 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-Based Modeling of Human Clothing
Apr 22, 2021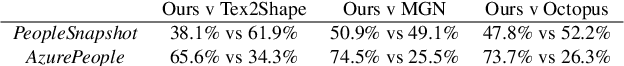
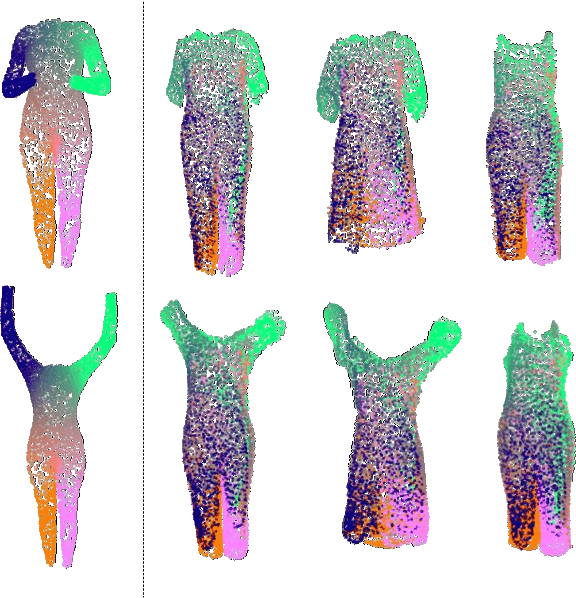
We propose a new approach to human clothing modeling based on point clouds. Within this approach, we learn a deep model that can predict point clouds of various outfits, for various human poses and for various human body shapes. Notably, outfits of various types and topologies can be handled by the same model. Using the learned model, we can infer geometry of new outfits from as little as a singe image, and perform outfit retargeting to new bodies in new poses. We complement our geometric model with appearance modeling that uses the point cloud geometry as a geometric scaffolding, and employs neural point-based graphics to capture outfit appearance from videos and to re-render the captured outfits. We validate both geometric modeling and appearance modeling aspects of the proposed approach against recently proposed methods, and establish the viability of point-based clothing modeling.
StylePeople: A Generative Model of Fullbody Human Avatars
Apr 16, 2021

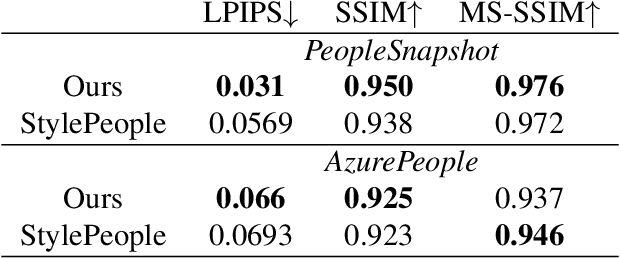
We propose a new type of full-body human avatars, which combines parametric mesh-based body model with a neural texture. We show that with the help of neural textures, such avatars can successfully model clothing and hair, which usually poses a problem for mesh-based approaches. We also show how these avatars can be created from multiple frames of a video using backpropagation. We then propose a generative model for such avatars that can be trained from datasets of images and videos of people. The generative model allows us to sample random avatars as well as to create dressed avatars of people from one or few images. The code for the project is available at saic-violet.github.io/style-people.
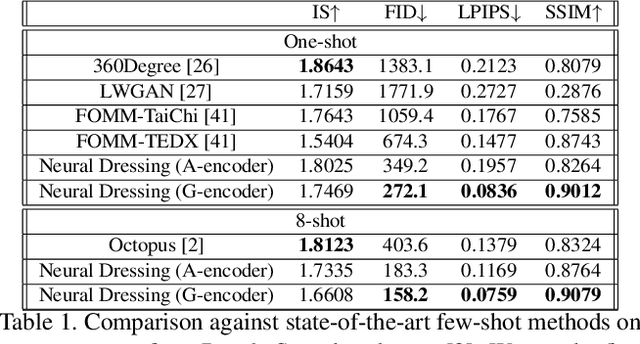
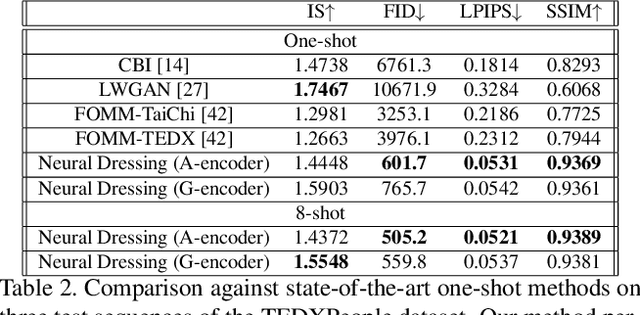
Real-time RGBD-based Extended Body Pose Estimation
Mar 05, 2021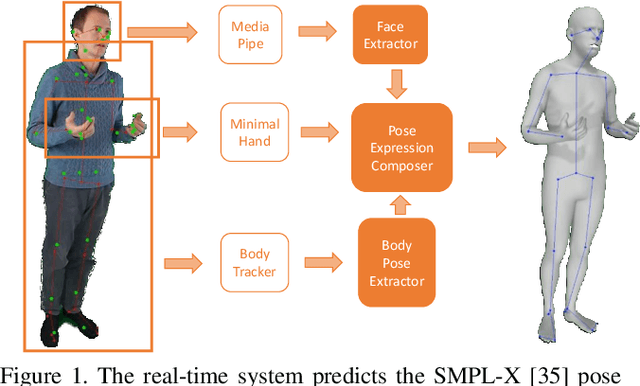
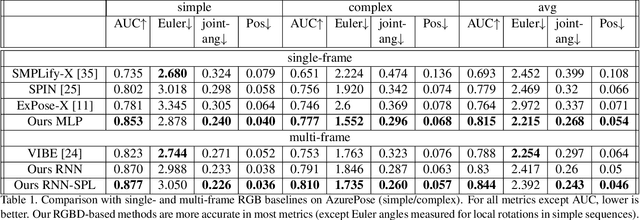
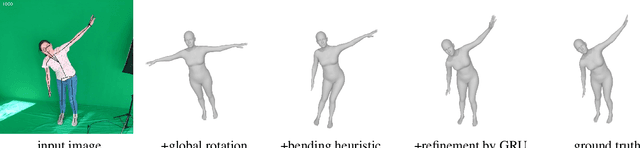
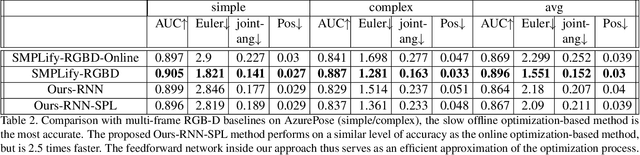
We present a system for real-time RGBD-based estimation of 3D human pose. We use parametric 3D deformable human mesh model (SMPL-X) as a representation and focus on the real-time estimation of parameters for the body pose, hands pose and facial expression from Kinect Azure RGB-D camera. We train estimators of body pose and facial expression parameters. Both estimators use previously published landmark extractors as input and custom annotated datasets for supervision, while hand pose is estimated directly by a previously published method. We combine the predictions of those estimators into a temporally-smooth human pose. We train the facial expression extractor on a large talking face dataset, which we annotate with facial expression parameters. For the body pose we collect and annotate a dataset of 56 people captured from a rig of 5 Kinect Azure RGB-D cameras and use it together with a large motion capture AMASS dataset. Our RGB-D body pose model outperforms the state-of-the-art RGB-only methods and works on the same level of accuracy compared to a slower RGB-D optimization-based solution. The combined system runs at 30 FPS on a server with a single GPU. The code will be available at https://saic-violet.github.io/rgbd-kinect-pose
CNN with large memory layers
Jan 27, 2021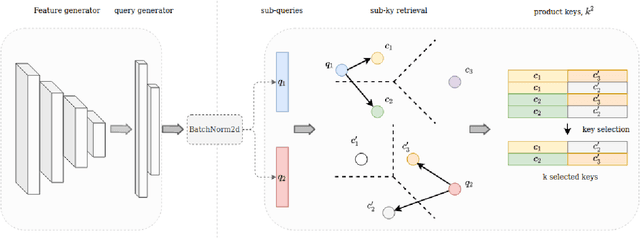
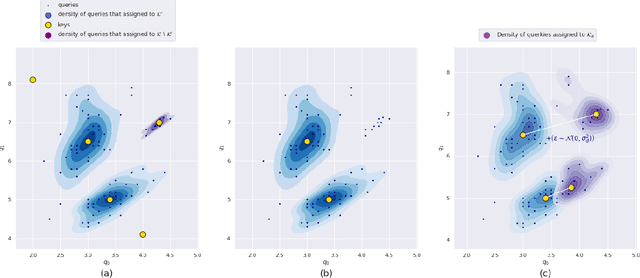
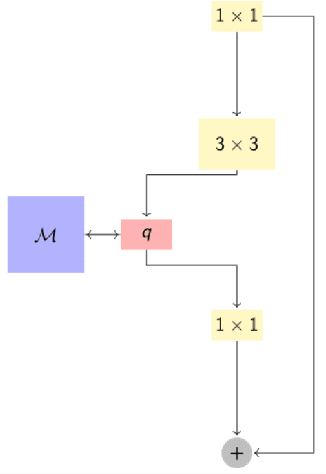
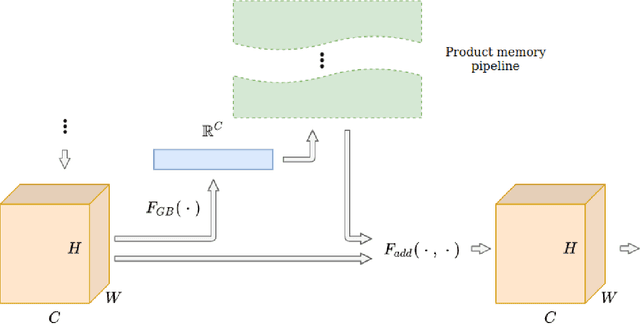
This work is centred around the recently proposed product key memory structure \cite{large_memory}, implemented for a number of computer vision applications. The memory structure can be regarded as a simple computation primitive suitable to be augmented to nearly all neural network architectures. The memory block allows implementing sparse access to memory with square root complexity scaling with respect to the memory capacity. The latter scaling is possible due to the incorporation of Cartesian product space decomposition of the key space for the nearest neighbour search. We have tested the memory layer on the classification, image reconstruction and relocalization problems and found that for some of those, the memory layers can provide significant speed/accuracy improvement with the high utilization of the key-value elements, while others require more careful fine-tuning and suffer from dying keys. To tackle the later problem we have introduced a simple technique of memory re-initialization which helps us to eliminate unused key-value pairs from the memory and engage them in training again. We have conducted various experiments and got improvements in speed and accuracy for classification and PoseNet relocalization models. We showed that the re-initialization has a huge impact on a toy example of randomly labeled data and observed some gains in performance on the image classification task. We have also demonstrated the generalization property perseverance of the large memory layers on the relocalization problem, while observing the spatial correlations between the images and the selected memory cells.
Relightable 3D Head Portraits from a Smartphone Video
Dec 17, 2020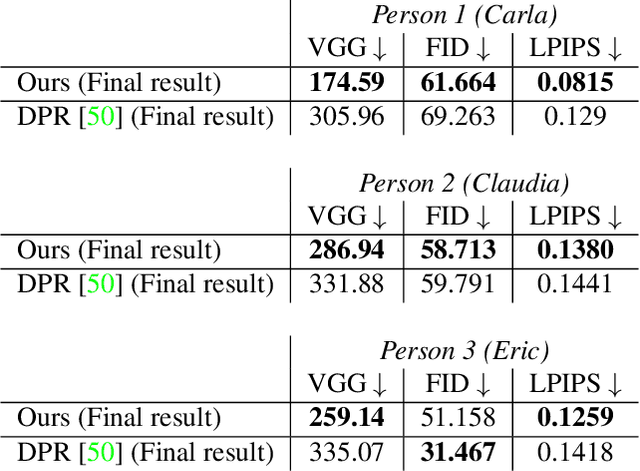
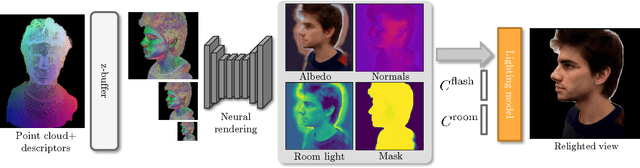


In this work, a system for creating a relightable 3D portrait of a human head is presented. Our neural pipeline operates on a sequence of frames captured by a smartphone camera with the flash blinking (flash-no flash sequence). A coarse point cloud reconstructed via structure-from-motion software and multi-view denoising is then used as a geometric proxy. Afterwards, a deep rendering network is trained to regress dense albedo, normals, and environmental lighting maps for arbitrary new viewpoints. Effectively, the proxy geometry and the rendering network constitute a relightable 3D portrait model, that can be synthesized from an arbitrary viewpoint and under arbitrary lighting, e.g. directional light, point light, or an environment map. The model is fitted to the sequence of frames with human face-specific priors that enforce the plausibility of albedo-lighting decomposition and operates at the interactive frame rate. We evaluate the performance of the method under varying lighting conditions and at the extrapolated viewpoints and compare with existing relighting methods.
Image Generators with Conditionally-Independent Pixel Synthesis
Nov 27, 2020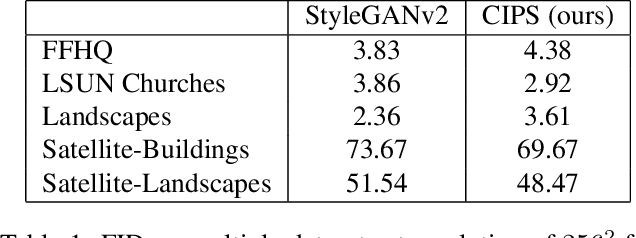
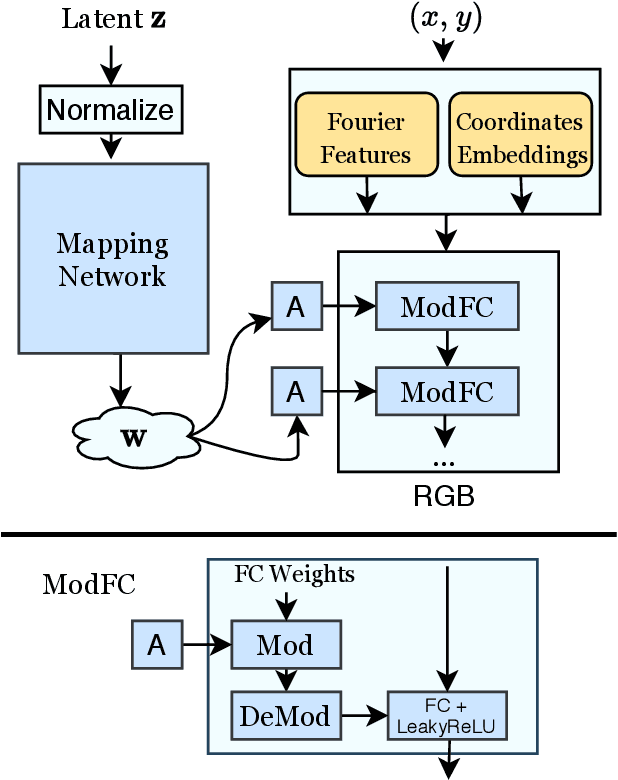
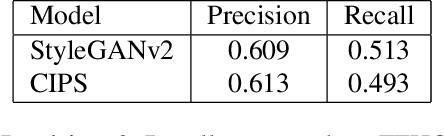
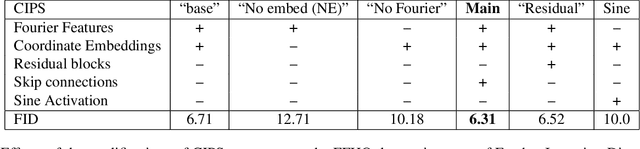
Existing image generator networks rely heavily on spatial convolutions and, optionally, self-attention blocks in order to gradually synthesize images in a coarse-to-fine manner. Here, we present a new architecture for image generators, where the color value at each pixel is computed independently given the value of a random latent vector and the coordinate of that pixel. No spatial convolutions or similar operations that propagate information across pixels are involved during the synthesis. We analyze the modeling capabilities of such generators when trained in an adversarial fashion, and observe the new generators to achieve similar generation quality to state-of-the-art convolutional generators. We also investigate several interesting properties unique to the new architecture.
TRANSPR: Transparency Ray-Accumulating Neural 3D Scene Point Renderer
Sep 06, 2020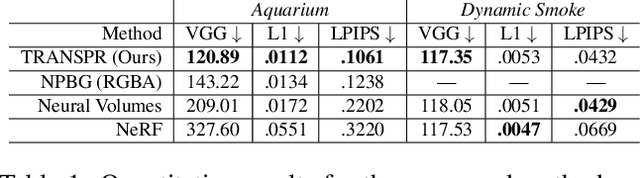
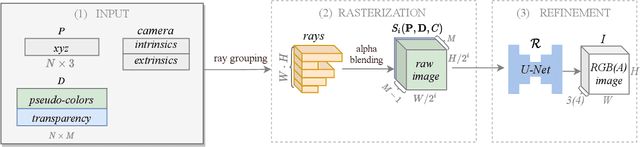
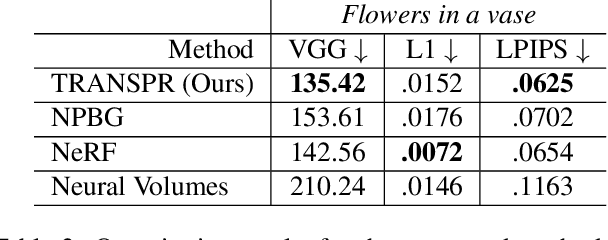
We propose and evaluate a neural point-based graphics method that can model semi-transparent scene parts. Similarly to its predecessor pipeline, ours uses point clouds to model proxy geometry, and augments each point with a neural descriptor. Additionally, a learnable transparency value is introduced in our approach for each point. Our neural rendering procedure consists of two steps. Firstly, the point cloud is rasterized using ray grouping into a multi-channel image. This is followed by the neural rendering step that "translates" the rasterized image into an RGB output using a learnable convolutional network. New scenes can be modeled using gradient-based optimization of neural descriptors and of the rendering network. We show that novel views of semi-transparent point cloud scenes can be generated after training with our approach. Our experiments demonstrate the benefit of introducing semi-transparency into the neural point-based modeling for a range of scenes with semi-transparent parts.
Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars
Aug 24, 2020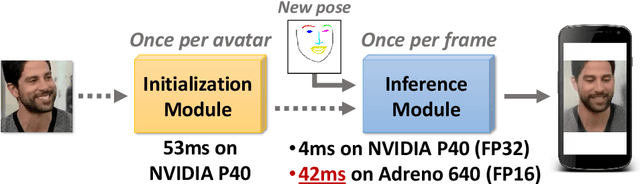
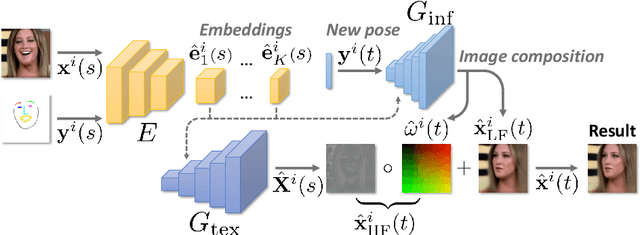
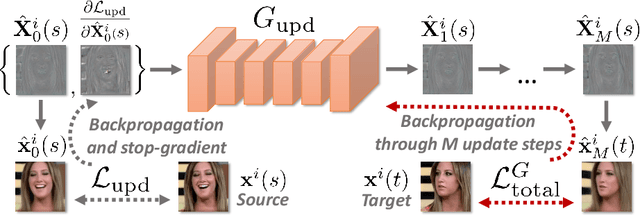
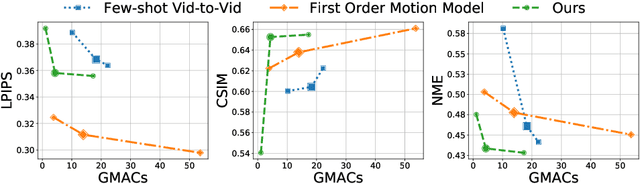
We propose a neural rendering-based system that creates head avatars from a single photograph. Our approach models a person's appearance by decomposing it into two layers. The first layer is a pose-dependent coarse image that is synthesized by a small neural network. The second layer is defined by a pose-independent texture image that contains high-frequency details. The texture image is generated offline, warped and added to the coarse image to ensure a high effective resolution of synthesized head views. We compare our system to analogous state-of-the-art systems in terms of visual quality and speed. The experiments show significant inference speedup over previous neural head avatar models for a given visual quality. We also report on a real-time smartphone-based implementation of our system.
DeepLandscape: Adversarial Modeling of Landscape Video
Aug 21, 2020
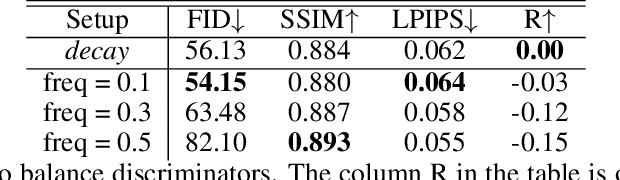
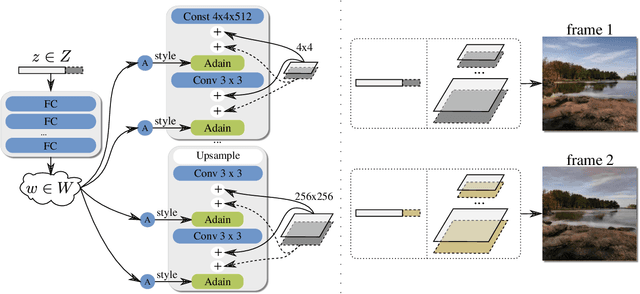
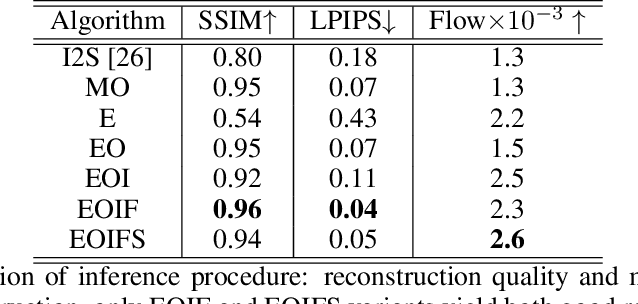
We build a new model of landscape videos that can be trained on a mixture of static landscape images as well as landscape animations. Our architecture extends StyleGAN model by augmenting it with parts that allow to model dynamic changes in a scene. Once trained, our model can be used to generate realistic time-lapse landscape videos with moving objects and time-of-the-day changes. Furthermore, by fitting the learned models to a static landscape image, the latter can be reenacted in a realistic way. We propose simple but necessary modifications to StyleGAN inversion procedure, which lead to in-domain latent codes and allow to manipulate real images. Quantitative comparisons and user studies suggest that our model produces more compelling animations of given photographs than previously proposed methods. The results of our approach including comparisons with prior art can be seen in supplementary materials and on the project page https://saic-mdal.github.io/deep-landscape
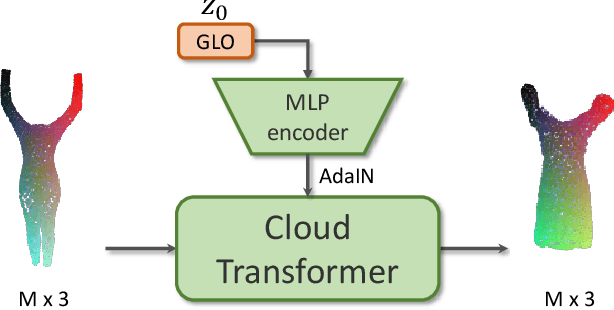
Cloud Transformers
Jul 22, 2020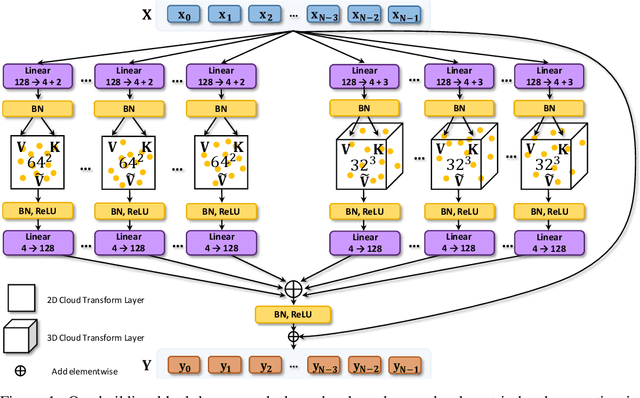
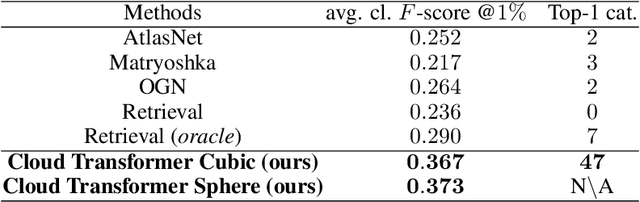
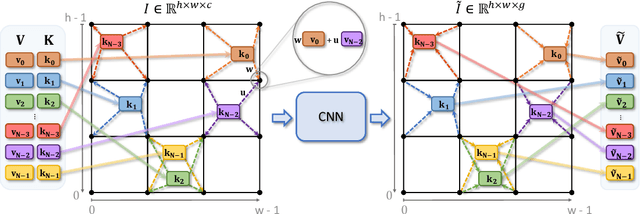
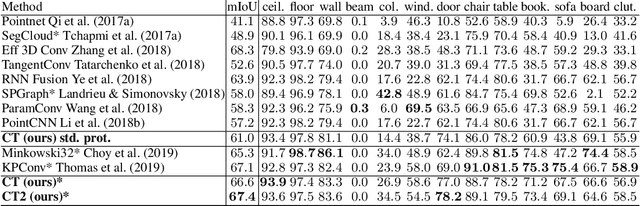
We present a new versatile building block for deep point cloud processing architectures. This building block combines the ideas of self-attention layers from the transformer architecture with the efficiency of standard convolutional layers in two and three-dimensional dense grids. The new block operates via multiple parallel heads, whereas each head projects feature representations of individual points into a low-dimensional space, treats the first two or three dimensions as spatial coordinates and then uses dense convolution to propagate information across points. The results of the processing of individual heads are then combined together resulting in the update of point features. Using the new block, we build architectures for point cloud segmentation as well as for image-based point cloud reconstruction. We show that despite the dissimilarity between these tasks, the resulting architectures achieve state-of-the-art performance for both of them demonstrating the versatility of the new block.