 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Particle Approximations
Dec 06, 2015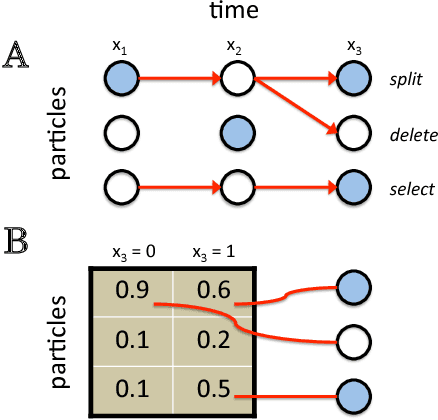

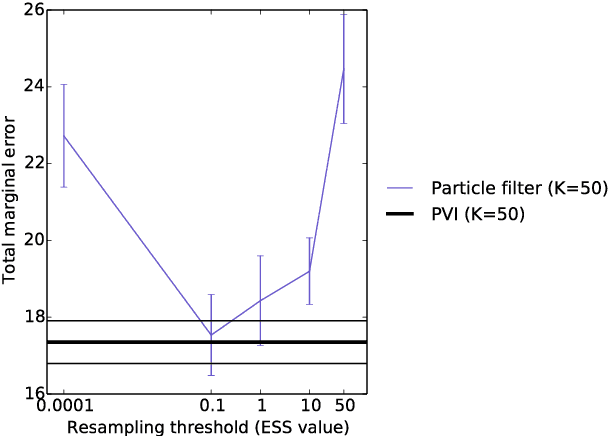

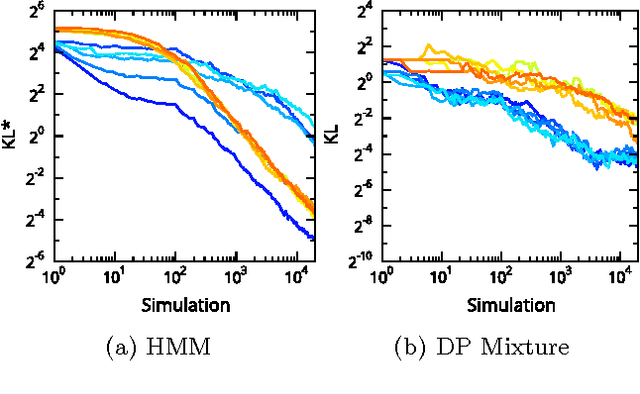
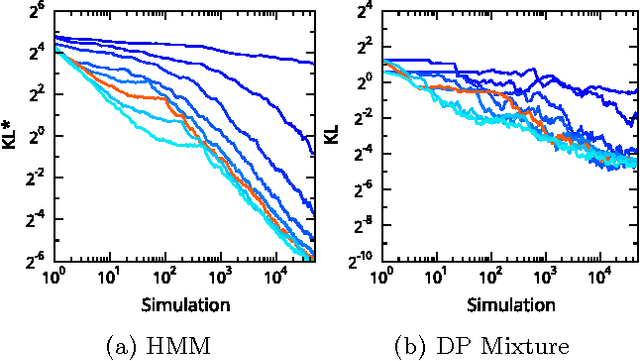
Approximate inference in high-dimensional, discrete probabilistic models is a central problem in computational statistics and machine learning. This paper describes discrete particle variational inference (DPVI), a new approach that combines key strengths of Monte Carlo, variational and search-based techniques. DPVI is based on a novel family of particle-based variational approximations that can be fit using simple, fast, deterministic search techniques. Like Monte Carlo, DPVI can handle multiple modes, and yields exact results in a well-defined limit. Like unstructured mean-field, DPVI is based on optimizing a lower bound on the partition function; when this quantity is not of intrinsic interest, it facilitates convergence assessment and debugging. Like both Monte Carlo and combinatorial search, DPVI can take advantage of factorization, sequential structure, and custom search operators. This paper defines DPVI particle-based approximation family and partition function lower bounds, along with the sequential DPVI and local DPVI algorithm templates for optimizing them. DPVI is illustrated and evaluated via experiments on lattice Markov Random Fields, nonparametric Bayesian mixtures and block-models, and parametric as well as non-parametric hidden Markov models. Results include applications to real-world spike-sorting and relational modeling problems, and show that DPVI can offer appealing time/accuracy trade-offs as compared to multiple alternatives.
CrossCat: A Fully Bayesian Nonparametric Method for Analyzing Heterogeneous, High Dimensional Data
Dec 03, 2015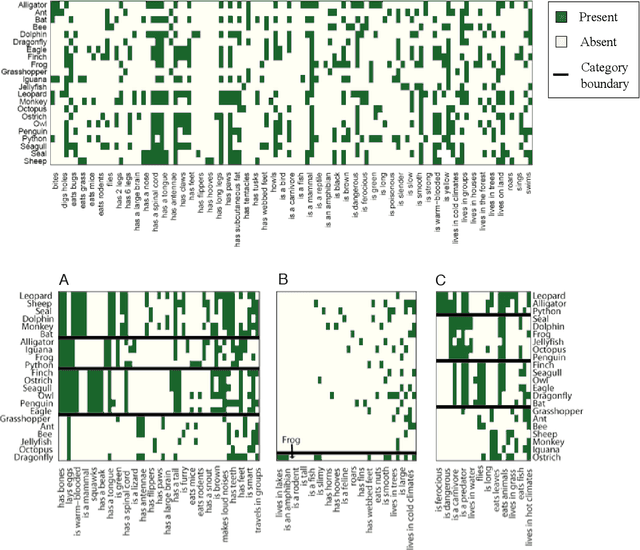
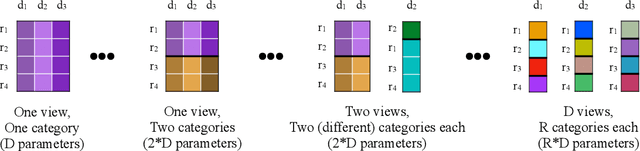
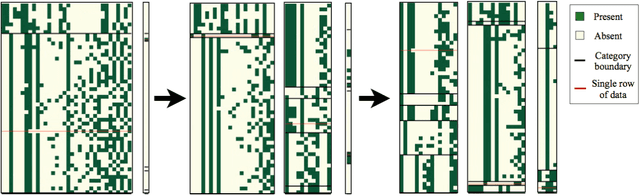
There is a widespread need for statistical methods that can analyze high-dimensional datasets with- out imposing restrictive or opaque modeling assumptions. This paper describes a domain-general data analysis method called CrossCat. CrossCat infers multiple non-overlapping views of the data, each consisting of a subset of the variables, and uses a separate nonparametric mixture to model each view. CrossCat is based on approximately Bayesian inference in a hierarchical, nonparamet- ric model for data tables. This model consists of a Dirichlet process mixture over the columns of a data table in which each mixture component is itself an independent Dirichlet process mixture over the rows; the inner mixture components are simple parametric models whose form depends on the types of data in the table. CrossCat combines strengths of mixture modeling and Bayesian net- work structure learning. Like mixture modeling, CrossCat can model a broad class of distributions by positing latent variables, and produces representations that can be efficiently conditioned and sampled from for prediction. Like Bayesian networks, CrossCat represents the dependencies and independencies between variables, and thus remains accurate when there are multiple statistical signals. Inference is done via a scalable Gibbs sampling scheme; this paper shows that it works well in practice. This paper also includes empirical results on heterogeneous tabular data of up to 10 million cells, such as hospital cost and quality measures, voting records, unemployment rates, gene expression measurements, and images of handwritten digits. CrossCat infers structure that is consistent with accepted findings and common-sense knowledge in multiple domains and yields predictive accuracy competitive with generative, discriminative, and model-free alternatives.
A New Approach to Probabilistic Programming Inference
Jul 09, 2015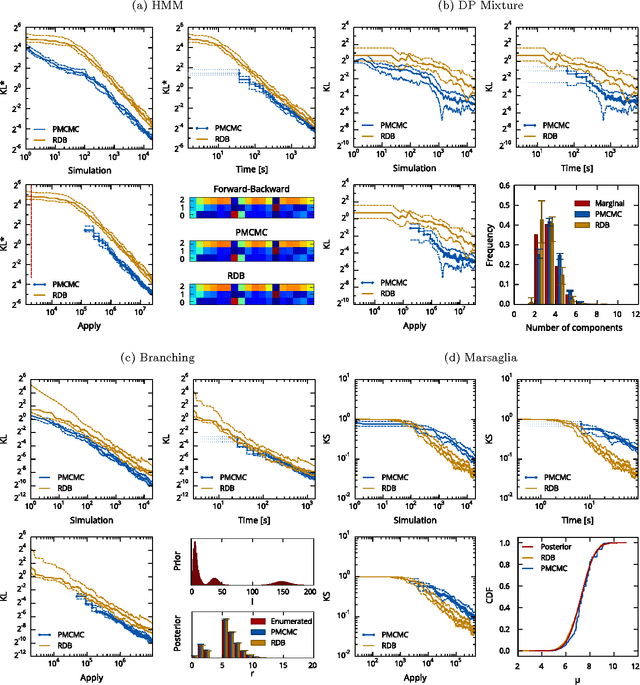
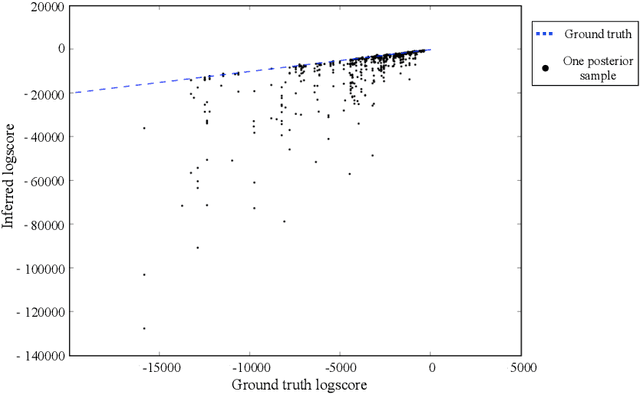
We introduce and demonstrate a new approach to inference in expressive probabilistic programming languages based on particle Markov chain Monte Carlo. Our approach is simple to implement and easy to parallelize. It applies to Turing-complete probabilistic programming languages and supports accurate inference in models that make use of complex control flow, including stochastic recursion. It also includes primitives from Bayesian nonparametric statistics. Our experiments show that this approach can be more efficient than previously introduced single-site Metropolis-Hastings methods.
Automatic Inference for Inverting Software Simulators via Probabilistic Programming
May 31, 2015
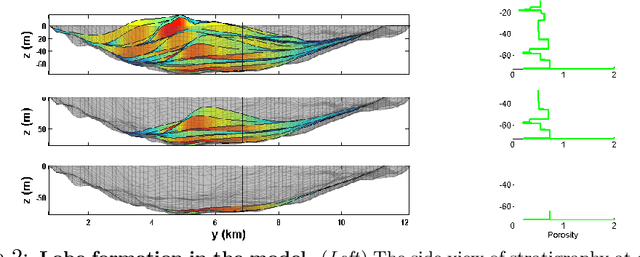

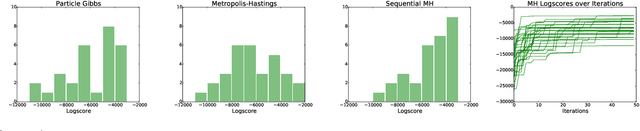
Models of complex systems are often formalized as sequential software simulators: computationally intensive programs that iteratively build up probable system configurations given parameters and initial conditions. These simulators enable modelers to capture effects that are difficult to characterize analytically or summarize statistically. However, in many real-world applications, these simulations need to be inverted to match the observed data. This typically requires the custom design, derivation and implementation of sophisticated inversion algorithms. Here we give a framework for inverting a broad class of complex software simulators via probabilistic programming and automatic inference, using under 20 lines of probabilistic code. Our approach is based on a formulation of inversion as approximate inference in a simple sequential probabilistic model. We implement four inference strategies, including Metropolis-Hastings, a sequentialized Metropolis-Hastings scheme, and a particle Markov chain Monte Carlo scheme, requiring 4 or fewer lines of probabilistic code each. We demonstrate our framework by applying it to invert a real geological software simulator from the oil and gas industry.
Sublinear-Time Approximate MCMC Transitions for Probabilistic Programs
Mar 09, 2015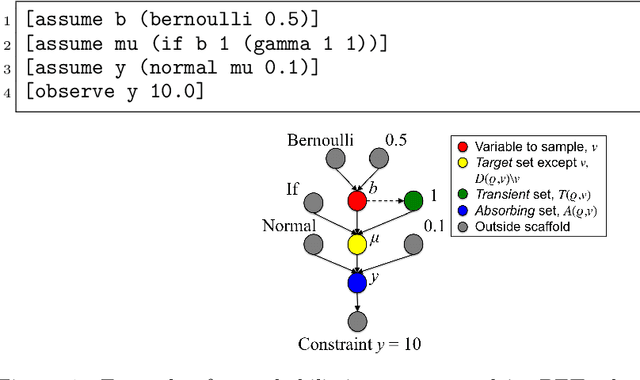

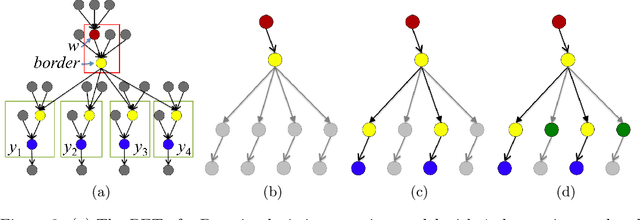
Probabilistic programming languages can simplify the development of machine learning techniques, but only if inference is sufficiently scalable. Unfortunately, Bayesian parameter estimation for highly coupled models such as regressions and state-space models still scales poorly; each MCMC transition takes linear time in the number of observations. This paper describes a sublinear-time algorithm for making Metropolis-Hastings (MH) updates to latent variables in probabilistic programs. The approach generalizes recently introduced approximate MH techniques: instead of subsampling data items assumed to be independent, it subsamples edges in a dynamically constructed graphical model. It thus applies to a broader class of problems and interoperates with other general-purpose inference techniques. Empirical results, including confirmation of sublinear per-transition scaling, are presented for Bayesian logistic regression, nonlinear classification via joint Dirichlet process mixtures, and parameter estimation for stochastic volatility models (with state estimation via particle MCMC). All three applications use the same implementation, and each requires under 20 lines of probabilistic code.
Particle Gibbs with Ancestor Sampling for Probabilistic Programs
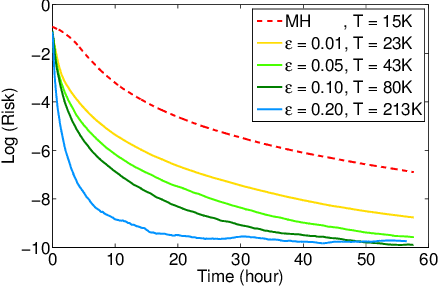
Feb 09, 2015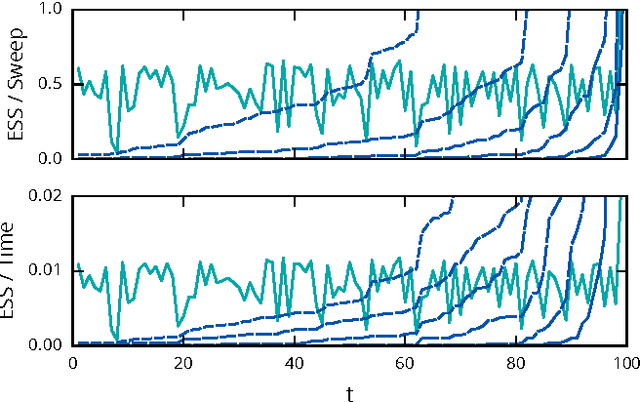
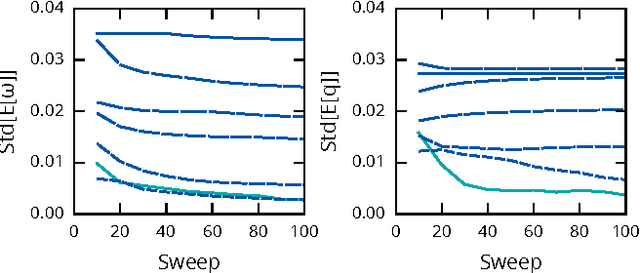
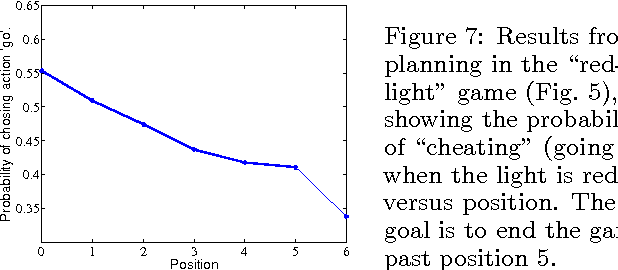
Particle Markov chain Monte Carlo techniques rank among current state-of-the-art methods for probabilistic program inference. A drawback of these techniques is that they rely on importance resampling, which results in degenerate particle trajectories and a low effective sample size for variables sampled early in a program. We here develop a formalism to adapt ancestor resampling, a technique that mitigates particle degeneracy, to the probabilistic programming setting. We present empirical results that demonstrate nontrivial performance gains.
Church: a language for generative models
Jul 15, 2014

We introduce Church, a universal language for describing stochastic generative processes. Church is based on the Lisp model of lambda calculus, containing a pure Lisp as its deterministic subset. The semantics of Church is defined in terms of evaluation histories and conditional distributions on such histories. Church also includes a novel language construct, the stochastic memoizer, which enables simple description of many complex non-parametric models. We illustrate language features through several examples, including: a generalized Bayes net in which parameters cluster over trials, infinite PCFGs, planning by inference, and various non-parametric clustering models. Finally, we show how to implement query on any Church program, exactly and approximately, using Monte Carlo techniques.
Venture: a higher-order probabilistic programming platform with programmable inference
Apr 01, 2014
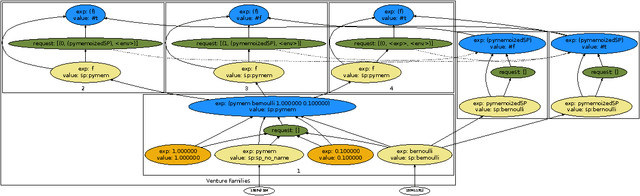
We describe Venture, an interactive virtual machine for probabilistic programming that aims to be sufficiently expressive, extensible, and efficient for general-purpose use. Like Church, probabilistic models and inference problems in Venture are specified via a Turing-complete, higher-order probabilistic language descended from Lisp. Unlike Church, Venture also provides a compositional language for custom inference strategies built out of scalable exact and approximate techniques. We also describe four key aspects of Venture's implementation that build on ideas from probabilistic graphical models. First, we describe the stochastic procedure interface (SPI) that specifies and encapsulates primitive random variables. The SPI supports custom control flow, higher-order probabilistic procedures, partially exchangeable sequences and ``likelihood-free'' stochastic simulators. It also supports external models that do inference over latent variables hidden from Venture. Second, we describe probabilistic execution traces (PETs), which represent execution histories of Venture programs. PETs capture conditional dependencies, existential dependencies and exchangeable coupling. Third, we describe partitions of execution histories called scaffolds that factor global inference problems into coherent sub-problems. Finally, we describe a family of stochastic regeneration algorithms for efficiently modifying PET fragments contained within scaffolds. Stochastic regeneration linear runtime scaling in cases where many previous approaches scaled quadratically. We show how to use stochastic regeneration and the SPI to implement general-purpose inference strategies such as Metropolis-Hastings, Gibbs sampling, and blocked proposals based on particle Markov chain Monte Carlo and mean-field variational inference techniques.
Building fast Bayesian computing machines out of intentionally stochastic, digital parts
Feb 20, 2014The brain interprets ambiguous sensory information faster and more reliably than modern computers, using neurons that are slower and less reliable than logic gates. But Bayesian inference, which underpins many computational models of perception and cognition, appears computationally challenging even given modern transistor speeds and energy budgets. The computational principles and structures needed to narrow this gap are unknown. Here we show how to build fast Bayesian computing machines using intentionally stochastic, digital parts, narrowing this efficiency gap by multiple orders of magnitude. We find that by connecting stochastic digital components according to simple mathematical rules, one can build massively parallel, low precision circuits that solve Bayesian inference problems and are compatible with the Poisson firing statistics of cortical neurons. We evaluate circuits for depth and motion perception, perceptual learning and causal reasoning, each performing inference over 10,000+ latent variables in real time - a 1,000x speed advantage over commodity microprocessors. These results suggest a new role for randomness in the engineering and reverse-engineering of intelligent computation.
Structured Priors for Structure Learning
Jun 27, 2012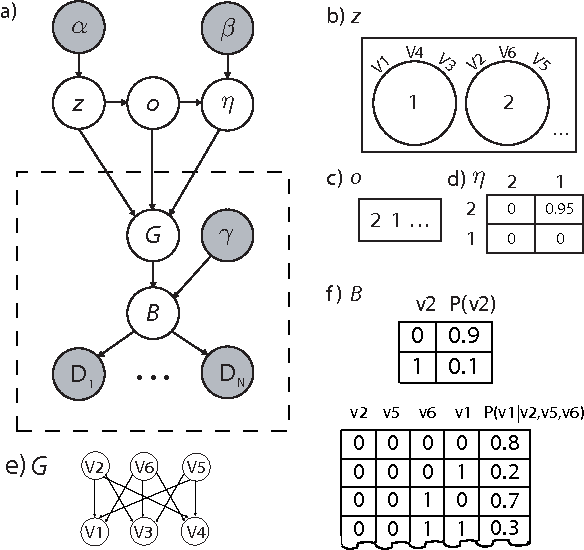
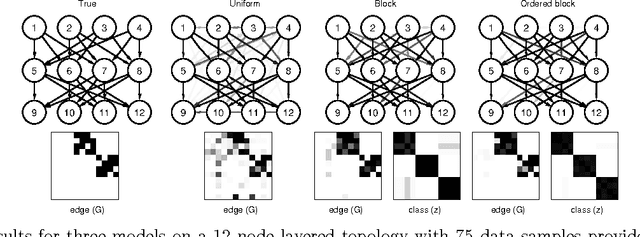
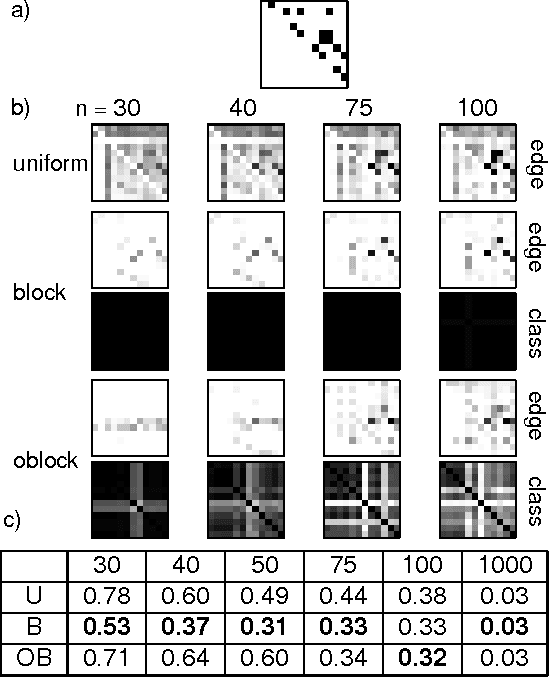
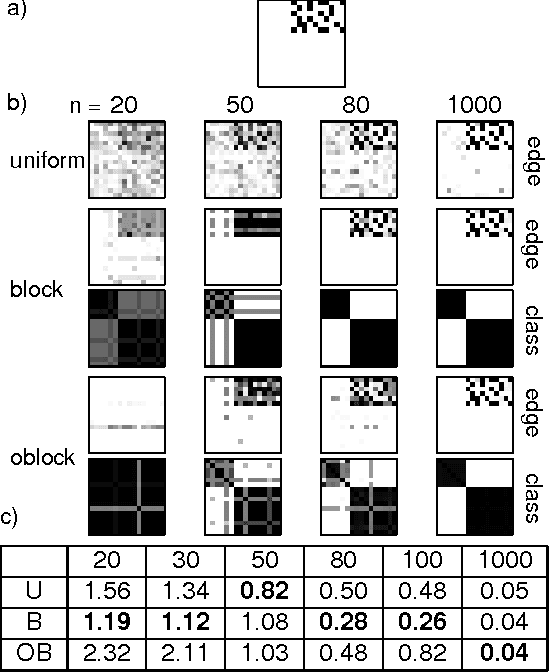
Traditional approaches to Bayes net structure learning typically assume little regularity in graph structure other than sparseness. However, in many cases, we expect more systematicity: variables in real-world systems often group into classes that predict the kinds of probabilistic dependencies they participate in. Here we capture this form of prior knowledge in a hierarchical Bayesian framework, and exploit it to enable structure learning and type discovery from small datasets. Specifically, we present a nonparametric generative model for directed acyclic graphs as a prior for Bayes net structure learning. Our model assumes that variables come in one or more classes and that the prior probability of an edge existing between two variables is a function only of their classes. We derive an MCMC algorithm for simultaneous inference of the number of classes, the class assignments of variables, and the Bayes net structure over variables. For several realistic, sparse datasets, we show that the bias towards systematicity of connections provided by our model yields more accurate learned networks than a traditional, uniform prior approach, and that the classes found by our model are appropriate.