 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring diversity of synthetic prompts and data generated with fine-grained persona prompting
May 23, 2025



Fine-grained personas have recently been used for generating 'diverse' synthetic data for pre-training and supervised fine-tuning of Large Language Models (LLMs). In this work, we measure the diversity of persona-driven synthetically generated prompts and responses with a suite of lexical diversity and redundancy metrics. Firstly, we find that synthetic prompts/instructions are significantly less diverse than human-written ones. Next, we sample responses from LLMs of different sizes with fine-grained and coarse persona descriptions to investigate how much fine-grained detail in persona descriptions contribute to generated text diversity. We find that while persona-prompting does improve lexical diversity (especially with larger models), fine-grained detail in personas doesn't increase diversity noticeably.
Promoting Constructive Deliberation: Reframing for Receptiveness
May 23, 2024To promote constructive discussion of controversial topics online, we propose automatic reframing of disagreeing responses to signal receptiveness while preserving meaning. Drawing on research from psychology, communications, and linguistics, we identify six strategies for reframing. We automatically reframe replies according to each strategy, using a dataset of Reddit comments and replies. Through human-centered experiments, we find that the replies generated with our framework are perceived to be significantly more receptive than the original replies, as well as a generic receptiveness baseline. We analyze and discuss the implications of our results and highlight applications to content moderation. Overall, we illustrate how transforming receptiveness, a particular social science construct, into a computational framework, can make LLM generations more aligned with human perceptions.
Chord Embeddings: Analyzing What They Capture and Their Role for Next Chord Prediction and Artist Attribute Prediction
Feb 04, 2021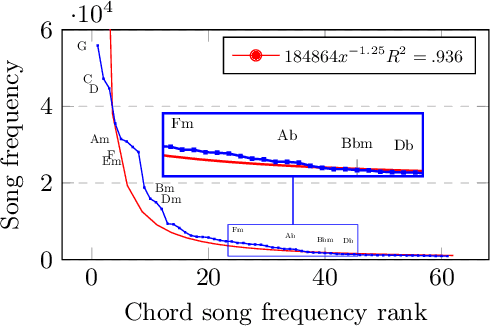
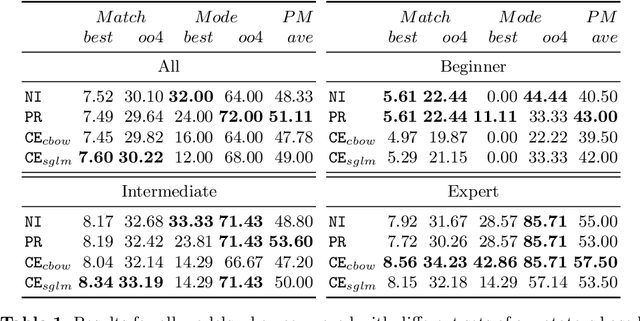
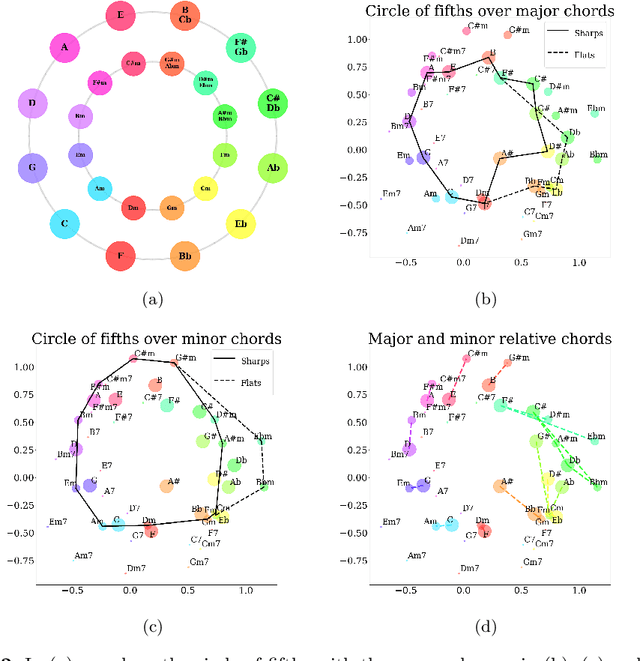
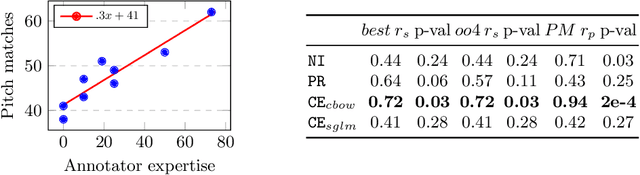
Natural language processing methods have been applied in a variety of music studies, drawing the connection between music and language. In this paper, we expand those approaches by investigating \textit{chord embeddings}, which we apply in two case studies to address two key questions: (1) what musical information do chord embeddings capture?; and (2) how might musical applications benefit from them? In our analysis, we show that they capture similarities between chords that adhere to important relationships described in music theory. In the first case study, we demonstrate that using chord embeddings in a next chord prediction task yields predictions that more closely match those by experienced musicians. In the second case study, we show the potential benefits of using the representations in tasks related to musical stylometrics.
* 16 pages, accepted to EvoMUSART