 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreat Power, Great Responsibility: Recommendations for Reducing Energy for Training Language Models
May 19, 2022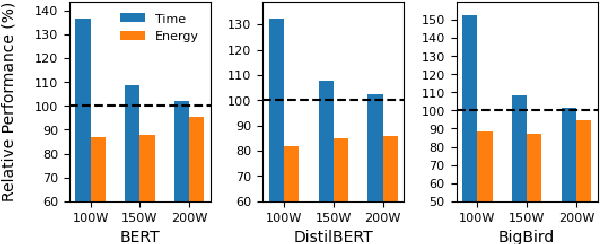

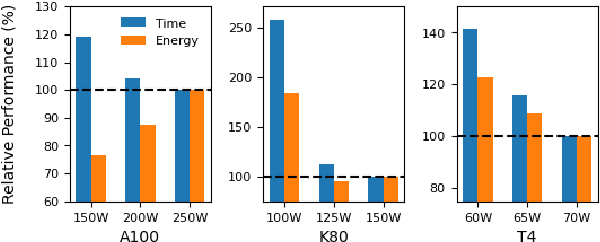
The energy requirements of current natural language processing models continue to grow at a rapid, unsustainable pace. Recent works highlighting this problem conclude there is an urgent need for methods that reduce the energy needs of NLP and machine learning more broadly. In this article, we investigate techniques that can be used to reduce the energy consumption of common NLP applications. In particular, we focus on techniques to measure energy usage and different hardware and datacenter-oriented settings that can be tuned to reduce energy consumption for training and inference for language models. We characterize the impact of these settings on metrics such as computational performance and energy consumption through experiments conducted on a high performance computing system as well as popular cloud computing platforms. These techniques can lead to significant reduction in energy consumption when training language models or their use for inference. For example, power-capping, which limits the maximum power a GPU can consume, can enable a 15\% decrease in energy usage with marginal increase in overall computation time when training a transformer-based language model.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
Benchmarking Resource Usage for Efficient Distributed Deep Learning
Jan 28, 2022



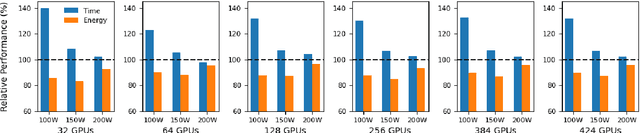
Deep learning (DL) workflows demand an ever-increasing budget of compute and energy in order to achieve outsized gains. Neural architecture searches, hyperparameter sweeps, and rapid prototyping consume immense resources that can prevent resource-constrained researchers from experimenting with large models and carry considerable environmental impact. As such, it becomes essential to understand how different deep neural networks (DNNs) and training leverage increasing compute and energy resources -- especially specialized computationally-intensive models across different domains and applications. In this paper, we conduct over 3,400 experiments training an array of deep networks representing various domains/tasks -- natural language processing, computer vision, and chemistry -- on up to 424 graphics processing units (GPUs). During training, our experiments systematically vary compute resource characteristics and energy-saving mechanisms such as power utilization and GPU clock rate limits to capture and illustrate the different trade-offs and scaling behaviors each representative model exhibits under various resource and energy-constrained regimes. We fit power law models that describe how training time scales with available compute resources and energy constraints. We anticipate that these findings will help inform and guide high-performance computing providers in optimizing resource utilization, by selectively reducing energy consumption for different deep learning tasks/workflows with minimal impact on training.
FastFlows: Flow-Based Models for Molecular Graph Generation
Jan 28, 2022



We propose a framework using normalizing-flow based models, SELF-Referencing Embedded Strings, and multi-objective optimization that efficiently generates small molecules. With an initial training set of only 100 small molecules, FastFlows generates thousands of chemically valid molecules in seconds. Because of the efficient sampling, substructure filters can be applied as desired to eliminate compounds with unreasonable moieties. Using easily computable and learned metrics for druglikeness, synthetic accessibility, and synthetic complexity, we perform a multi-objective optimization to demonstrate how FastFlows functions in a high-throughput virtual screening context. Our model is significantly simpler and easier to train than autoregressive molecular generative models, and enables fast generation and identification of druglike, synthesizable molecules.
Bringing Atomistic Deep Learning to Prime Time
Dec 09, 2021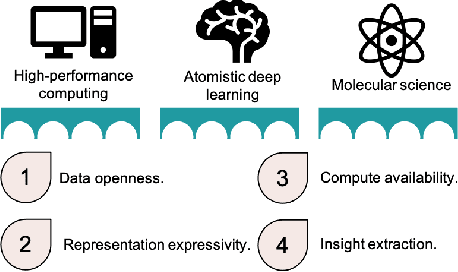
Artificial intelligence has not yet revolutionized the design of materials and molecules. In this perspective, we identify four barriers preventing the integration of atomistic deep learning, molecular science, and high-performance computing. We outline focused research efforts to address the opportunities presented by these challenges.
Scalable Geometric Deep Learning on Molecular Graphs
Dec 06, 2021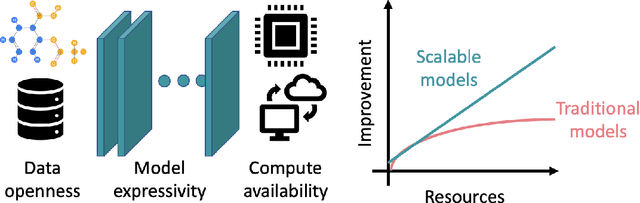

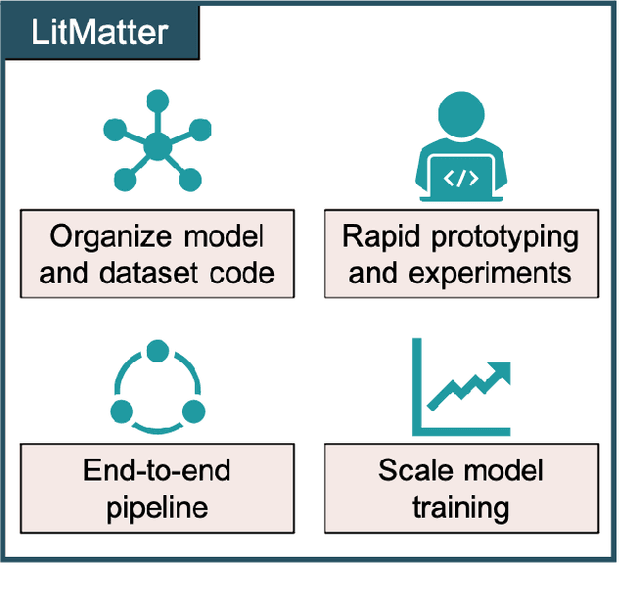
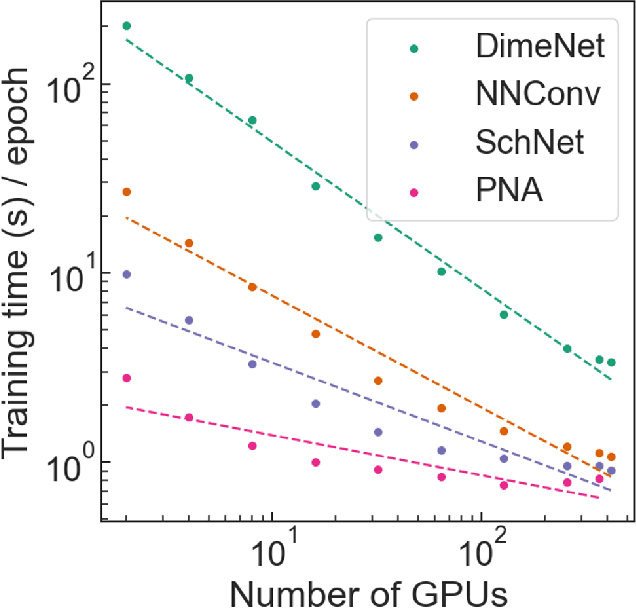
Deep learning in molecular and materials sciences is limited by the lack of integration between applied science, artificial intelligence, and high-performance computing. Bottlenecks with respect to the amount of training data, the size and complexity of model architectures, and the scale of the compute infrastructure are all key factors limiting the scaling of deep learning for molecules and materials. Here, we present $\textit{LitMatter}$, a lightweight framework for scaling molecular deep learning methods. We train four graph neural network architectures on over 400 GPUs and investigate the scaling behavior of these methods. Depending on the model architecture, training time speedups up to $60\times$ are seen. Empirical neural scaling relations quantify the model-dependent scaling and enable optimal compute resource allocation and the identification of scalable molecular geometric deep learning model implementations.
The Pseudo Projection Operator: Applications of Deep Learning to Projection Based Filtering in Non-Trivial Frequency Regimes
Nov 13, 2021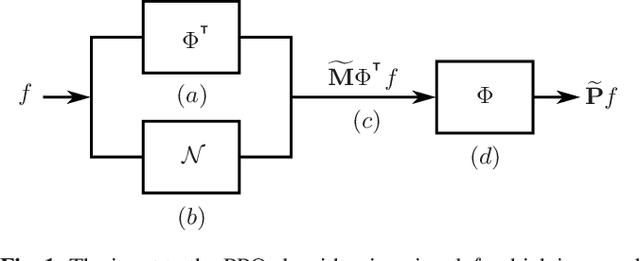
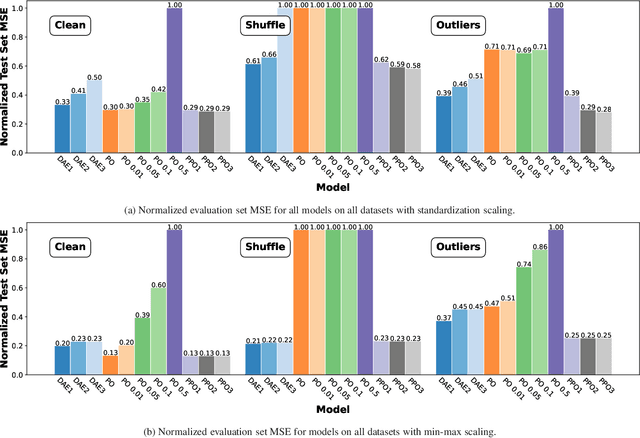
Traditional frequency based projection filters, or projection operators (PO), separate signal and noise through a series of transformations which remove frequencies where noise is present. However, this technique relies on a priori knowledge of what frequencies contain signal and noise and that these frequencies do not overlap, which is difficult to achieve in practice. To address these issues, we introduce a PO-neural network hybrid model, the Pseudo Projection Operator (PPO), which leverages a neural network to perform frequency selection. We compare the filtering capabilities of a PPO, PO, and denoising autoencoder (DAE) on the University of Rochester Multi-Modal Music Performance Dataset with a variety of added noise types. In the majority of experiments, the PPO outperforms both the PO and DAE. Based upon these results, we suggest future application of the PPO to filtering problems in the physical and biological sciences.
AI Accelerator Survey and Trends
Sep 18, 2021
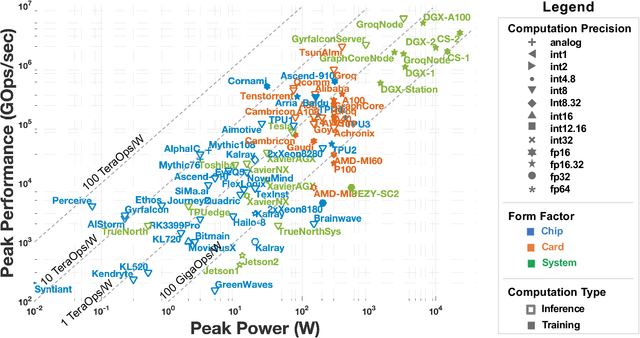
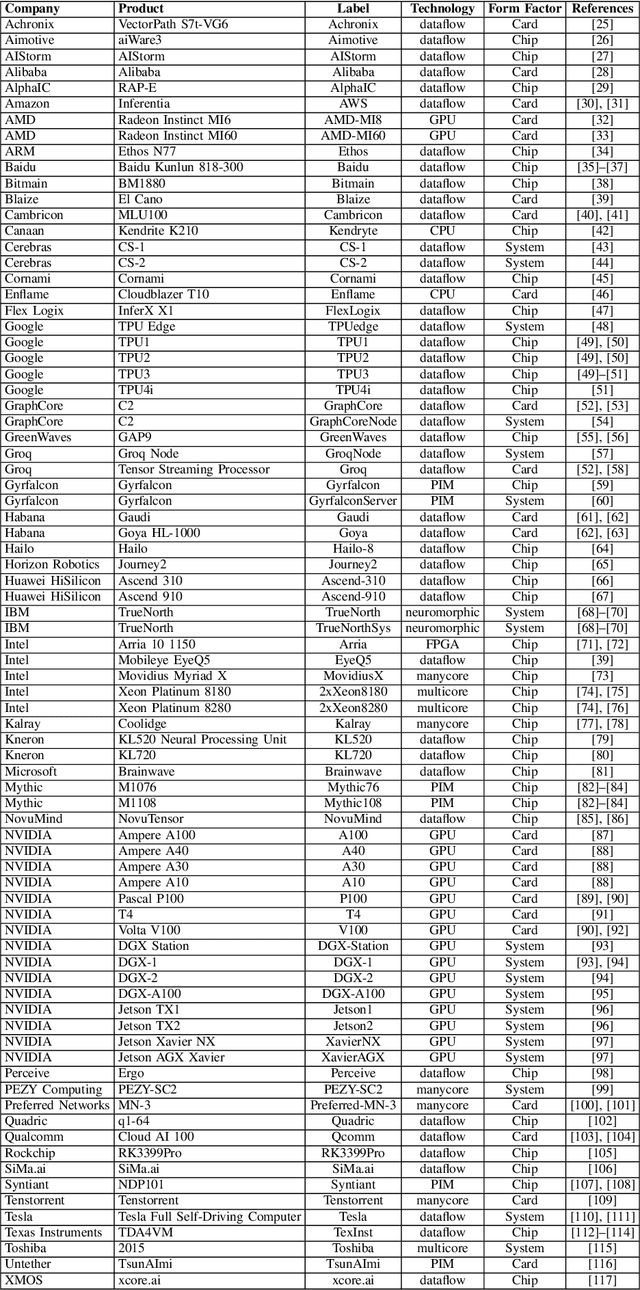
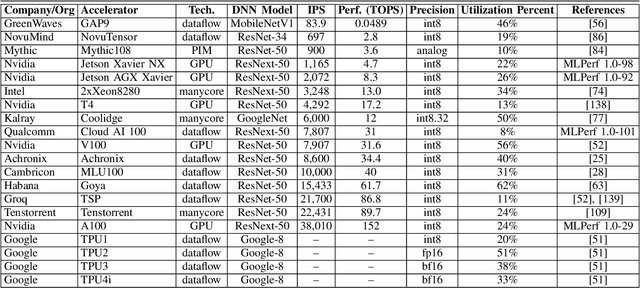
Over the past several years, new machine learning accelerators were being announced and released every month for a variety of applications from speech recognition, video object detection, assisted driving, and many data center applications. This paper updates the survey of AI accelerators and processors from past two years. This paper collects and summarizes the current commercial accelerators that have been publicly announced with peak performance and power consumption numbers. The performance and power values are plotted on a scatter graph, and a number of dimensions and observations from the trends on this plot are again discussed and analyzed. This year, we also compile a list of benchmarking performance results and compute the computational efficiency with respect to peak performance.
Maneuver Identification Challenge
Aug 25, 2021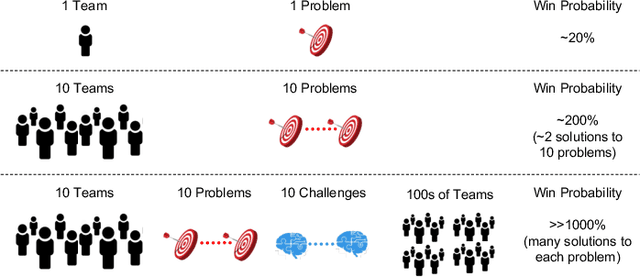
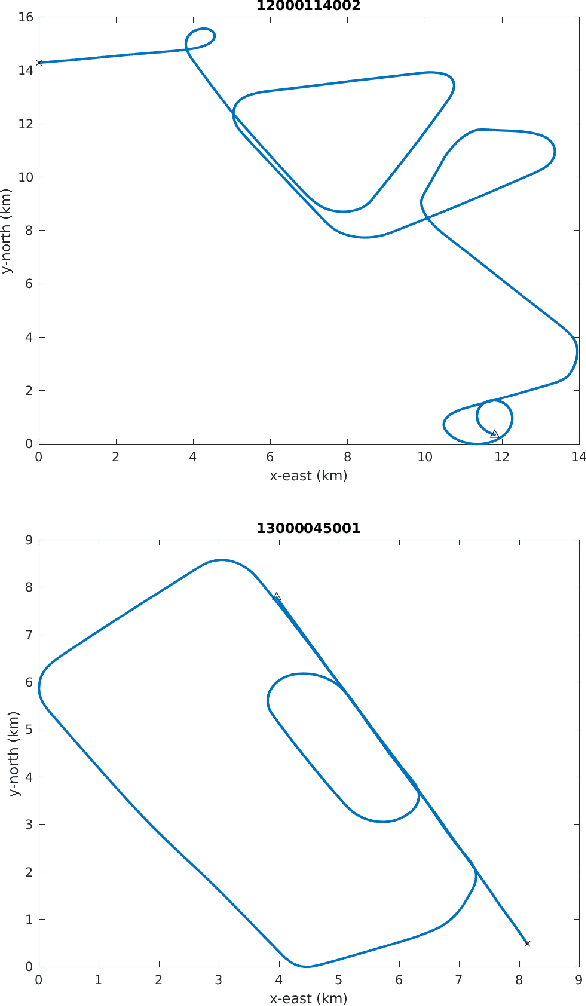
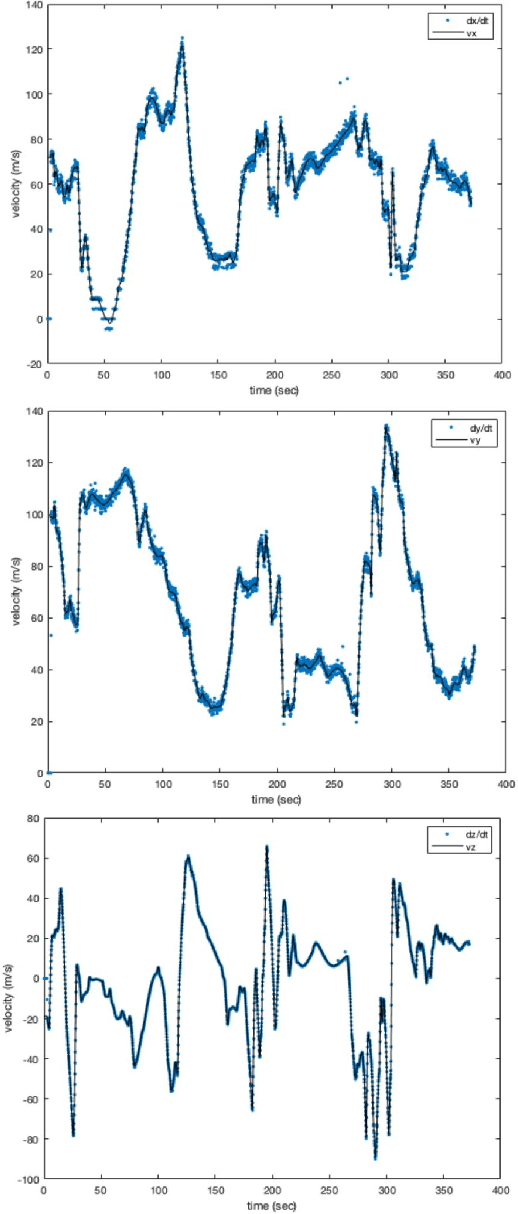

AI algorithms that identify maneuvers from trajectory data could play an important role in improving flight safety and pilot training. AI challenges allow diverse teams to work together to solve hard problems and are an effective tool for developing AI solutions. AI challenges are also a key driver of AI computational requirements. The Maneuver Identification Challenge hosted at maneuver-id.mit.edu provides thousands of trajectories collected from pilots practicing in flight simulators, descriptions of maneuvers, and examples of these maneuvers performed by experienced pilots. Each trajectory consists of positions, velocities, and aircraft orientations normalized to a common coordinate system. Construction of the data set required significant data architecture to transform flight simulator logs into AI ready data, which included using a supercomputer for deduplication and data conditioning. There are three proposed challenges. The first challenge is separating physically plausible (good) trajectories from unfeasible (bad) trajectories. Human labeled good and bad trajectories are provided to aid in this task. Subsequent challenges are to label trajectories with their intended maneuvers and to assess the quality of those maneuvers.
The MIT Supercloud Dataset
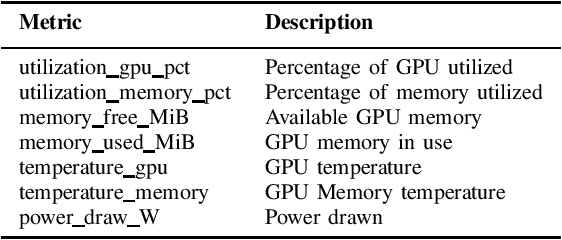
Aug 04, 2021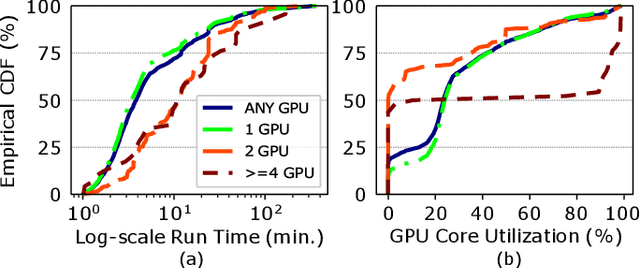
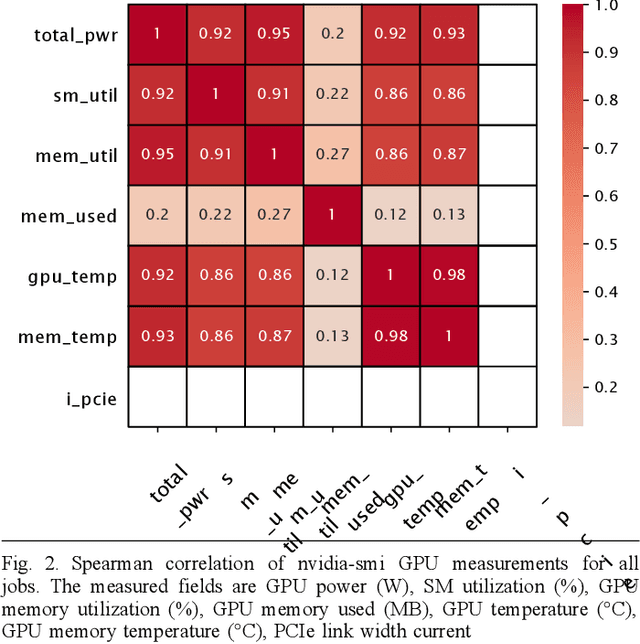
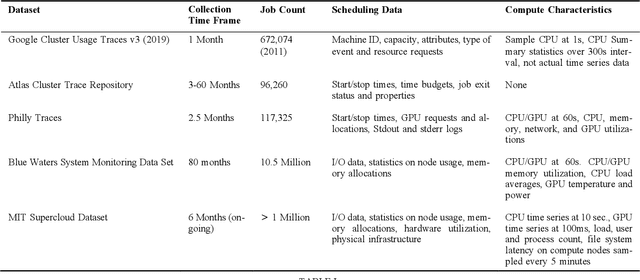

Artificial intelligence (AI) and Machine learning (ML) workloads are an increasingly larger share of the compute workloads in traditional High-Performance Computing (HPC) centers and commercial cloud systems. This has led to changes in deployment approaches of HPC clusters and the commercial cloud, as well as a new focus on approaches to optimized resource usage, allocations and deployment of new AI frame- works, and capabilities such as Jupyter notebooks to enable rapid prototyping and deployment. With these changes, there is a need to better understand cluster/datacenter operations with the goal of developing improved scheduling policies, identifying inefficiencies in resource utilization, energy/power consumption, failure prediction, and identifying policy violations. In this paper we introduce the MIT Supercloud Dataset which aims to foster innovative AI/ML approaches to the analysis of large scale HPC and datacenter/cloud operations. We provide detailed monitoring logs from the MIT Supercloud system, which include CPU and GPU usage by jobs, memory usage, file system logs, and physical monitoring data. This paper discusses the details of the dataset, collection methodology, data availability, and discusses potential challenge problems being developed using this data. Datasets and future challenge announcements will be available via https://dcc.mit.edu.