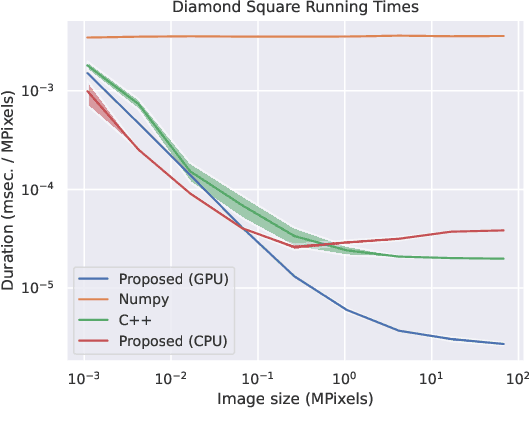
We propose the use of fractals as a means of efficient data augmentation. Specifically, we employ plasma fractals for adapting global image augmentation transformations into continuous local transforms. We formulate the diamond square algorithm as a cascade of simple convolution operations allowing efficient computation of plasma fractals on the GPU. We present the TorMentor image augmentation framework that is totally modular and deterministic across images and point-clouds. All image augmentation operations can be combined through pipelining and random branching to form flow networks of arbitrary width and depth. We demonstrate the efficiency of the proposed approach with experiments on document image segmentation (binarization) with the DIBCO datasets. The proposed approach demonstrates superior performance to traditional image augmentation techniques. Finally, we use extended synthetic binary text images in a self-supervision regiment and outperform the same model when trained with limited data and simple extensions.
SliTraNet: Automatic Detection of Slide Transitions in Lecture Videos using Convolutional Neural Networks
Feb 07, 2022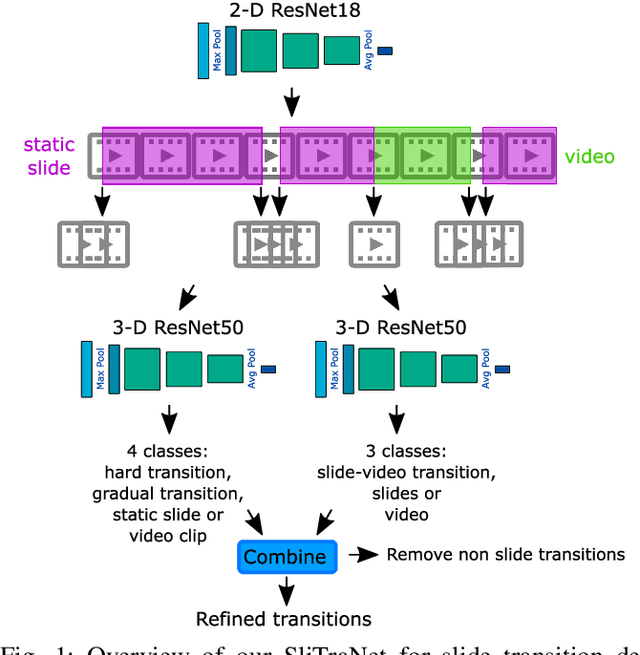
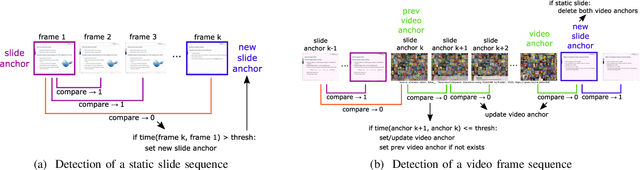
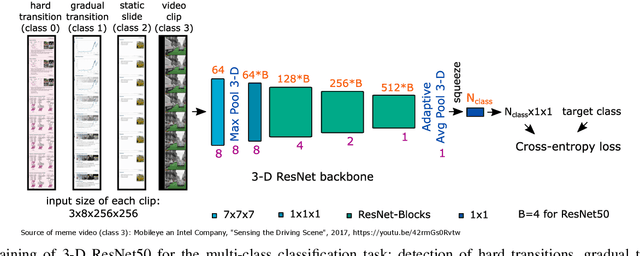

With the increasing number of online learning material in the web, search for specific content in lecture videos can be time consuming. Therefore, automatic slide extraction from the lecture videos can be helpful to give a brief overview of the main content and to support the students in their studies. For this task, we propose a deep learning method to detect slide transitions in lectures videos. We first process each frame of the video by a heuristic-based approach using a 2-D convolutional neural network to predict transition candidates. Then, we increase the complexity by employing two 3-D convolutional neural networks to refine the transition candidates. Evaluation results demonstrate the effectiveness of our method in finding slide transitions.
A Keypoint Detection and Description Network Based on the Vessel Structure for Multi-Modal Retinal Image Registration
Jan 06, 2022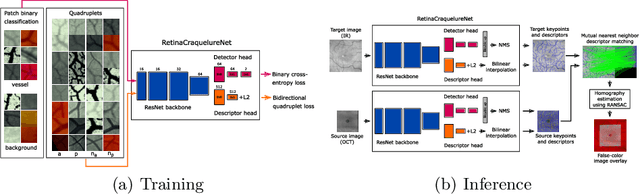

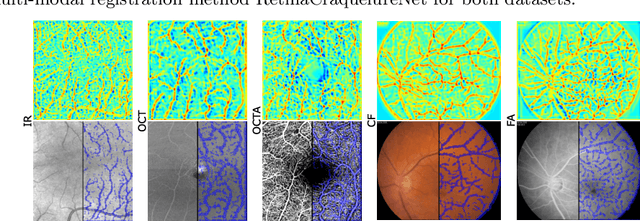

Ophthalmological imaging utilizes different imaging systems, such as color fundus, infrared, fluorescein angiography, optical coherence tomography (OCT) or OCT angiography. Multiple images with different modalities or acquisition times are often analyzed for the diagnosis of retinal diseases. Automatically aligning the vessel structures in the images by means of multi-modal registration can support the ophthalmologists in their work. Our method uses a convolutional neural network to extract features of the vessel structure in multi-modal retinal images. We jointly train a keypoint detection and description network on small patches using a classification and a cross-modal descriptor loss function and apply the network to the full image size in the test phase. Our method demonstrates the best registration performance on our and a public multi-modal dataset in comparison to competing methods.
First steps on Gamification of Lung Fluid Cells Annotations in the Flower Domain
Nov 05, 2021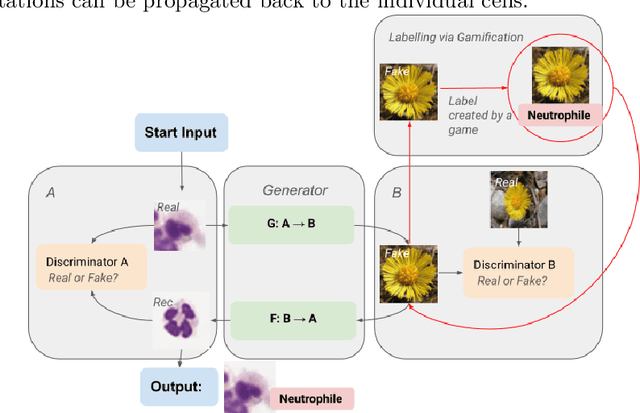

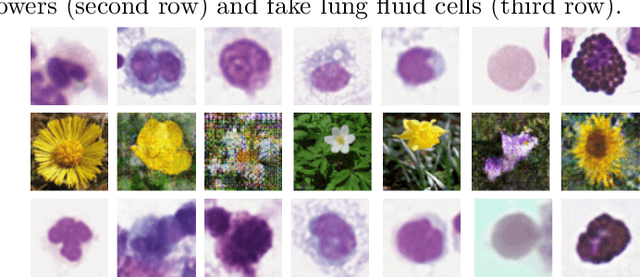
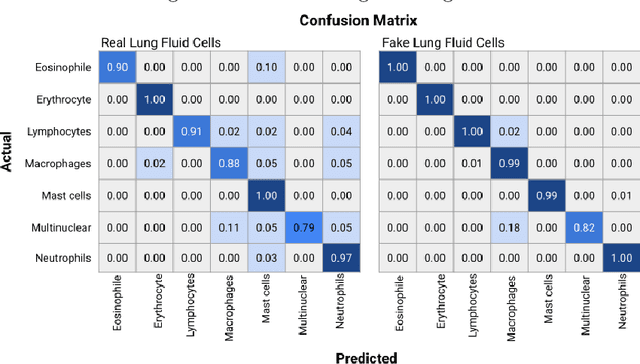
Annotating data, especially in the medical domain, requires expert knowledge and a lot of effort. This limits the amount and/or usefulness of available medical data sets for experimentation. Therefore, developing strategies to increase the number of annotations while lowering the needed domain knowledge is of interest. A possible strategy is the use of gamification, that is i.e. transforming the annotation task into a game. We propose an approach to gamify the task of annotating lung fluid cells from pathological whole slide images. As this domain is unknown to non-expert annotators, we transform images of cells detected with a RetinaNet architecture to the domain of flower images. This domain transfer is performed with a CycleGAN architecture for different cell types. In this more assessable domain, non-expert annotators can be (t)asked to annotate different kinds of flowers in a playful setting. In order to provide a proof of concept, this work shows that the domain transfer is possible by evaluating an image classification network trained on real cell images and tested on the cell images generated by the CycleGAN network. The classification network reaches an accuracy of 97.48% and 95.16% on the original lung fluid cells and transformed lung fluid cells, respectively. With this study, we lay the foundation for future research on gamification using CycleGANs.
Module-Power Prediction from PL Measurements using Deep Learning
Aug 31, 2021
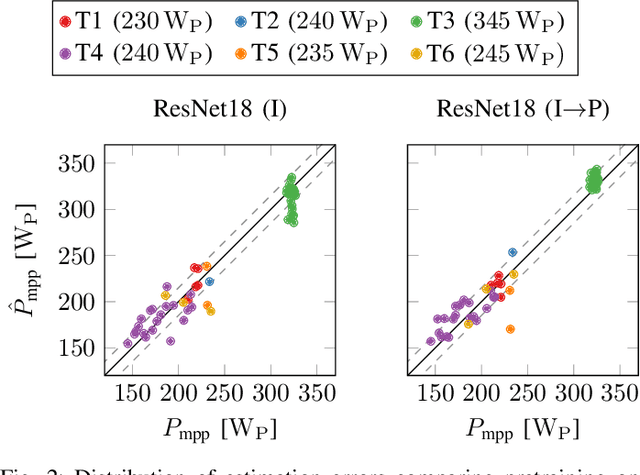
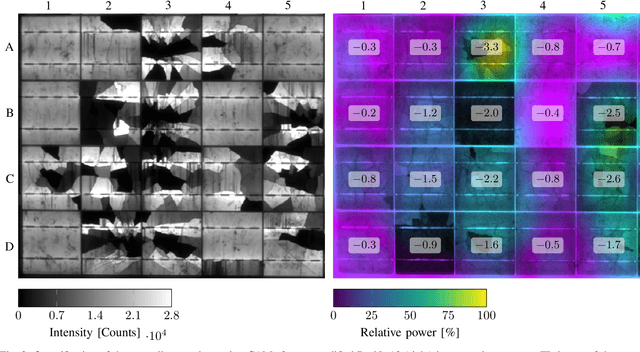
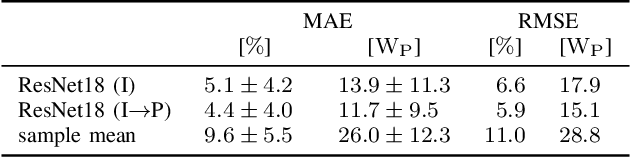
The individual causes for power loss of photovoltaic modules are investigated for quite some time. Recently, it has been shown that the power loss of a module is, for example, related to the fraction of inactive areas. While these areas can be easily identified from electroluminescense (EL) images, this is much harder for photoluminescence (PL) images. With this work, we close the gap between power regression from EL and PL images. We apply a deep convolutional neural network to predict the module power from PL images with a mean absolute error (MAE) of 4.4% or 11.7WP. Furthermore, we depict that regression maps computed from the embeddings of the trained network can be used to compute the localized power loss. Finally, we show that these regression maps can be used to identify inactive regions in PL images as well.
SmartPatch: Improving Handwritten Word Imitation with Patch Discriminators
May 21, 2021
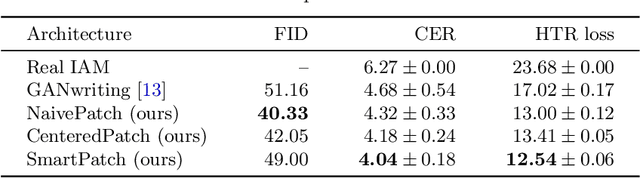
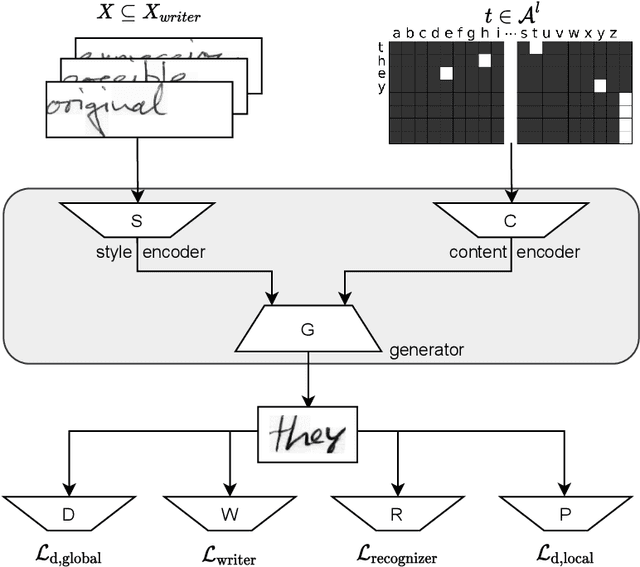

As of recent generative adversarial networks have allowed for big leaps in the realism of generated images in diverse domains, not the least of which being handwritten text generation. The generation of realistic-looking hand-written text is important because it can be used for data augmentation in handwritten text recognition (HTR) systems or human-computer interaction. We propose SmartPatch, a new technique increasing the performance of current state-of-the-art methods by augmenting the training feedback with a tailored solution to mitigate pen-level artifacts. We combine the well-known patch loss with information gathered from the parallel trained handwritten text recognition system and the separate characters of the word. This leads to a more enhanced local discriminator and results in more realistic and higher-quality generated handwritten words.
How Will Your Tweet Be Received? Predicting the Sentiment Polarity of Tweet Replies
Apr 21, 2021

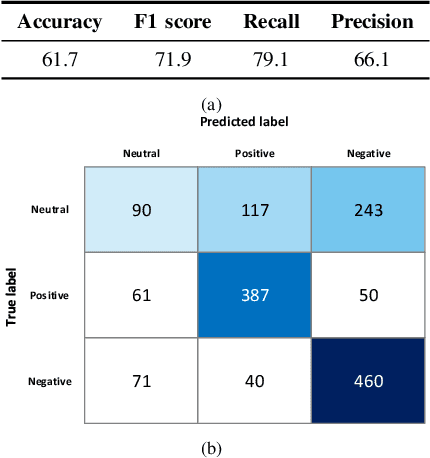
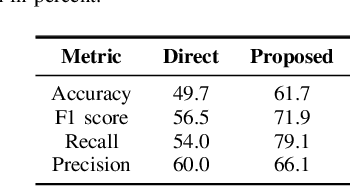
Twitter sentiment analysis, which often focuses on predicting the polarity of tweets, has attracted increasing attention over the last years, in particular with the rise of deep learning (DL). In this paper, we propose a new task: predicting the predominant sentiment among (first-order) replies to a given tweet. Therefore, we created RETWEET, a large dataset of tweets and replies manually annotated with sentiment labels. As a strong baseline, we propose a two-stage DL-based method: first, we create automatically labeled training data by applying a standard sentiment classifier to tweet replies and aggregating its predictions for each original tweet; our rationale is that individual errors made by the classifier are likely to cancel out in the aggregation step. Second, we use the automatically labeled data for supervised training of a neural network to predict reply sentiment from the original tweets. The resulting classifier is evaluated on the new RETWEET dataset, showing promising results, especially considering that it has been trained without any manually labeled data. Both the dataset and the baseline implementation are publicly available.
* Published in 2021 IEEE 15th International Conference on Semantic Computing (ICSC)
Is Medical Chest X-ray Data Anonymous?
Mar 15, 2021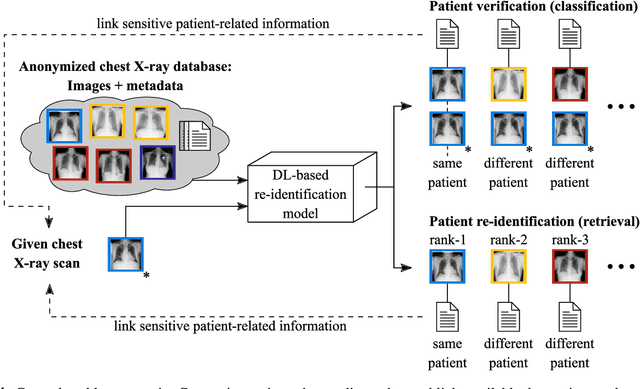
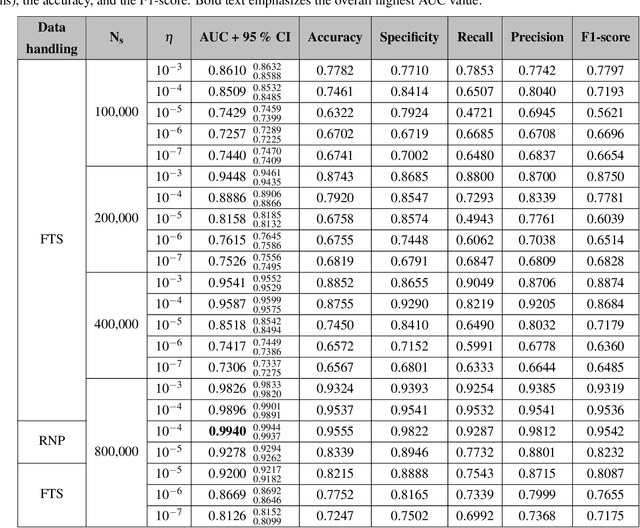
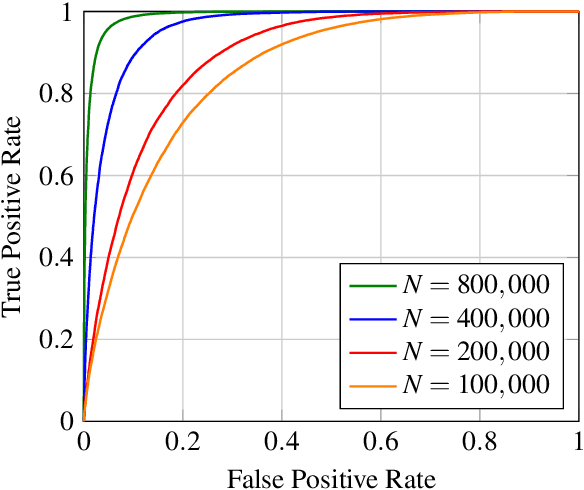
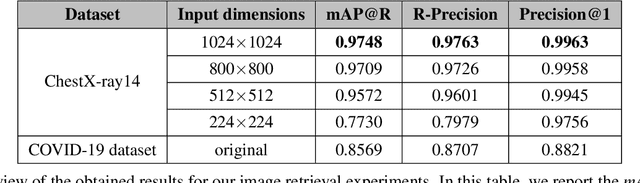
With the rise and ever-increasing potential of deep learning techniques in recent years, publicly available medical data sets became a key factor to enable reproducible development of diagnostic algorithms in the medical domain. Medical data contains sensitive patient-related information and is therefore usually anonymized by removing patient identifiers, e.g., patient names before publication. To the best of our knowledge, we are the first to show that a well-trained deep learning system is able to recover the patient identity from chest X-ray data. We demonstrate this using the publicly available large-scale ChestX-ray14 dataset, a collection of 112,120 frontal-view chest X-ray images from 30,805 unique patients. Our verification system is able to identify whether two frontal chest X-ray images are from the same person with an AUC of 0.9940 and a classification accuracy of 95.55%. We further highlight that the proposed system is able to reveal the same person even ten and more years after the initial scan. When pursuing a retrieval approach, we observe an mAP@R of 0.9748 and a precision@1 of 0.9963. Based on this high identification rate, a potential attacker may leak patient-related information and additionally cross-reference images to obtain more information. Thus, there is a great risk of sensitive content falling into unauthorized hands or being disseminated against the will of the concerned patients. Especially during the COVID-19 pandemic, numerous chest X-ray datasets have been published to advance research. Therefore, such data may be vulnerable to potential attacks by deep learning-based re-identification algorithms.