 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysHead: Simulation-Ready Gaussian Head Avatars
Apr 07, 2026Realistic digital avatars require expressive and dynamic hair motion; however, most existing head avatar methods assume rigid hair movement. These methods often fail to disentangle hair from the head, representing it as a simple outer shell and failing to capture its natural volumetric behavior. In this paper, we address these limitations by introducing PhysHead, a hybrid representation for animatable head avatars with realistic hair dynamics learned from multi-view video. At the core is a 3D Gaussian-based layered representation of the head. Our approach combines a 3D parametric mesh for the head with strand-based hair, which can be directly simulated using physics engines. For the appearance model, we employ Gaussian primitives attached to both the head mesh and hair segments. This representation enables the creation of photorealistic head avatars with dynamic hair behavior, such as wind-blown motion, overcoming the constraints of rigid hair in existing methods. However, these animation capabilities also require new training schemes. In particular, we propose the use of VLM-based models to generate appearance of regions that are occluded in the dynamic training sequences. In quantitative and qualitative studies, we demonstrate the capabilities of the proposed model and compare it with existing baselines. We show that our method can synthesize physically plausible hair motion besides expression and camera control.
NeuralFur: Animal Fur Reconstruction From Multi-View Images
Jan 18, 2026Reconstructing realistic animal fur geometry from images is a challenging task due to the fine-scale details, self-occlusion, and view-dependent appearance of fur. In contrast to human hairstyle reconstruction, there are also no datasets that can be leveraged to learn a fur prior for different animals. In this work, we present a first multi-view-based method for high-fidelity 3D fur modeling of animals using a strand-based representation, leveraging the general knowledge of a vision language model. Given multi-view RGB images, we first reconstruct a coarse surface geometry using traditional multi-view stereo techniques. We then use a vision language model (VLM) system to retrieve information about the realistic length structure of the fur for each part of the body. We use this knowledge to construct the animal's furless geometry and grow strands atop it. The fur reconstruction is supervised with both geometric and photometric losses computed from multi-view images. To mitigate orientation ambiguities stemming from the Gabor filters that are applied to the input images, we additionally utilize the VLM to guide the strands' growth direction and their relation to the gravity vector that we incorporate as a loss. With this new schema of using a VLM to guide 3D reconstruction from multi-view inputs, we show generalization across a variety of animals with different fur types. For additional results and code, please refer to https://neuralfur.is.tue.mpg.de.
GeomHair: Reconstruction of Hair Strands from Colorless 3D Scans
May 08, 2025We propose a novel method that reconstructs hair strands directly from colorless 3D scans by leveraging multi-modal hair orientation extraction. Hair strand reconstruction is a fundamental problem in computer vision and graphics that can be used for high-fidelity digital avatar synthesis, animation, and AR/VR applications. However, accurately recovering hair strands from raw scan data remains challenging due to human hair's complex and fine-grained structure. Existing methods typically rely on RGB captures, which can be sensitive to the environment and can be a challenging domain for extracting the orientation of guiding strands, especially in the case of challenging hairstyles. To reconstruct the hair purely from the observed geometry, our method finds sharp surface features directly on the scan and estimates strand orientation through a neural 2D line detector applied to the renderings of scan shading. Additionally, we incorporate a diffusion prior trained on a diverse set of synthetic hair scans, refined with an improved noise schedule, and adapted to the reconstructed contents via a scan-specific text prompt. We demonstrate that this combination of supervision signals enables accurate reconstruction of both simple and intricate hairstyles without relying on color information. To facilitate further research, we introduce Strands400, the largest publicly available dataset of hair strands with detailed surface geometry extracted from real-world data, which contains reconstructed hair strands from the scans of 400 subjects.
Joker: Conditional 3D Head Synthesis with Extreme Facial Expressions
Oct 21, 2024



We introduce Joker, a new method for the conditional synthesis of 3D human heads with extreme expressions. Given a single reference image of a person, we synthesize a volumetric human head with the reference identity and a new expression. We offer control over the expression via a 3D morphable model (3DMM) and textual inputs. This multi-modal conditioning signal is essential since 3DMMs alone fail to define subtle emotional changes and extreme expressions, including those involving the mouth cavity and tongue articulation. Our method is built upon a 2D diffusion-based prior that generalizes well to out-of-domain samples, such as sculptures, heavy makeup, and paintings while achieving high levels of expressiveness. To improve view consistency, we propose a new 3D distillation technique that converts predictions of our 2D prior into a neural radiance field (NeRF). Both the 2D prior and our distillation technique produce state-of-the-art results, which are confirmed by our extensive evaluations. Also, to the best of our knowledge, our method is the first to achieve view-consistent extreme tongue articulation.
HAAR: Text-Conditioned Generative Model of 3D Strand-based Human Hairstyles
Dec 18, 2023We present HAAR, a new strand-based generative model for 3D human hairstyles. Specifically, based on textual inputs, HAAR produces 3D hairstyles that could be used as production-level assets in modern computer graphics engines. Current AI-based generative models take advantage of powerful 2D priors to reconstruct 3D content in the form of point clouds, meshes, or volumetric functions. However, by using the 2D priors, they are intrinsically limited to only recovering the visual parts. Highly occluded hair structures can not be reconstructed with those methods, and they only model the ''outer shell'', which is not ready to be used in physics-based rendering or simulation pipelines. In contrast, we propose a first text-guided generative method that uses 3D hair strands as an underlying representation. Leveraging 2D visual question-answering (VQA) systems, we automatically annotate synthetic hair models that are generated from a small set of artist-created hairstyles. This allows us to train a latent diffusion model that operates in a common hairstyle UV space. In qualitative and quantitative studies, we demonstrate the capabilities of the proposed model and compare it to existing hairstyle generation approaches.
Neural Haircut: Prior-Guided Strand-Based Hair Reconstruction
Jun 12, 2023



Generating realistic human 3D reconstructions using image or video data is essential for various communication and entertainment applications. While existing methods achieved impressive results for body and facial regions, realistic hair modeling still remains challenging due to its high mechanical complexity. This work proposes an approach capable of accurate hair geometry reconstruction at a strand level from a monocular video or multi-view images captured in uncontrolled lighting conditions. Our method has two stages, with the first stage performing joint reconstruction of coarse hair and bust shapes and hair orientation using implicit volumetric representations. The second stage then estimates a strand-level hair reconstruction by reconciling in a single optimization process the coarse volumetric constraints with hair strand and hairstyle priors learned from the synthetic data. To further increase the reconstruction fidelity, we incorporate image-based losses into the fitting process using a new differentiable renderer. The combined system, named Neural Haircut, achieves high realism and personalization of the reconstructed hairstyles.
Realistic One-shot Mesh-based Head Avatars
Jun 16, 2022
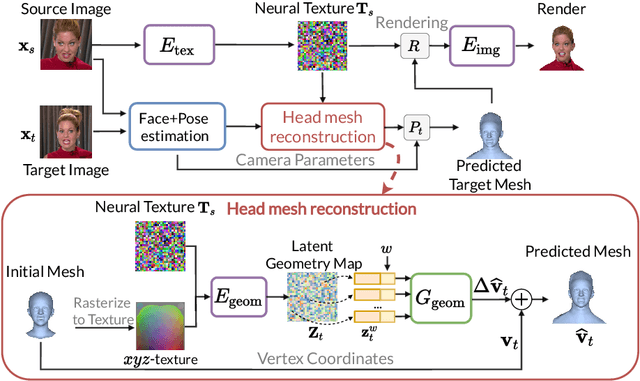
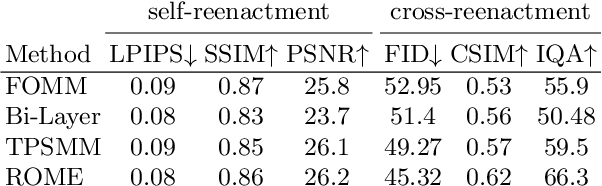
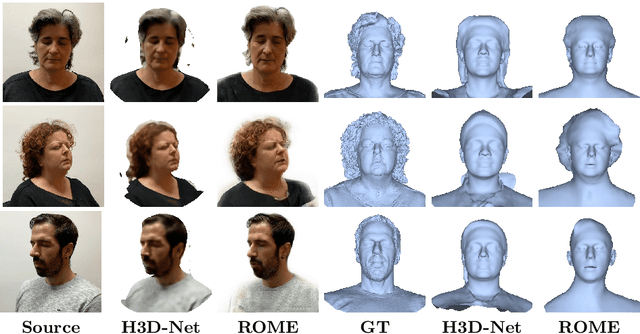
We present a system for realistic one-shot mesh-based human head avatars creation, ROME for short. Using a single photograph, our model estimates a person-specific head mesh and the associated neural texture, which encodes both local photometric and geometric details. The resulting avatars are rigged and can be rendered using a neural network, which is trained alongside the mesh and texture estimators on a dataset of in-the-wild videos. In the experiments, we observe that our system performs competitively both in terms of head geometry recovery and the quality of renders, especially for the cross-person reenactment. See results https://samsunglabs.github.io/rome/